对比学习已经火了一阵了,之前看过一下SimCLR和SimCSE的论文,但走马观花也没有实践。这两天仔细学习了一下,大概明白了是怎么回事。
首先对比学习通常是在自监督的设定下进行表征学习,也就是不依赖标注数据获得一个编码器(Encoder),大致的环节如下
- 通过一些方式构造人工正样本对
- 在一个Batch内构造负样本对
- 设计一个loss,拉近正样本对表征(Embedding)间的距离,扩大负样本对表征间的距离
构造正样本对
对比学习一开始是在计算机视觉领域兴起的,CV论文里最初是通过对一张图片进行两次不同的数据增强来构造正样本对的。

SimCLR里用到的图像增强方法,可以看出来强度是比较高的,模型要学会图像间的关系不是那么容易
后来这把火烧到了NLP领域,最开始也是模仿CV的做法,通过例如删字词、换同义词等数据增强来构造。直到大名鼎鼎的SimCSE横空出世,提出了用两次不同的dropout来构造正样本对的方法,而且效果还特别好。这个方法的前提是在transformers里面每层都有dropout,但常见的卷积神经网络里面dropout往往都只在最后才有,所以并不能迁移到CV界;但最近ViT大火,应该也有人会试着使用这种方法。
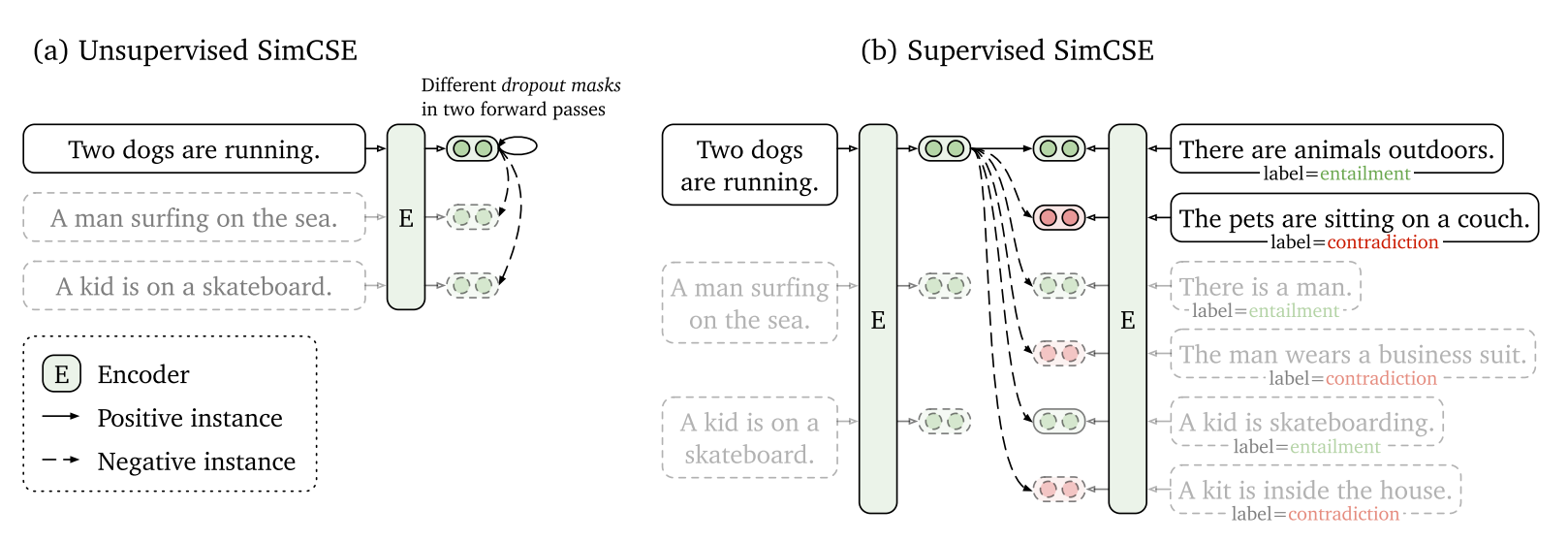
SimCSE除了有自监督的版本,还有通过数据集特点构造的有监督版本
损失函数构造
SimCLR里面用的是NT-Xent Loss,它是the normalized temperature-scaled cross entropy loss的缩写,我来翻译的话会叫他“归一化的带温度交叉熵”。其公式如下
$$l(i,j)=-\text{log}\frac{e^{\text{sim}(z_i,z_j)/\tau}}{\sum_{k=1}^{2N}1_{k\ne i}e^{\text{sim}(z_i, z_k)/\tau}}$$
$$L=\frac{1}{2N}\sum_{k=1}^N[l(2k-1,2k)+l(2k,2k-1)]$$
SimCLR中一个batch是由N张图片通过两组不同的增强变成2N张并且穿插排列,即2k-1 和 2k 是由同一张图构造的一对人造正样本。从第二个式子可以发现,一个Batch的Loss是其中N对loss的均值。跟cross entropy相比,首先是指数项从模型预测的概率变成了样本对间的相似度。分子与正样本对的相似度相关,分母则与第i张图与其余图的相似度有关。注意分母中只有2N-1项,因为自己与自己天然组成正样本,不去除的话这个分式的极限值(完美模型的loss值)将变成0.5,总loss也就不是0了。
SimCSE里使用的loss是上面的变种,或者说是个简化版本。$z_i$是原始第i个样本的表征,$z’_i$是对应的人造正样本的表征。与上面不同的是原始样本表征之间的相似度、变换样本表征之间的相似度都没有参与loss计算。
$$l(i)=-\text{log}\frac{e^{\text{sim}(z_i, z’i)}}{\sum^N{j=1}e^{\text{sim}(z_i, z’_j)}}$$
代码实现
下面是我实现的SimCSE版本的对比学习loss,供大家参考
class NTXentLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, rep1, rep2, temperature=0.5):
normalized_rep1 = F.normalize(rep1)
normalized_rep2 = F.normalize(rep2)
dis_matrix = torch.mm(normalized_rep1, normalized_rep2.T)/temperature
pos = torch.diag(dis_matrix)
dedominator = torch.sum(torch.exp(dis_matrix), dim=1)
loss = (torch.log(dedominator)-pos).mean()
return loss
实验心得
我还是在之前提到的Pawpularity数据集上进行的实验,并且和论文里的表征学习不同,我是将对比学习作为一个辅助任务来帮助主任务的训练。经过一天的实验,有以下一些发现
- 在参数合理的情况下,加入对比学习作为辅助任务确实可以提升主任务的表现。
- 加入对比学习作为辅助任务看上去可以让模型收敛更加稳健,从而可以使用更大的学习率、更高强度的数据增强。
- Loss中的温度是很重要的参数,在SimCLR论文中最好的温度是0.1,在SimCSE论文中最好的温度是0.05,但在我的实验里最好的值跟这俩差的很多。熟悉蒸馏的朋友应该知道,温度越高会让样本间的差异越小,loss趋近常数;温度越低则反之。SimCSE论文的消融实验尝试了不同数量级的温度,大家在用的时候也可以大胆地多尝试一下。
- 将对比学习作为辅助任务额外增加的时间代价不明显。
今天先到这里,上班去辽。