最近大名鼎鼎的特斯拉AI总监Andrej Karpathy发了篇博客(看来写博客是个好习惯),叫Deep Neural Nets: 33 years ago and 33 years from now。饭后花了点时间围观了一下,写得确实挺有意思。
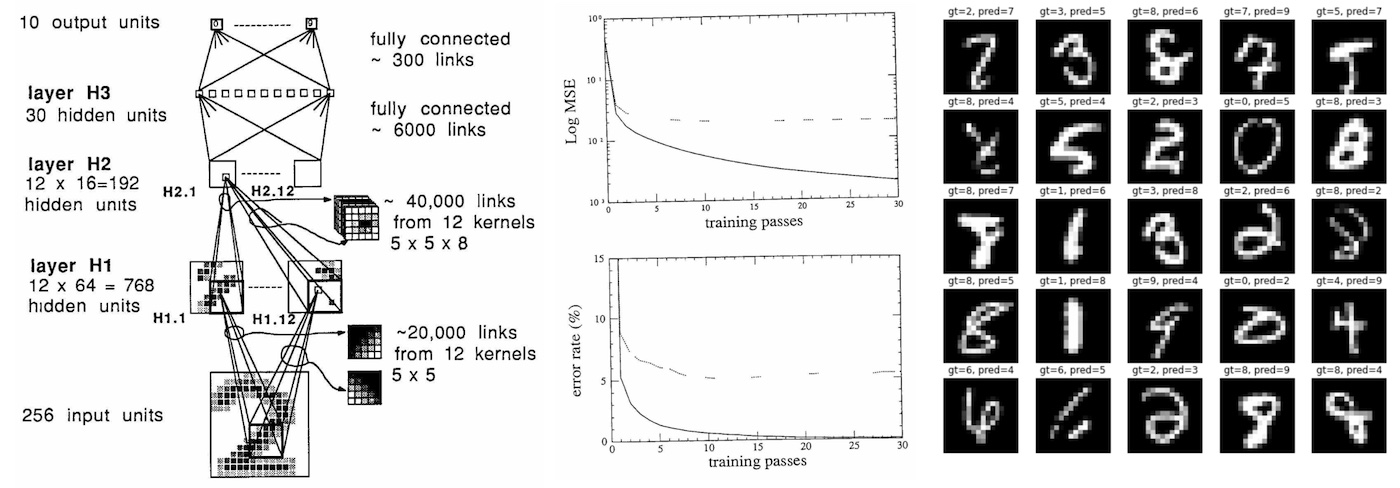
他先尝试复现了一下深度学习开山模型LeNet,然后尝试利用这33年人类的新知识去改进模型的效果。他干了这么几个事情:
- Baseline.
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45
eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
- 把原文的
MSE loss换成如今多分类的标配Cross Entropy Loss
eval: split train. loss 9.536698e-06. error 0.00%. misses: 0
eval: split test . loss 9.536698e-06. error 4.38%. misses: 87
- 首战失败,怀疑
SGD优化器不给力,换成了AdamW,并使用“大家都知道”的最优学习率3e-4,还加了点weight decay
eval: split train. loss 0.000000e+00. error 0.00%. misses: 0
eval: split test . loss 0.000000e+00. error 3.59%. misses: 72
- 尝到甜头,但发现train/test的差别仍很大,提示可能过拟合。遂略微添加数据增强。
eval: split train. loss 8.780676e-04. error 1.70%. misses: 123
eval: split test . loss 8.780676e-04. error 2.19%. misses: 43
- 感觉还有过拟合,遂增加
dropout,并把tanh激活函数换成了ReLU
eval: split train. loss 2.601336e-03. error 1.47%. misses: 106
eval: split test . loss 2.601336e-03. error 1.59%. misses: 32
通过一步一步加料,总监成功把33年前的错误率又降低了60%!这几步虽然常见,但也体现了总监扎实的基本功,试想还有几个总监能调得动模型呢。
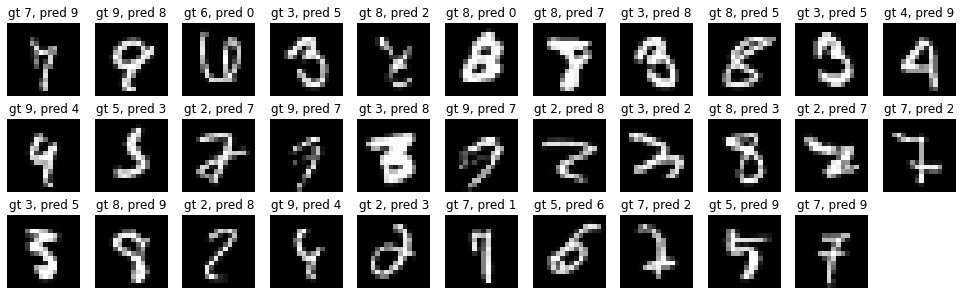
但他还不满意,又尝试了一些例如Vision Transformer之类更新潮酷炫的东西,但比较遗憾都没有再涨点了。最后从本源出发,增加了一些数据,错误率进一步降低,达到了1.25%。
eval: split train. loss 3.238392e-04. error 1.07%. misses: 31
eval: split test . loss 3.238392e-04. error 1.25%. misses: 24
观察上面的错例其实大家也能感受到有些错误应该是可以搞对的,此时增加数据确实是一个好办法。但更重要的是,希望大家也能养成总监一样把结果可视化出来检视的好习惯!
最后总监总结了一下以2022年的未来人身份把玩33年前数据集的感受
- 做的事情内核并没有变,还是可微分的神经网络、优化那一套
- 当时的数据集好小(a baby)啊,MNIST只有7000多张,CLIP训练图片有400百万张,而且每张图的分辨率都大得多
- 当时网络好小啊
- 当时的训练好慢啊,7000多张图+这么小的网络要跑3天,现在总监的Macbook可以90s训练完
- 该领域还是有进步的,可以用现在的技巧使错误率下降60%
- 单纯增大数据集效果不大,还得配上各种技巧才能驾驭
- 再往前走得靠大模型了,就得大算力
最后的最后总监展望了一下再过33年那时的人们会怎么看今天的深度学习
- 除了规模更大,宏观上网络估计还像今天这样
- 模型肯定会比现在大超级多
- 那时训练现在的大网络估计也只要一两分钟
- 一些细节知识还是会进步的
- 数据集肯定会变得更大
- 计算基础设施估计得变了
最最最后,总监说往后训基础模型,甚至模型,的人都会变少了,到2055年估计大家可以用自然语言教模型干一些事情了。
好,围观结束,祝大家晚安。