上一篇介绍REALM的文章对文中提到的Maximum Inner Product Search没有作充分的介绍。发出去的标题已经没法改了,这篇文章介绍一下MIPS和最近邻搜索问题,以及两个相关的算法。
问题定义
MIPS的定义很简单,假设你有一堆d维向量,组成集合X,现在输入了一个同样维度的查询向量q(query),请从X中找出一个p,使得p和q的点积在集合X是最大的。用公式写出来就是
$$p=\mathop{\arg\max}_{x \in X}x^Tq$$
这个问题和最近邻问题很像,最近邻问题只要把上面的定义改成找一个p使得p和q的距离最小,假设这个距离是欧氏距离,则
$$p = \mathop{\arg\min}_{x \in X}\left |q-x\right|^2=(\left | x \right |^2 – 2q^Tx)$$
如果X中的向量模长都一样,那两个问题其实是等价的。然而在很多实际场景例如BERT编码后的句向量、推荐系统里的各种Embedding等,这个约束是不满足的。
最近邻搜索其实应用非常广泛,如图片检索、推荐系统、问答等等。以问答匹配为例,虽然我们可以用BERT这样的大型模型获得很好的准确度,但如果用BERT直接对语料库中的所有问题进行计算,将耗费大量的时间。所以可以先用关键词检索或者向量检索从语料库里召回一些候选语料后再做高精度匹配。
朴素的算法
对于MIPS问题,一个直观的蛮力算法就是计算出所有相关的内积,然后将内积排序,找到最大的那个。对于最近邻问题其实也类似,即使X中向量模长各不相同,也可以提前计算出来,并不会增加排序的时间复杂度。
内积的计算可以转换成一个矩阵乘法,在CPU和GPU上都有大量的高效实现。当X中有N个向量时,时间复杂度是O(Nd),当N不大的时候是可以接受的,但是通常在工业界的大规模系统中,X的规模往往很大,朴素算法就显得力不从心。
Locality-sensitive hashing
对于某些距离度量(例如欧式距离,cosine距离)下的最近邻问题,可以使用LSH算法来解决。LSH的思路就像下图示意的那样,用hash函数把高维空间的点分到几个桶里去,从而减少距离的计算量。
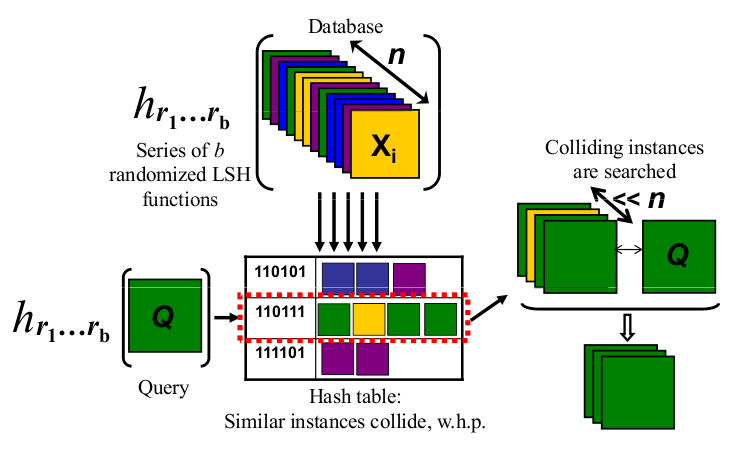
跟普通的哈希函数不同,这个哈希函数是Locality-sensitive的。具体地说就是它有一个神奇的特点:在空间中离得近的点被分到同一个桶的概率大,离得远的点则大概率被分到不同的桶里去。或者说对于两个点x和y,他们被哈希函数分到同一个桶的概率随着距离的增大单调递减。
这样在查询的时候,只需要精确地比较和查询向量q处在同一个桶里的那些x。如果桶足够多,那便可以将N大大降低,从而提高查询速度。但需要注意的是,LSH是一个近似算法,有可能产生桶内的向量其实都不是最优解的情况,不同哈希函数发生这种情况的概率都不一样,也是作为评价哈希函数好坏的重要依据之一,对这部分感兴趣的朋友可以读参考文献。
下面举一个具体的例子来解释一下LSH。假设某个最近邻问题考虑的距离度量是cosine距离,有一个满足要求的LSH函数(变换),称为Random Projection。
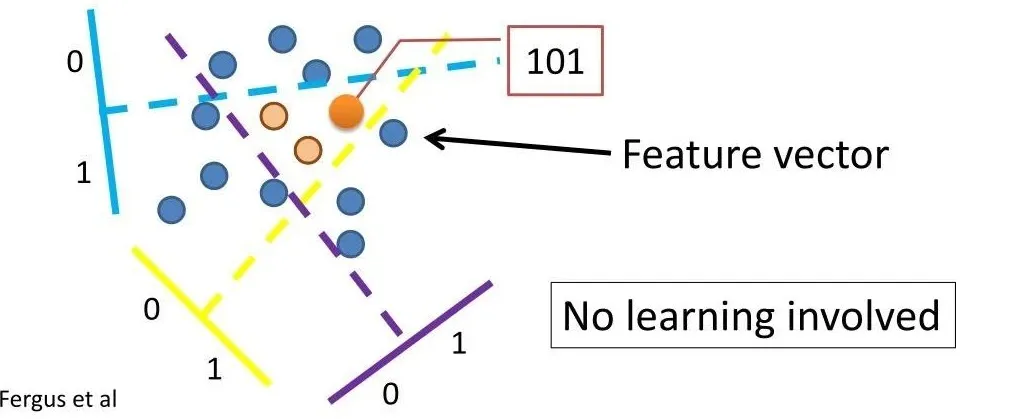
如上图所示,其过程很好理解:
- 随机取一个空间中的超平面将空间分为两半,X内位于某一半的点标为0,其他标为1;
- 重复第一步K次。
