做了一段时间的新闻NLP,越来越感受到抓重点对长文本理解的重要性。类别、话题、关键词句这种离散标签对下游的推荐、搜索业务以及产品的形态都有很重大的影响。最近读了两篇关键短语抽取(Key Phrase Extraction,KPE)相关的论文,感觉挺有意思,跟大家分享一下。
问题定义和数据集
首先,对于一篇文章来说什么是其中的关键短语就没有一个统一的标准,标注的时候也比较主观,而且标注难度很大。常见的类别体系可能包含几百个类别,话题体系包含成千上万个话题,而对于关键短语来说,连个确定的候选集都没有。
目前主流的KPE任务benchmark数据集有好几个,这里列两个比较有名的
- KP20k:2017年论文Deep Keyphrase Generation贡献的数据集,由科学论文组成。文本包括标题和摘要。发过论文的都知道,作者需要给文章提供几个关键词,确实是很好的数据来源。
- KPTimes:2019年论文****KPTimes: A Large-Scale Dataset for Keyphrase Generation on News Documents****贡献的数据集,文章都是新闻,下面是一个例子。

KPTimes数据样例
这两个数据集规模应该都挺大了,KPTimes的论文里有一张主流数据集规格对照表,一目了然,大家可以参考。从统计上看KP20k和KPTimes篇均5个KP的确实比较实用,但它们的问题是测试集里很大比例的标签并没有在文本中出现,对于模型来说难度可能太大了
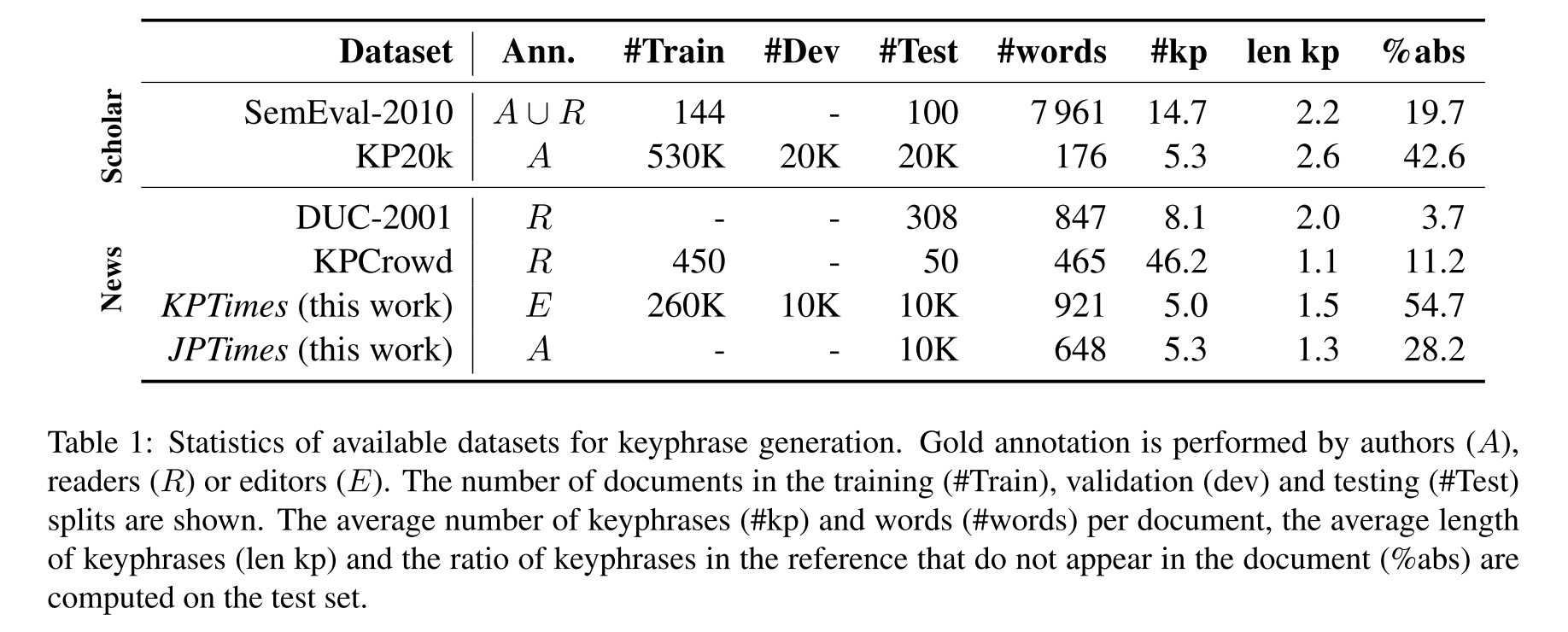
主流数据集对比
监督方法
KP20k数据集其实是那篇论文的副产品,那篇论文的主要贡献其实是一个叫CopyRNN的方法,看名字大概就知道是个seq2seq+copy机制的生成式方法。这里引入copy机制也是有比较明确的动机的,因为在RNN时代生成式方法会受限于字典,decoder输出层没有的词是无法被预测出来的。
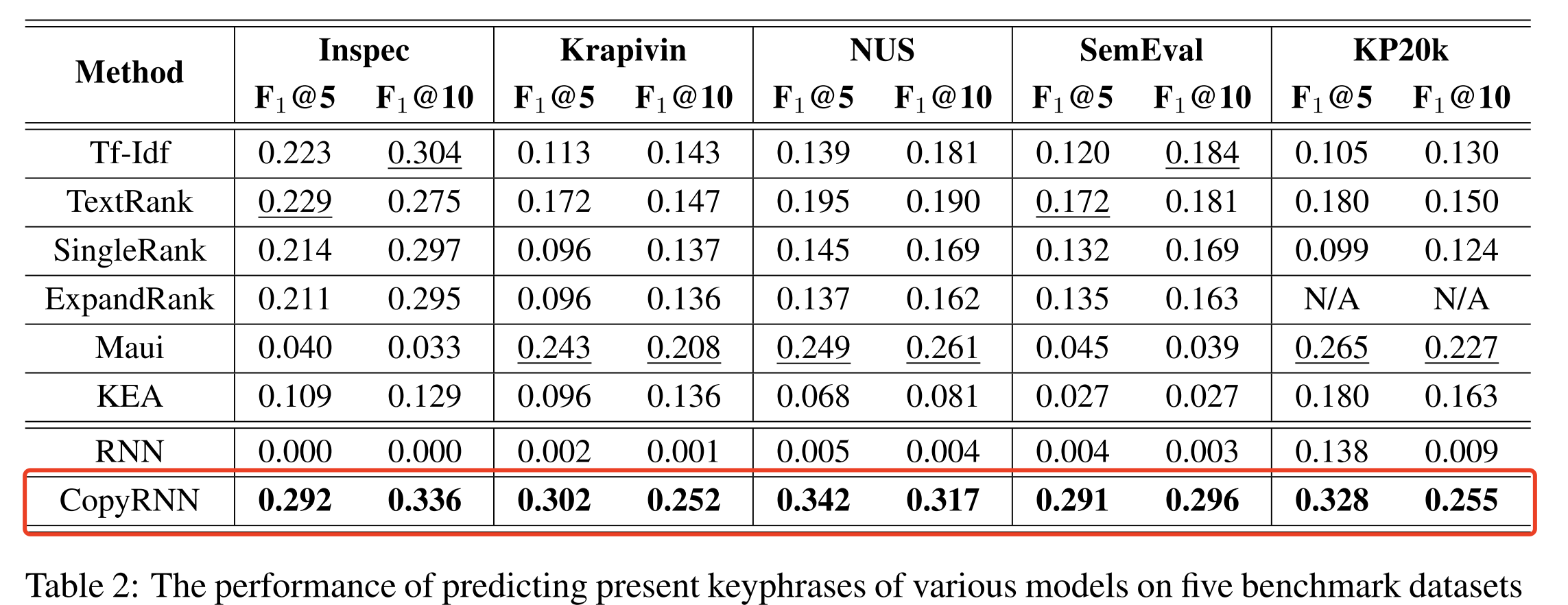
RNN+copy机制可以在KP20k上获得0.255的F1@10
