上篇总结了一下最初的ViT模型,它有几个明显的问题:
- 建模能力方面,强行分割patch破坏了原有的邻域结构,也不再具有卷积的那种空间不变性
- 复杂度方面,之前的ViT是在每层都做全局(global)自注意力。如果保持每个Patch的大小不变,随着图片尺寸的变大,Patch的个数会增加,而Patch的个数等于进入Transformer的Token个数,且Transformer的时间复杂度是O(n^2)。
- 易用性方面,由于Embedding(结构是全连接)和图片大小是绑定的,所以预训练、精调和推理使用的图片必须是完全同等的尺寸。
Swin Transformer提出了一种称为shifted window的方法来解决(缓解)以上问题。
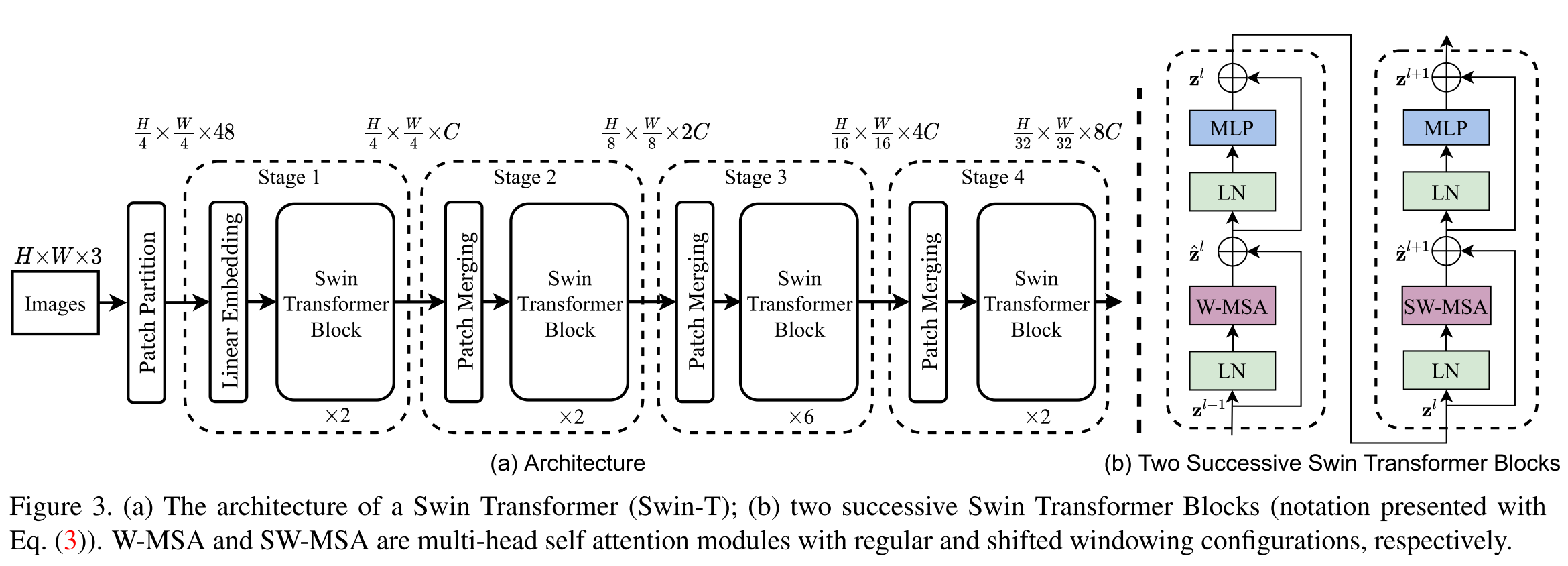
Swin Transformer的结构如下图所示
 {: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-caption style=“text-align:center;font-size:smaller”}
- Embedding Stage(stage1)。将图片划分为若干
4*4的patch,使用线性变换来将patch变为Embedding向量,这一步和ViT是一样的。但是注意,这里的patch比ViT的14*14小了很多。 - 若干个使用Swin Transformer 的Stage(stage2-4)。这里模仿了经典卷积网络backbone的结构,在每个Stage都将feature map(对应到Vit就是Patch或Token的个数)变成原来的四分之一。这是通过简单地将
