我经常在面试的时候问候选人如何构建一个文本配图系统,有不少人都会想到OpenAI的
CLIP (Contrastive Language–Image Pre-training) 模型。确实,CLIP的思路应该是解决这个问题的一个好框架,正好之前的几篇文章又都是关于其中的关键技术,于是这篇文章重温一下CLIP。
方法
自然语言信号
At the core of our approach is the idea of learning perception from supervision contained in natural language.
正如作者所说,这是CLIP的核心,但并不是一个新的方法。很多过去的研究都使用自然语言信号来训练图片编码器,但大家使用的方法各不一样。
用自然语言信号有几个好处,一个是数据收集容易了,有相关性的图文在互联网上很多,不需要标注,第二个是与之前那种类别空间相比,自然语言信号更容易迁移,后面还会具体讲到。
更大的数据集
CLIP构建了一个400 million 图片-文本对组成的数据集。比之前类似工作所使用的数据集大了二十几倍。而且这些数据集都是互联网上现成的,只是做了一些过滤来保证质量。
it is trained on a wide variety of images with a wide variety of natural language supervision that’s abundantly available on the internet
更大的模型
文本编码器使用的是12层8个头512个隐层神经元的Transformers模型,但没有使用预训练模型。我猜测这是因为要跟图像编码器交互,所以预训练可能帮助不大,如果使用预训练模型还需要特殊的策略来让图像和文本编码器的embedding空间匹配起来。
图像编码器尝试了resnet家族和ViT家族。最佳结果是来自于ViT,并且ViT相比于Resnet有更高的训练效率。图像编码器同样也没有使用Imagenet上的预训练权重来初始化。ViT我们在之前有两篇文章介绍,感兴趣的同学可以参考。
更高效的训练目标
过去的SOTA CV模型,如Noisy Student EfficientNet-L2,只训练Imagenet就需要耗费大量的训练时长(33个TPU年),如何能够在超大规模、自然语言信号的数据集上训练出一个好模型是个挑战。这部分也是CLIP最核心的地方。
This data is used to create the following proxy training task for CLIP: given an image, predict which out of a set of 32,768 randomly sampled text snippets, was actually paired with it in our dataset.
