在著名的科幻电影《银河系漫游指南》里有一种叫巴别鱼的神奇生物。将它塞进耳朵里你就能听懂任何语言。多语种语言模型做得事情和巴别鱼很像,人们希望这个模型能用来处理所有的语言。举个例子,大家常用的中文bert有很强的中文处理能力以及一定的英文处理能力,但基本也就只能处理这两种语言;而目前的SOTA多语种模型XLM-RoBERTa能够处理104种语言。
巴别鱼,体型很小,黄色,外形像水蛭,很可能是宇宙中最奇异的事物。它靠接收脑电波的能量为生,并且不是从其携带者身上接收,而是从周围的人身上。它从这些脑电波能量中吸收所有未被人察觉的精神频率,转化成营养。然后它向携带者的思想中排泄一种由被察觉到的精神频率和大脑语言中枢提供的神经信号混合而成的心灵感应矩阵。所有这些过程的实际效果就是,如果你把一条巴别鱼塞进耳朵,你就能立刻理解以任何形式的语言对你说的任何事情。

数据集
训练跨语种语言模型会用到两种语料。一种是单语种(monolingual)语料,另一种是平行(parallel)语料。所谓平行语料就是源语言与译文“对齐”的语料。所谓对齐也有好几种级别,最常见的是句子级对齐,也有按词进行对齐的文本。可想而知,平行语料的获取相比于单语种语料要困难许多。如何充分借助单语种语料来提升模型能力是XLM研究的一个重点。
跨语种语言模型的评价一般有两个大方向,一个是其语义理解能力,另一个是文本生成能力。语义理解能力通常借助XNLI数据集,它提供了15种语言的平行文本,每种语言7500对的NLI语料。文本生成通常用翻译任务来评估,感兴趣的朋友可以自己查阅相关资料。
模型
下表列出了常见的单语种和多语种预训练语言模型。接下来我们将分析其中的mBERT、XLM和XLM-R三个模型。