2*2patch合并成一个来完成的。同时,用Swin Transformer替代了原来的标准Transformer,主要变化如下- 用M*M大小的窗口自注意力代替全局自注意力。因为自注意力机制时间复杂度是O(n^2),通过减少参加自注意力的元素,将原来关于patch数平方复杂度的计算变为关于patch数线性复杂度
- 用对角线方向的shift来使Swin Transformer里的每一层窗口都是不同的,这样一个patch有机会和不同的patch交互。这里还使用了一个mask trick来使得这种shift的自注意力计算更高效。
- 添加了相对位置偏置(relative position bias),对比发现这比添加绝对位置embedding效果好很多
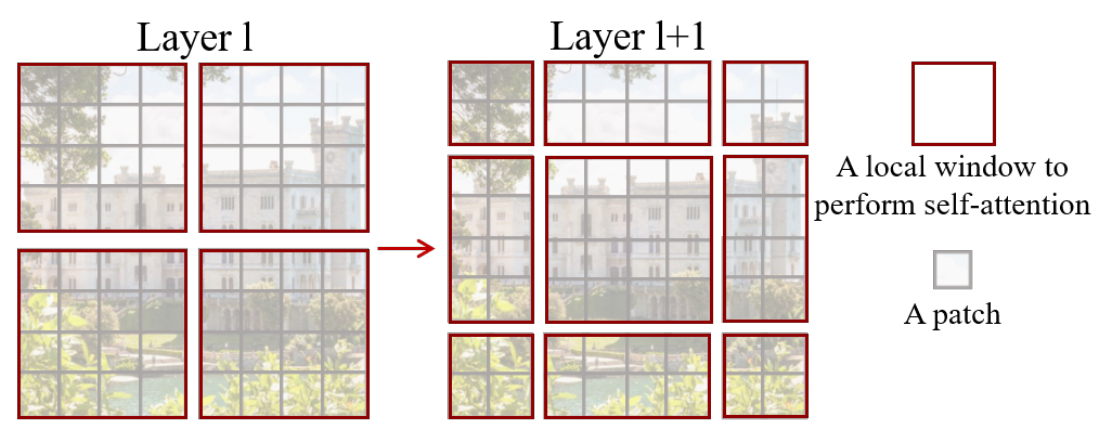 shifted window示意图,l+1层的窗口是从l层往右下角平移2个patch得到的
{: .align-caption style=“text-align:center;font-size:smaller”}
shifted window示意图,l+1层的窗口是从l层往右下角平移2个patch得到的
{: .align-caption style=“text-align:center;font-size:smaller”}