到了2020年,BERT等Transformers模型已经成了NLP领域的标配,那自然也会想到用来做KPE。Joint Keyphrase Chunking and Salience Ranking with BERT 就是里面简单且有效的一个方法。题目里的Salience是个显著的意思,这篇文章的方法也非常直接,就是把最可能是KP的文本段落(n-gram)用排序的方法找出来。那怎么得到一个n-gram的表示呢,这篇文章的办法就是在Transformer上面再套一个一维CNN,n和卷积核的大小相对应。
论文里用了两个任务来训练这个网络,一个任务是二分类,即n-gram是否是KP;另一个是排序任务,这个任务是对于文档中的每个unique n-gram,获得最大的预测值(文中称为max pooling),然后用hinge loss来使得KP的概率值大于非KP。
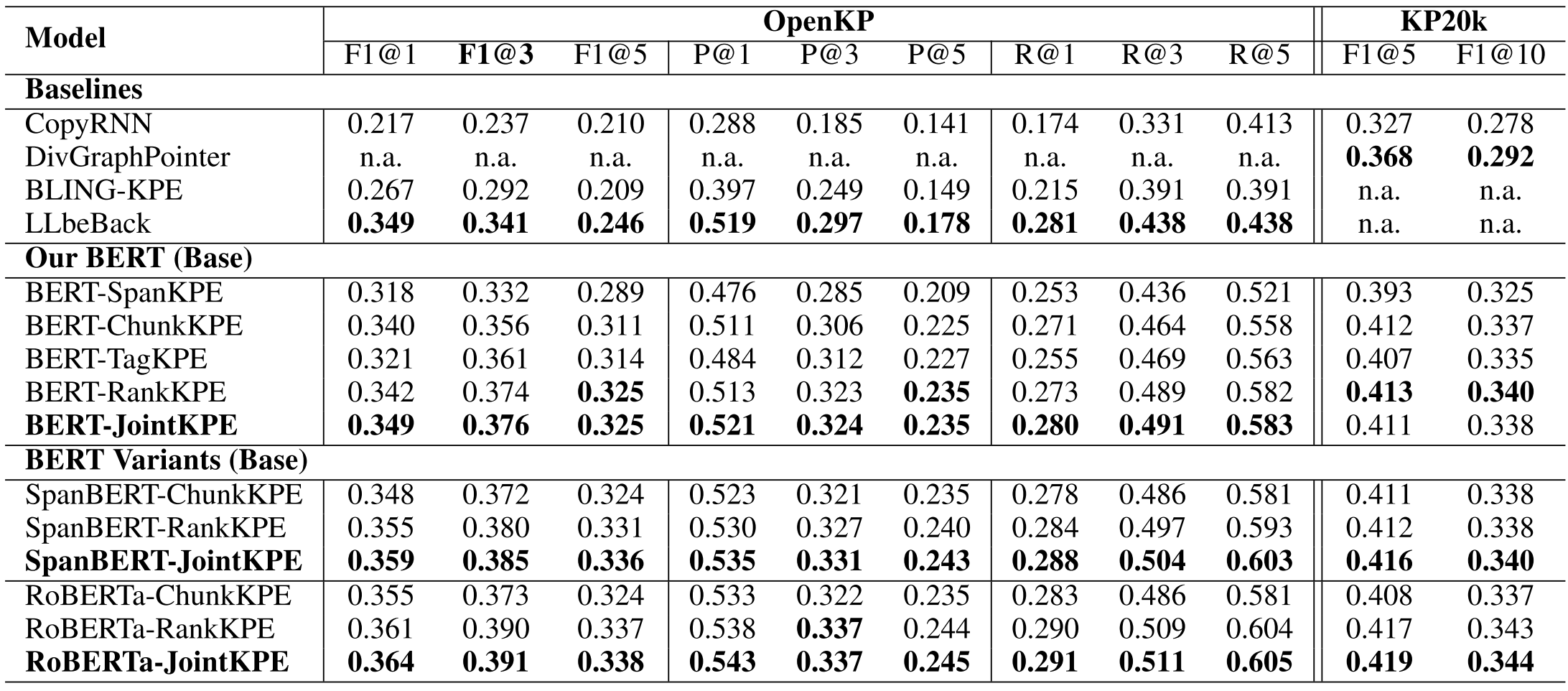
JointKPE的成绩大大提高
感兴趣的朋友们可以参考他们的代码实现。