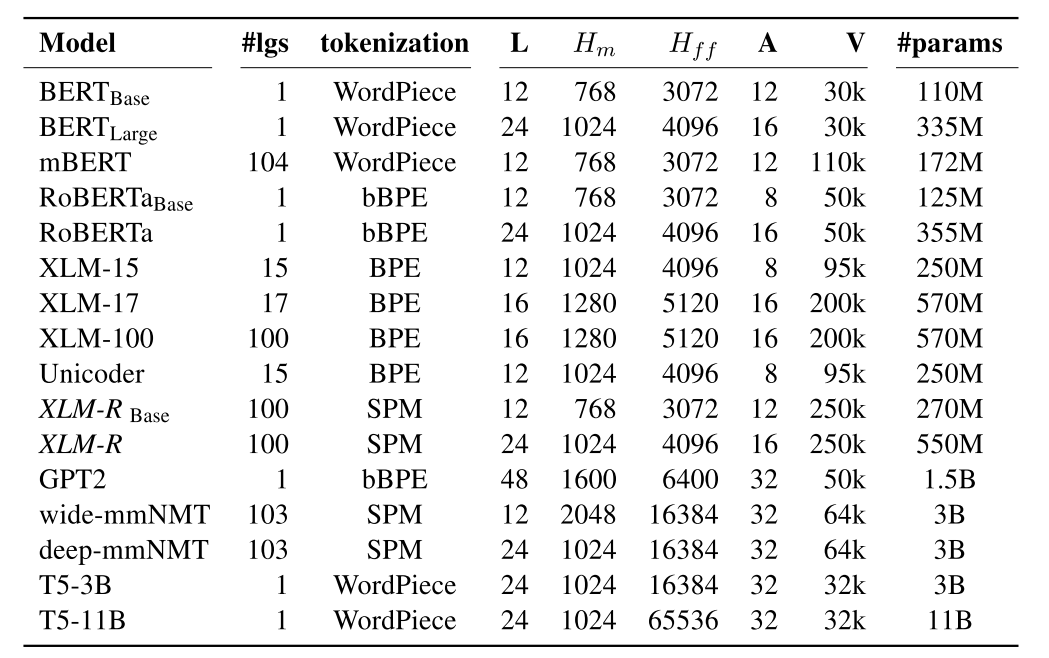
Multilingual Bert(mBERT)
模型来自于这论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,你没有看错,就是发表于2018年大名鼎鼎的BERT论文。
2018年11谷歌就放出了支持104种语言的多语种版本预训练模型,规格是BERT base。这个模型的较新版本是uncased版,即没有对输入文本进行规范化。使用WordPiece算法进行tokenization,词典大小是110k。其他的训练方法和普通的BERT一样,采用的是MLM和NSP两个loss,语料是Wikipedia。
XLM
模型来自于论文《Cross-lingual lan- guage model pretraining》,来自于FAIR,发表在NIPS2019。
XLM使用BPE算法进行tokenization,并且词典大小比mBERT更大,达到200k。论文指出Shared sub-word vocabulary对模型性能有很大的影响,在训练BPE算法的过程中他们使用了特殊的采样方式来避免低资源语种被进行字符集切分。
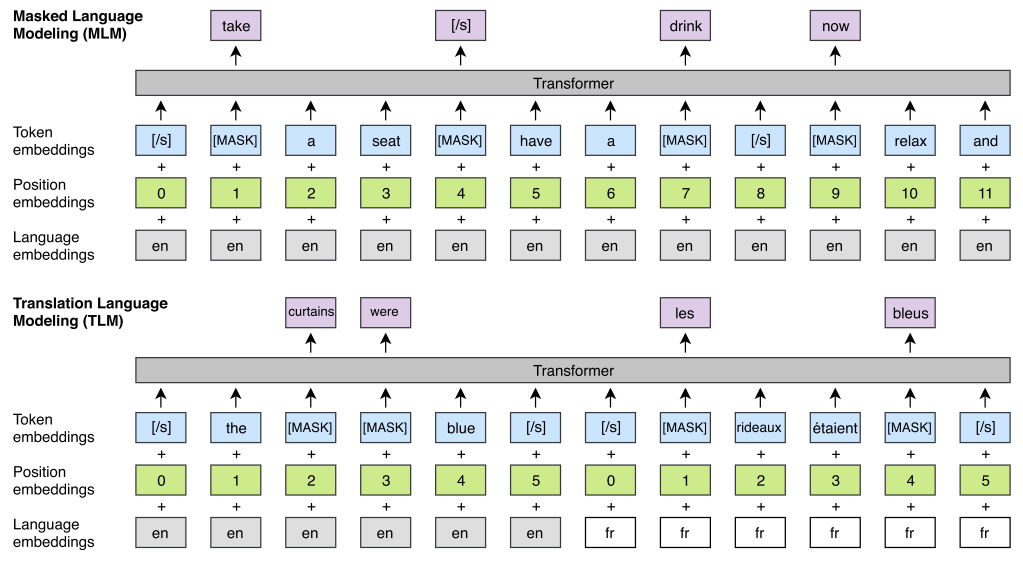
模型训练使用了三种不同的目标函数,在单语种语料上使用非监督的CLM和MLM。MLM就是masked language modeling,大家比较熟悉,在此就不再赘述了。CLM全称是Causal Language Modeling,简单的说就是用前面的词预测当前词,更详细的介绍大家可以参考我们之前UniLM和MASS的文章。在平行语料上使用的目标称为Translation Language Modeling (TLM)。