以往的多模态交互方法有不少,例如希望去用图片信息去重建caption,但由于文字空间的自由度太大,在文本token这个离散空间去构建训练任务的结果就是难度太大,噪音太多。CLIP作者发现对比学习是个好办法,做法如下图所示。训练目标不再是生成文本的逐字比对,而变成整个caption文本表征向量和图片表征向量的比较。
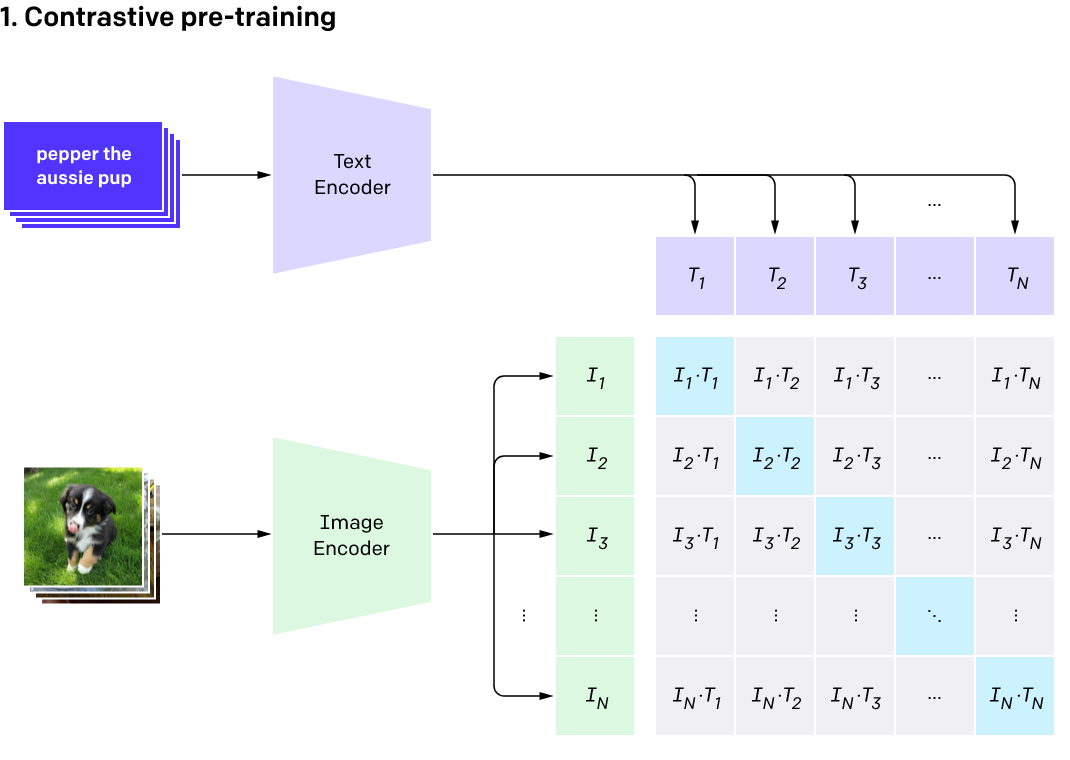
论文里有一个非常易于理解的训练伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
最终的效果也很好,蓝线是baseline即image encoder+transformers生成图片caption,黄线是将生成caption换成预测BoW,绿线是最终方案,直接在向量空间进行对比学习。每一次迭代都大大提高了模型的训练效率。

因为数据集够大,整个训练过程也没有任何花活,数据增强几乎没有,连原本对比学习里模型最后的非线性变换都去掉了。
Zero-shot迁移
这是不少科普公众号最容易“震惊”的点。
通过上面的方法训练出来的模型有很好的迁移能力,可以在一些没见过的图片上进行各种图像任务(主要是分类)。为了解决目标数据集文本标签和训练时不一致的问题,CLIP还使用了最近也非常时髦的PROMPT技术。以下图为例,如果希望CLIP识别飞机、汽车、狗和鸟,先用模板 a photo of a {object}来构建文本,再经过文本编码器获得文本embedding,与图像embedding进行比较,即可完成分类。
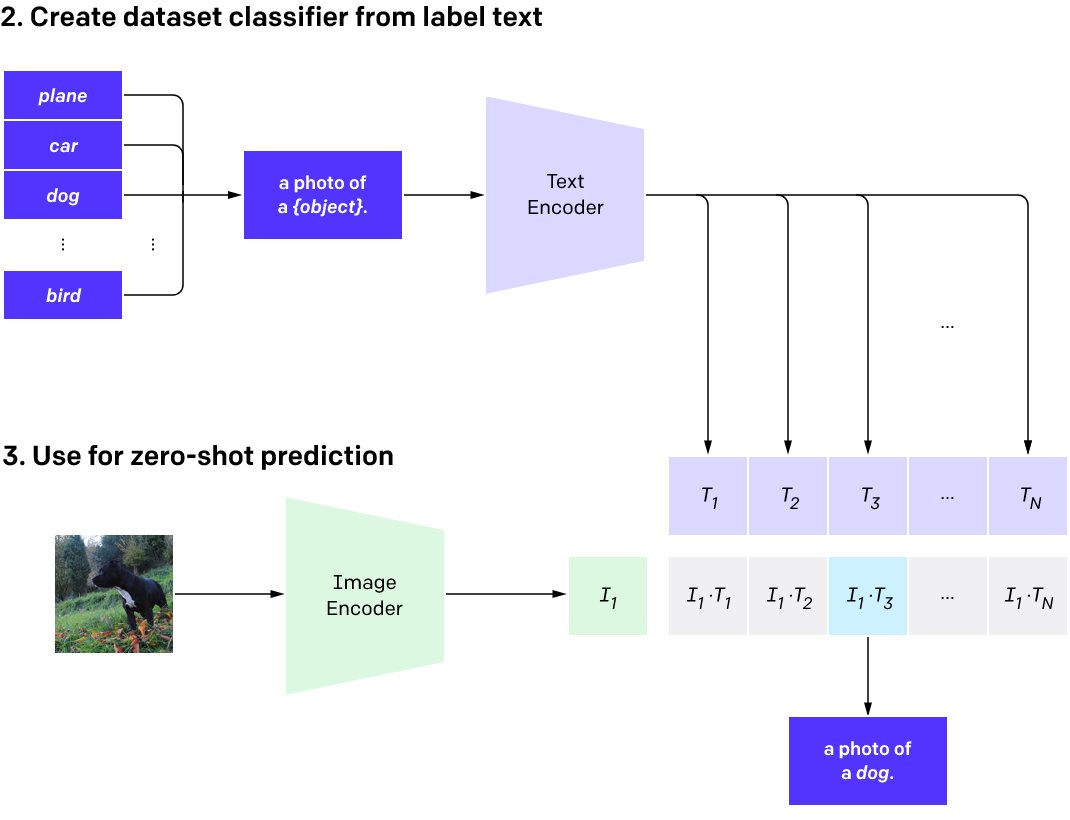
论文里提到,对于不同的目标任务可以通过构建不同的Prompt模板来提高迁移性能。
总结
整个CLIP模型给我的感觉是比较自然的,特别是在已经了解过对比学习的情况下,几乎没有什么特别新的概念和方法。但实际上要把两个模态的编码器整合到这个效果,对资源和执行力的要求是很高的。
主要解决了三个问题
- 数据集成本问题。这个显而易见,图文对在互联网上到处都是
- 应用范围。之前的做法是端到端的,用imagenet训练的模型只能预测imagenet里面的1000种类别。CLIP换成匹配之后理论上可以大大扩大使用范围。实际上如果新概念出现太快的话这些编码器还是需要重新训练的。Limitation部分也提到对于训练数据无法包含的概念,例如区分车的型号,CLIP的表现也一般。
- 在现实世界的表现差。大意就是原来端到端训练模型刷榜都是过拟合啦,CLIP过拟合的概率比较小,不会出现刷榜分数贼高,实际应用却很拉胯的情况。