从结果来看,SwinT相比于ViT有了很大的提升
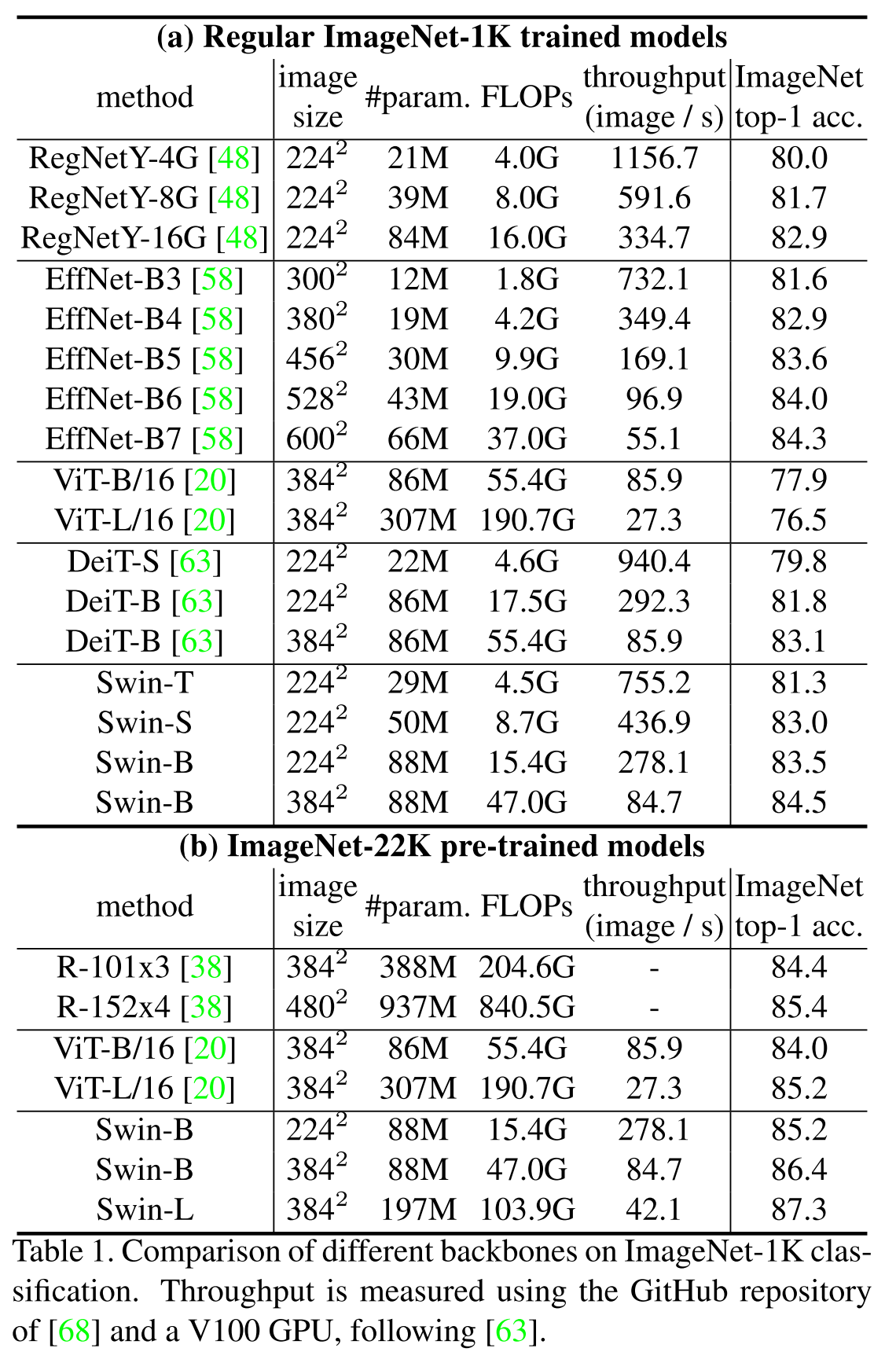 Swin Transformer实验结果,可以看出来比ViT已经有了很大的提升
{: .align-caption style=“text-align:center;font-size:smaller”}
Swin Transformer实验结果,可以看出来比ViT已经有了很大的提升
{: .align-caption style=“text-align:center;font-size:smaller”}
综合消融实验的结果可以对比三种不同的attention方式: fixed window、sliding window和shifted window的性能。他们的imagenet top1 acc分别是80.2, 81.4和81.3。从中可以看出类似于卷积的sliding window性能是最好的,无奈太慢了。fixed window丢失了很多有用的窗口间交互,性能最差。shifted window性能相比sliding window下降微弱,但速度提升了好几倍。同样可视为fixed window的ViT只能得到0.78的top1 acc,我想这是小patch带来的差别,因为现在的线性变换embedding实在太弱了,patch越大带来的信息丢失就越多。
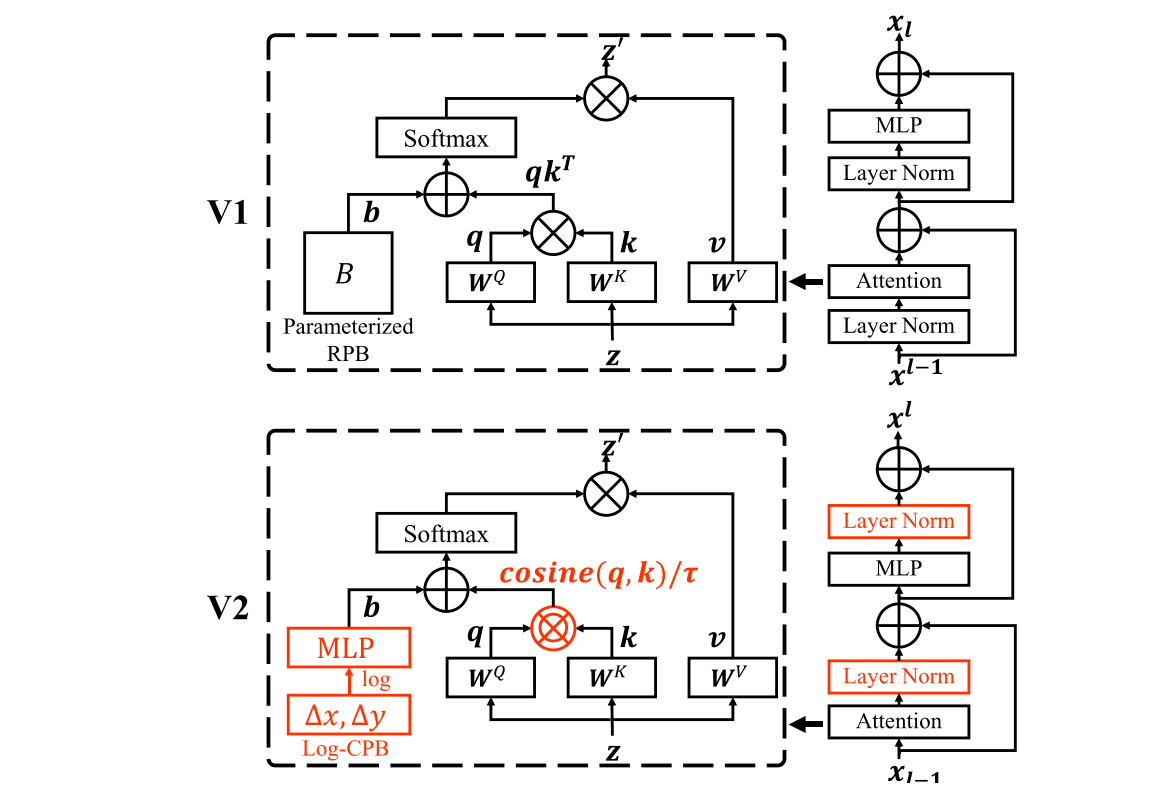