非监督方法
一开始我是想找一些靠谱的非监督方法的,毕竟像KP20k这样优质的的训练数据集一般只有英语。然后就在paperswithcode上看到了目前的榜一,UCPhrase。这个方法比较有意思,它的流程如下面这张图所示

分为几个核心步骤:
- 找到所谓的Core Phrase。这其实是通过一些规则找到文本中反复出现的片段,并且把它们当做KP,以及后续网络训练的Silver Labels。
- 用Transformers语言模型生成特征。这里的特征不是大家常用的embedding,而是attention map。
- 训练一个图像分类器,对于一个attention map进行是否KP的二分类。
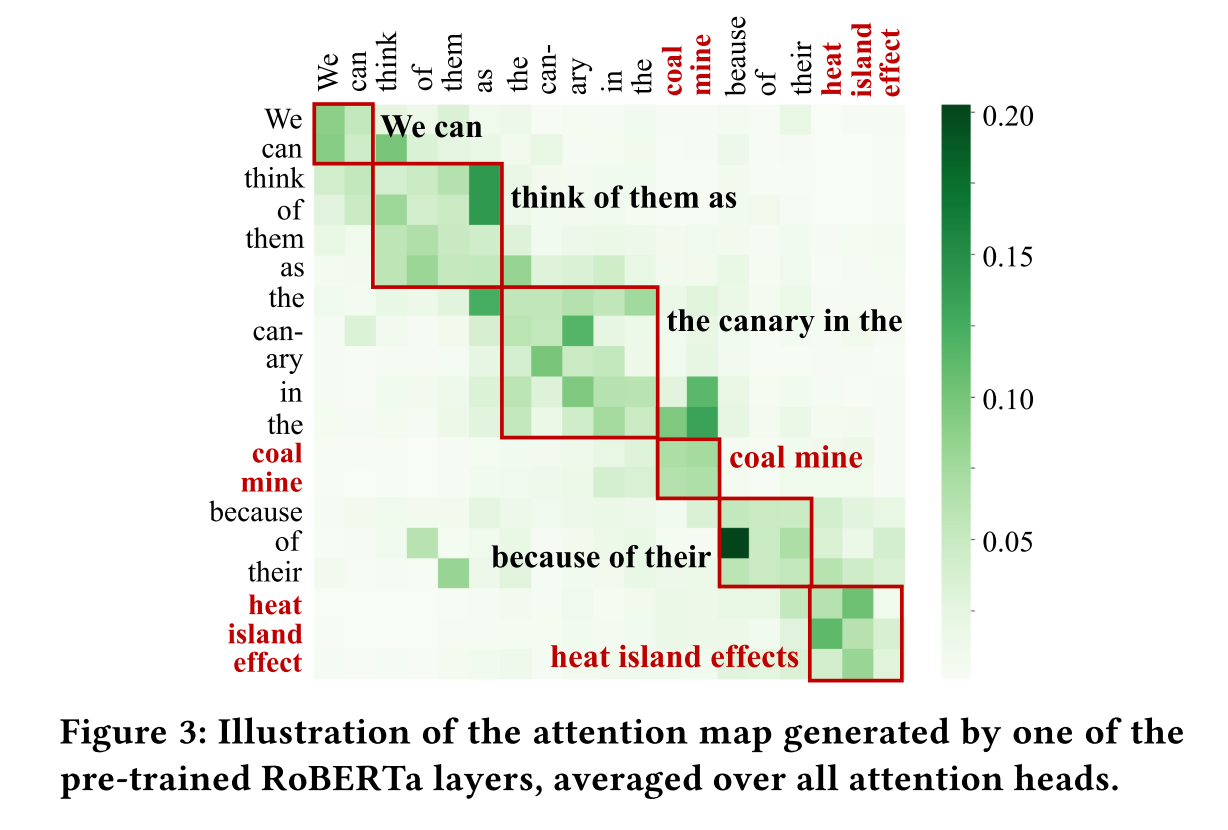
一个attention map样例,从中可以发现:1. attention map把句子分成了比较明显的几块 2.attention map可以可以作为图像输入来进行KP分类
