最近Transformer结构在计算机视觉领域的应用非常火,时不时都有新的文章出来。作为一个已经使用了两三年Transformer结构的NLPer,一直很想了解一下它在视觉领域是怎么工作的,最近借着一个Kaggle比赛的数据集学习了一下,稍作总结分享给大家。
首先是学习了一下Vision Transformer,ViT的原理。看的论文是谷歌名作《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》,本文初稿发布于2020年10月,今年投了ICLR 2021,应该算是ViT的奠基论文之一。要用Transformer来处理图像,首先(也可能是唯一)要解决的是输入问题,原先的Transformer处理的是token序列,而图像是HWC的像素矩阵。这里做法也很暴力,第一步是将一张图拆成了N个PP个小块(patch),每个patch看做是一个token。一个patch里有PP个像素,每个像素C个通道,这里直接就给拍平了进一个全连接(线性变换)得到patch的D维Embedding表示。所以ViT里的Embedding层不再是一个lookup table了,而是一个可以学习的线性变换。
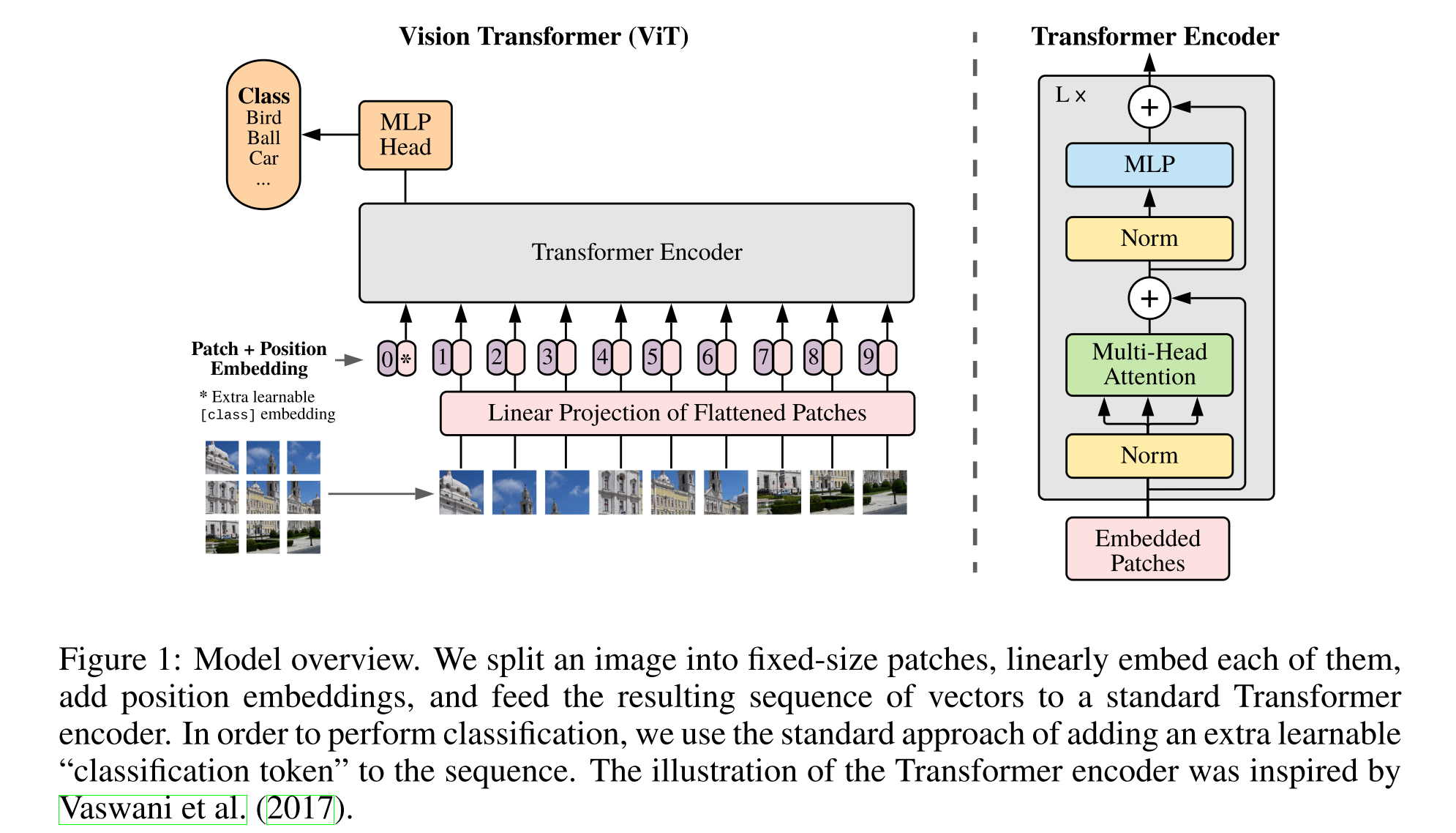 ViT结构图
{: .align-caption style=“text-align:center;font-size:smaller”}
ViT结构图
{: .align-caption style=“text-align:center;font-size:smaller”}
通过这个方法,就把Transformer结构套在了图像上,虽然这不是唯一的方法,但这么做在参数量的角度和时间复杂度的角度都是比较合理的。首先是时间复杂度角度,Transformer的关于序列长度的时间复杂度是O(n^2),所以输入序列不宜过长。