其训练方式如下图所示,是将平行句子拼接后随机mask,希望让模型能借助另一种语言的信息来还原出被遮蔽的词。从图中可以看出模型用language embedding替换了BERT里的type embedding,并且在做TLM任务时position embedding在两个语言间是对应的。
我们来看一下XLM在XNLI上的表现。这张表很有意思,首先对这个数据集有3种处理方式:translate-train,translate-test和直接测试,即zeroshot。第一种是把英语的MNLI数据集机器翻译成XNLI内的15种语言用于训练,在XNLI测试集上测试;第二种是把XNLI测试集的15种语言翻译成英文。本文的对照组就是上面的mBERT。
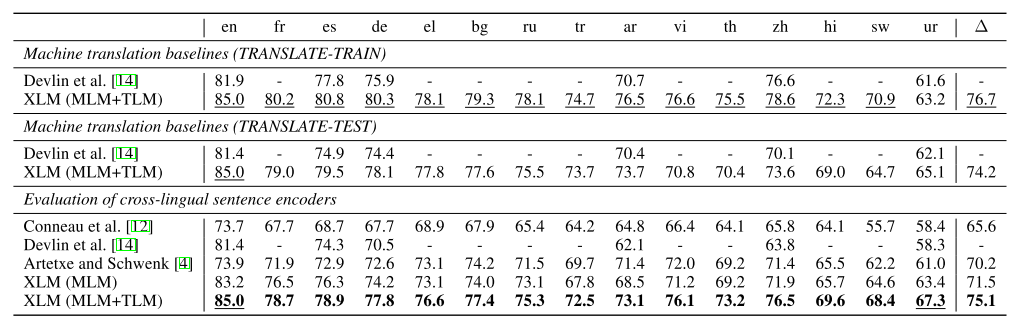
可以看到效果最好的是翻译训练集,平均精度达到了76.7%,zero-shot次之,最差的是翻译测试集。在相同的实验设定下XLM稳定优于mBERT,甚至在zero-shot下的XLM也比finetune过的mBERT强。另外MLM+TLM也稳定优于只用MLM的方式。
XLM-RoBERTa
模型来自于论文《Unsupervised Cross-lingual Representation Learning at Scale》,和上文一样来自FAIR,已经被ACL 2020接收。
XLM-R使用了比XLM更大的词典,达到了250k。它也没有辜负RoBERTa的血统,使用了比Wikipedia大得多的cc100数据集。XLM-R只使用单语种语料,训练目标也只有MLM一个。
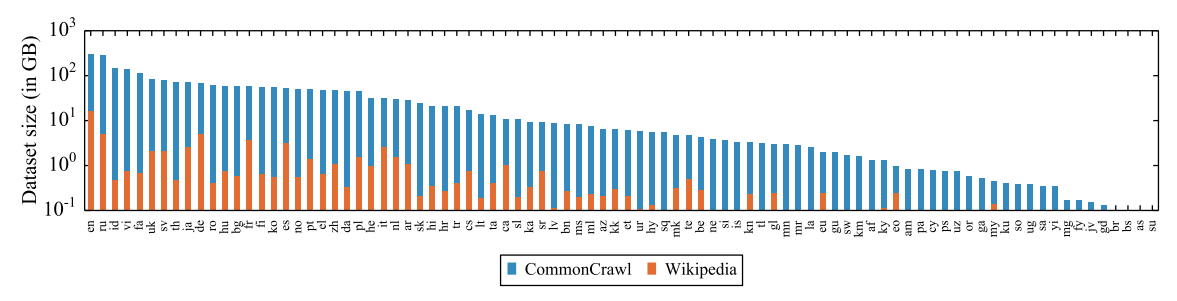