前不久原班人马又发布了V2版的Swin Transformer,主要是解决模型上规模的问题,有几个主要的改动:
- 把每个Block里的LN从前面换到了后面,来解决深度增加之后训练不稳定的问题
- 把原来的scaled dot attention换成了scaled cosine attention,也是为了解决训练不稳定的问题(否则可能被某些像素对的相似度主导)。
- 改进相对位置偏置。V1版里这个模块是用一个规模跟窗口大小M相关可学习参数矩阵来处理的,如果预训练和finetune时M大小改变,就用插值来生成原来不存在的值。V2版首先是引入了一个小网络来取代参数矩阵,其次是将相对位置从线性空间换到了对数空间,通过取对数压缩空间差距来让M变化时的过渡更加顺滑
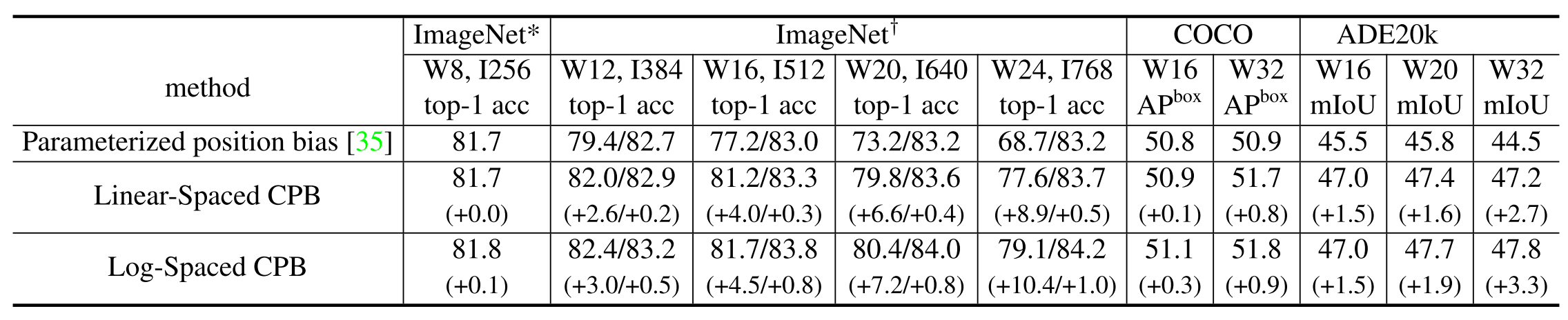 通过取对数,让finetune时增大窗口和图片的性能损失大为减小。但其实这里还是跟卷积神经网络有差距。通常卷积神经网络在finetune时使用更大的图片可以提升性能。
{: .align-caption style=“text-align:center;font-size:smaller”}
通过取对数,让finetune时增大窗口和图片的性能损失大为减小。但其实这里还是跟卷积神经网络有差距。通常卷积神经网络在finetune时使用更大的图片可以提升性能。
{: .align-caption style=“text-align:center;font-size:smaller”}