如文题所说,如果我们把图分成1616个patch,那transformer处理的序列长度将会是256,比BERT的默认长度521还短了一半。参数量上,尺寸正常的Transformer很大比例参数在embedding层上,例如BERT-base的30k个token768维的Embedding层有23M参数大约占了其110M总参数量的五分之一。ViT里Embedding层的参数量是正比于图像尺寸的,以224224图像为例,单patch像素点数为196,所以总参数量是196C*D,C是输入通道数,D是Embedding维数,以3和768记的话为0.45M,远小于BERT-base。从下表可以看到同样尺寸的ViT参数量都小于对应的BERT。
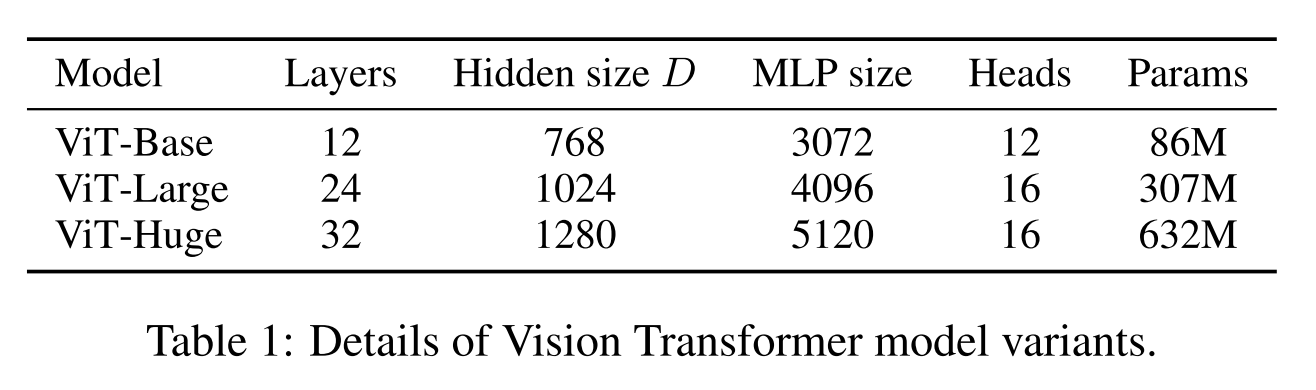
按论文的这种处理方式也有几个比较明显的问题,例如强行分割patch破坏了原有的邻域结构,也不再具有卷积的那种空间不变性。在中等规模数据集上用这种方法得到的结果还是比卷积要差,但是当把预训练数据变多用更大的数据集训练时,模型性能显著提升了(第二列比第三列),接近甚至超过了SOTA。
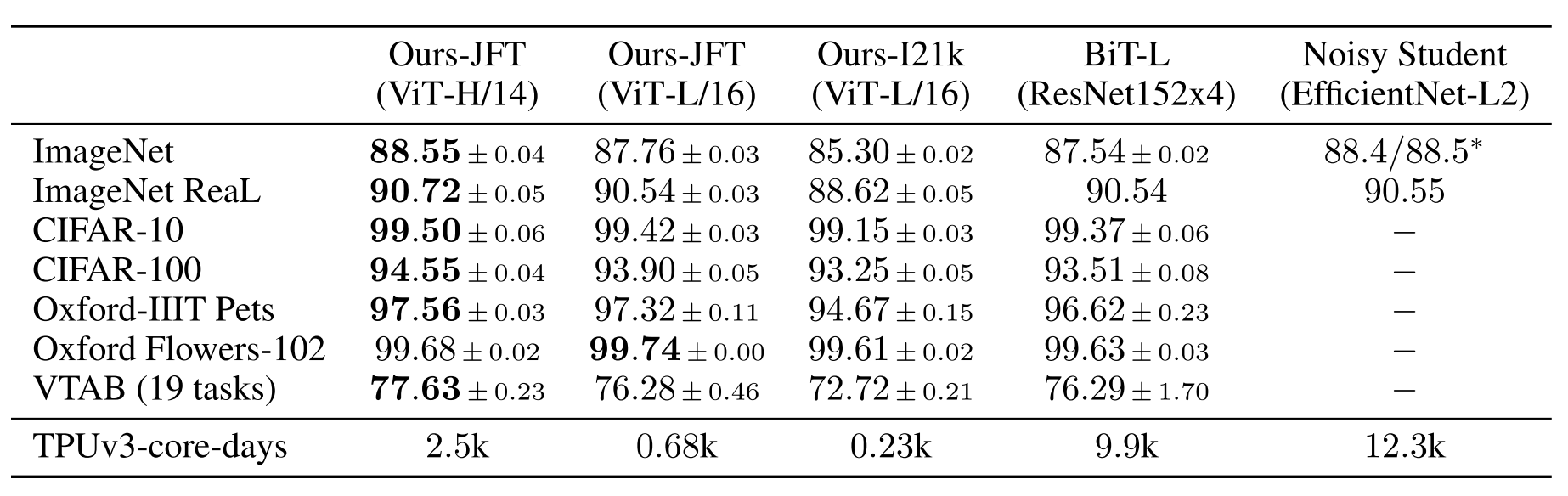
上面的结果都是针对有监督训练的,这篇文章还做了些无监督训练的初步实验,发现加入无监督预训练在下游任务比没有预训练强一2%,但是比有监督预训练差4%,总之一句话,没有实现BERT的效果。
实验的部分用Pytorch Lightning简单做了一下Kaggle的Pawpularity数据集。这是一个值域0-100的回归问题,评价指标是RMSE。模型部分没什么花头,直接backbone接了个回归头,代码如下
class Pawpularity(pl.LightningModule):
def __init__(self, config):
super().__init__()
self.config = config