这个论文的结果如下,在KP20k上的F1@10是19.7,和2017年的RNN+copy差了6个百分点,但和同样使用Transformers的监督方法相比差了16个百分点。
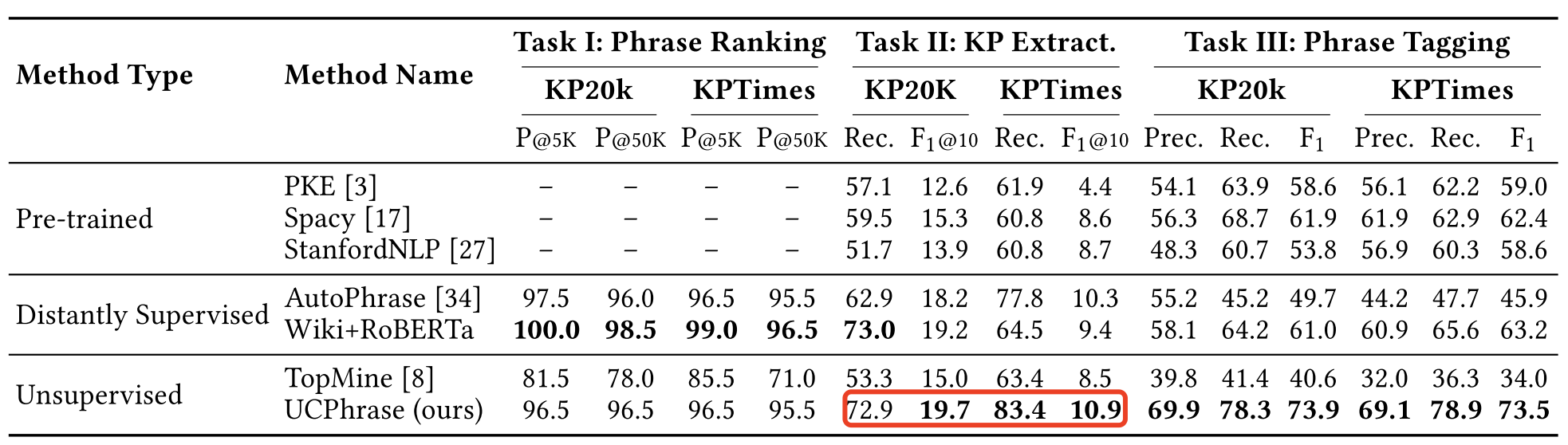
非监督方法比起监督方法来确实逊色不少
这个工作的代码也开源了:https://github.com/xgeric/UCPhrase-exp。
写在最后
提到KPE,可能大家第一个想到的方法是SpanBert那样的span prediction方法,亦或是序列标注里常用的BIO分类法,但JointBert论文里对比下来还是这种接一个CNN的方法更好。相比于单纯序列标注或片段预测,这个方法确实可以更直接地利用附近的邻域信息,在Kaggle中其实也常有在序列标注前先加一层CNN或RNN来强化邻域信息的做法。
UCPhrase的方法让人眼前一亮,有一种学术美,但与JointBert 16个百分点的性能差异又实际上让它的实用价值大打折扣。所以在业务明确的前提下,搞漂亮方法确实不如扎扎实实搞点标注数据啊。