Tokenizer换成了sentence piece算法,在构建时也进行了采样,并且调整了系数使得各语言更加平衡。模型层面去掉了language embedding,变得更加简洁。我感觉用“重剑无锋”来形容XLM-R再合适不过了。
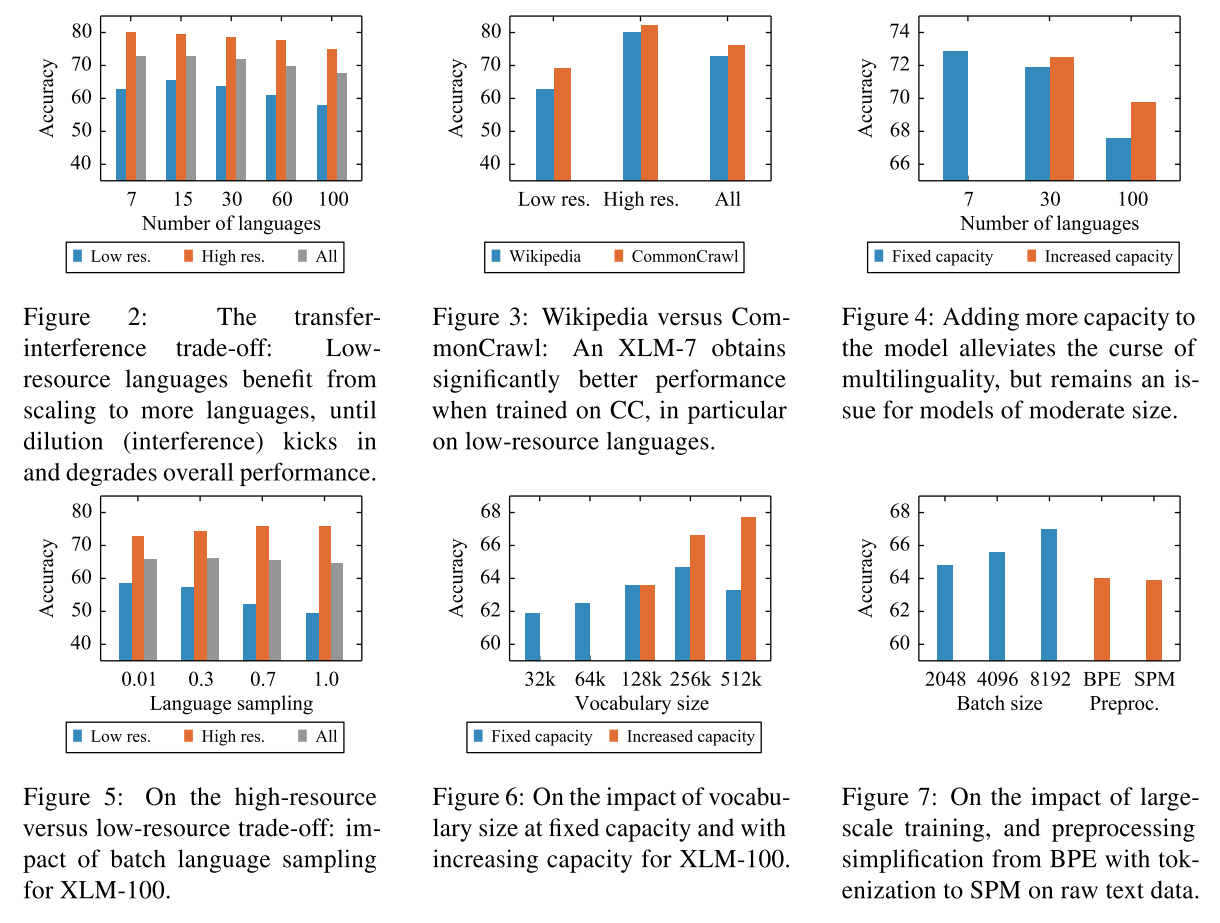
这篇论文总结了几个影响多语种模型的重要因素,可能会对大家有所启发:
- 当处理的语种变多的时候模型的能力会下降(嗯,符合常识)。增大模型可以一定程度对抗这种效应。
- 模型能力主要受词典大小、训练集大小、语种的采样频率影响
- 增大词典规模可以提高模型性能
- sentence piece可以提高模型的通用性
下面这种图可以让大家对这些结论有更直观的印象
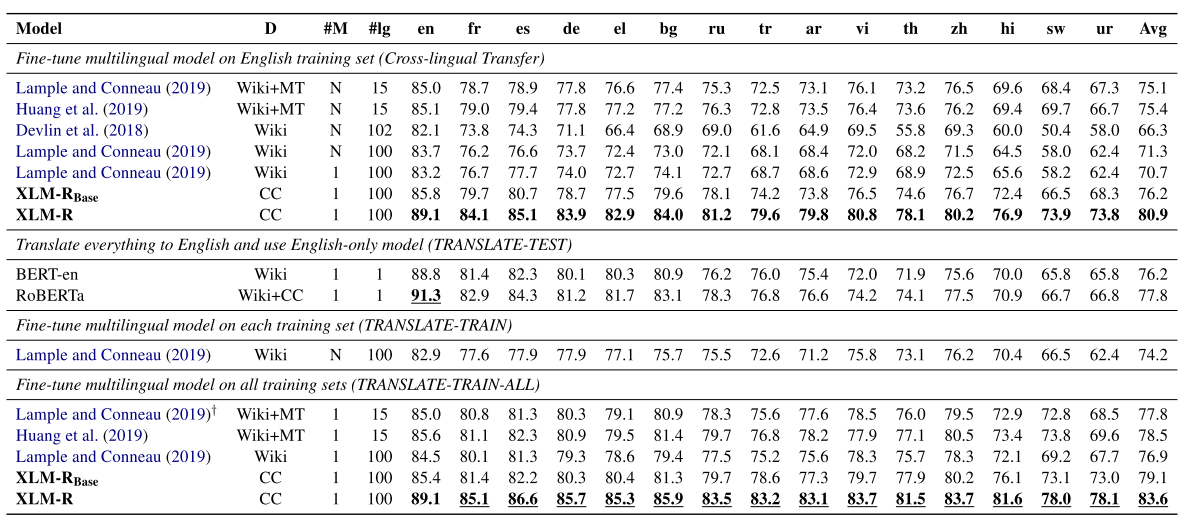
最后来看一下XLM-RoBERTa的实力。下表是在XNLI数据集上的结果对比,设定和XLM论文中差不多,其中Devlin et al.指的是mBERT,Lample and Conneau指的是XLM。可以看出XLM-R相比于XLM又前进了一大步。
顺便再提一嘴,论文作者还在GLUE数据集上对比了XLM-R和XLNET、RoBERTa等单语种语言模型,XLM-R超过了BERT-large,略低于XLNET和RoBERTa。也就是说XLM-R不仅获得了多语种能力,而且没有牺牲英文上的水平。
总结一下,从2018年的mBERT到2020年的XLM-R,跨语种预训练语言模型获得了长足的发展,地球语言范围内的巴别鱼指日可待。最近在Kaggle上正在进行一场跨语种文本分类的比赛,如果有想体验XLM最新进展的朋友可以去试试身手。

今天的文章就到这里,下期再见👋