从结果来看,更大的网络确实带来了更好的性能,30亿参数版的SwinV2-G比8800万参数版的SwinV2-B性能提升了不少。同样参数量的V2版也比V1版提升了一些。
 不同模型Imagenet结果
{: .align-caption style=“text-align:center;font-size:smaller”}
不同模型Imagenet结果
{: .align-caption style=“text-align:center;font-size:smaller”}
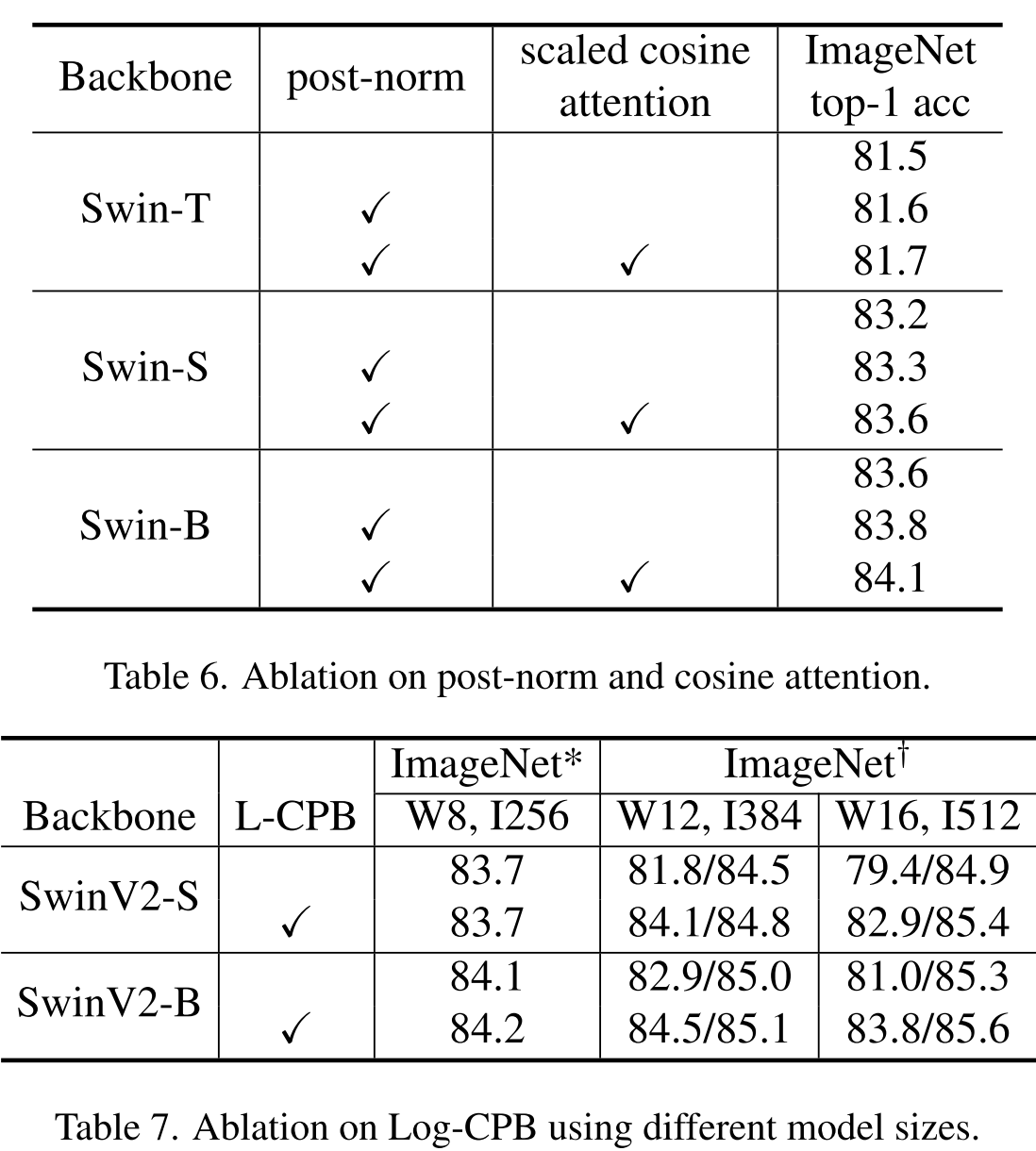
消融实验也比较清晰地反映出了V2版加入的新技术带来的技术提升
 消融实验结果
{: .align-caption style=“text-align:center;font-size:smaller”}
消融实验结果
{: .align-caption style=“text-align:center;font-size:smaller”}
最后,我想说一点自己的想法。这个ViT变种的核心应该是名字中的shifted window,但其初衷是为了降低全局attention带来的计算复杂度。然而比较明显的是全局attention正是Transformer(至少在NLP领域)相比于之前的CNN,RNN优秀的重要原因。而且shifted window这种操作看起来还是比较tricky。后面我想应该会有回归全局attention的网络出来,从其他地方去节省计算。