self.backbone = timm.create_model(config.backbone_name,
pretrained=not config.predict,
num_classes=0)
self.head = nn.Sequential(
nn.Linear(self.backbone.num_features, 128),
nn.GELU(),
nn.Linear(128, 1)
)
self.save_hyperparameters(config)
实验的运行环境是在我的HP Z4工作站上,它搭载了两个RTX 6000 GPU,因为显存是24GB版本,所以batchsize设的比较大。实验结果如下
| 模型 | 模型参数 | lr | batch size | 单轮耗时 | 早停轮次 | RMSE |
|---|---|---|---|---|---|---|
| vit_base_patch16_224 | 85.9M | 1e-3 | 128 | 36s | 10 | 20.514 |
| vit_base_patch16_224_in21k | 85.9M | 1e-3 | 128 | 36s | 10 | 20.512 |
| swin_base_patch4_window7_224_in22k | 86.9M | 2e-5 | 64 | 64s | 20 | 19.61 |
| efficientnet-v3 | 10.9M | 1e-3 | 64 | 27s | 4 | 19.825 |
从结果可以看出,似乎是efficientnet更加适合这个任务,在各方面都优于ViT,大数据集预训练的ViT优势也不明显。当然,这个结果虽然公平,但仅供参考,因为没有对超参进行针对性的调优。
第一回合ViT没有表现出BERT那种出道即巅峰的霸气,但表中第三行的swin transformer似乎还不错,这也是之前各种屠榜的模型,后面准备重点学习一下。