完成之后,X中的每个点便得到了一个由K个0,1组成的表示(signature)。例如重复了K=32次,那每个点都被分到了一个用一个int32类型的整数编号的桶里。如果这些点在空间中分布足够均匀,那么我们将可以期望每个桶里只有N/2^K个点,当K~logN,则查询的时间复杂度就约为O(dlogN)。整个过程构建出了一张哈希表,由于LSH可能会错过最优解,一个可行的增强鲁棒性的做法是用同样的方法多构造几张哈希表,借助随机的力量来降低犯错的概率。这里有一个讲解LSH的视频,可谓短小精悍,直观易懂,推荐给大家。
LSH看上去相对于朴素算法确实前进了一大步。但别高兴得太早,要达到O(dlogN)的效果必须服从那个很强的假设。而点在空间中分布足够均匀往往是不太现实的。除此之外,一个LSH只能适用于某些距离度量,对于MIPS,找不到符合要求的LSH。
Asymmetric LSH(ALSH)
论文里证明了找不到可用于MIPS问题的LSH函数,但他们发现对LSH稍作点改动即可将MIPS问题转变为欧式距离下的最近邻搜索问题。改动的关键就在于Asymmetric这个词。在LSH算法中,对查询向量q和X中的向量做的是同样(对称) 的变换,而在ALSH中作者对两者使用了 不同(非对称) 的变换。简单起见,假设查询向量q的模长是1。对于X,先做一个放缩变换使得X中所有向量x的所有元素都小于1。然后对X中的向量进行变换P(x),对查询向量q做变换Q(x),P和Q的定义如下:
$$P(x) = [x; \left | x \right |_2^{2^1}; \left | x \right |_2^{2^2},…,\left | x \right |_2^{2^m}]\ Q(x) = [x;\frac{1}{2};\frac{1}{2},…,\frac{1}{2}]$$
可以发现,P和Q虽然变换不同,但都会使输入向量增加m维。进一步观察可以得到
$$Q(q)^TP(x)=q^Tx+\frac{1}{2}(\left | x \right |_2^{2^1}+ \left | x \right |_2^{2^2}]+…+\left | x \right |_2^{2^m})\ \left | P(x) \right |_2^2=\left | x \right |_2^{2^1}+ \left | x \right |_2^{2^2}]+…+\left | x \right |_2^{2^{m+1}}$$
继而推导出下面这个关键的公式
$$\left | P(x)-Q(q) \right |_2^2=(1+m/4)-2q^Tx+\left | x \right |_2^{2^{m+1}}$$
上式右边的第一项是个常数,第三项由于x的每个值都小于1,所以是随着m的增大以指数的指数的速度趋近于0,因此也就剩下了第二项。第二项包含了我们要求的内积项,而求最大内积就是求最小距离,原问题便转化成了P(x)和Q(q)间的欧氏距离最近邻搜索问题。而P(x)和Q(q)仍然是向量,在欧氏距离下是能够找到LSH函数快速求出最近邻问题的近似解的。
上面就是ALSH的主要过程,它的核心技巧是通过“非对称变换”构造向量从而消除x向量模长对MIPS结果的影响。前面为了简单起见引入了一个查询向量q必须是单位向量的约束,论文中介绍了怎么进一步加强这个变换来消除这个约束,在此就不赘述了。
后记
LSH和ALSH的理论证明部分比较复杂,本文可能会有错误的地方。除了本文介绍的LSH及其变种,在解决向量检索问题上还有很多有趣的算法和厉害的算法包,我们会在后续的文章中继续介绍。在今年一月份的时候Google发了一篇叫《Reformer: The Efficient Transformer》的文章,就用到了LSH的算法,近期我们可能也会乘热打铁介绍一下这篇文章。