如果你现在不知道DeBERTa,那相当于你在2018年不知道BERT ——多头注意力
DeBERTa模型是微软在2021年提出的,首发在ICLR 2021上,到现在其实已经迭代了三个版本。第一版发布的时候在SuperGLUE排行榜上就已经获得了超越人类的水平,如今也成为了Kaggle上非常重要的NLP Backbone(BERT感觉已经没什么人用了)。比较奇怪的是,似乎这个模型被大家讨论并不多,于是最近看了两篇相关论文DeBERTa: Decoding-enhanced BERT with Disentangled Attention和DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing学习了一下。
DeBERTa 1.0
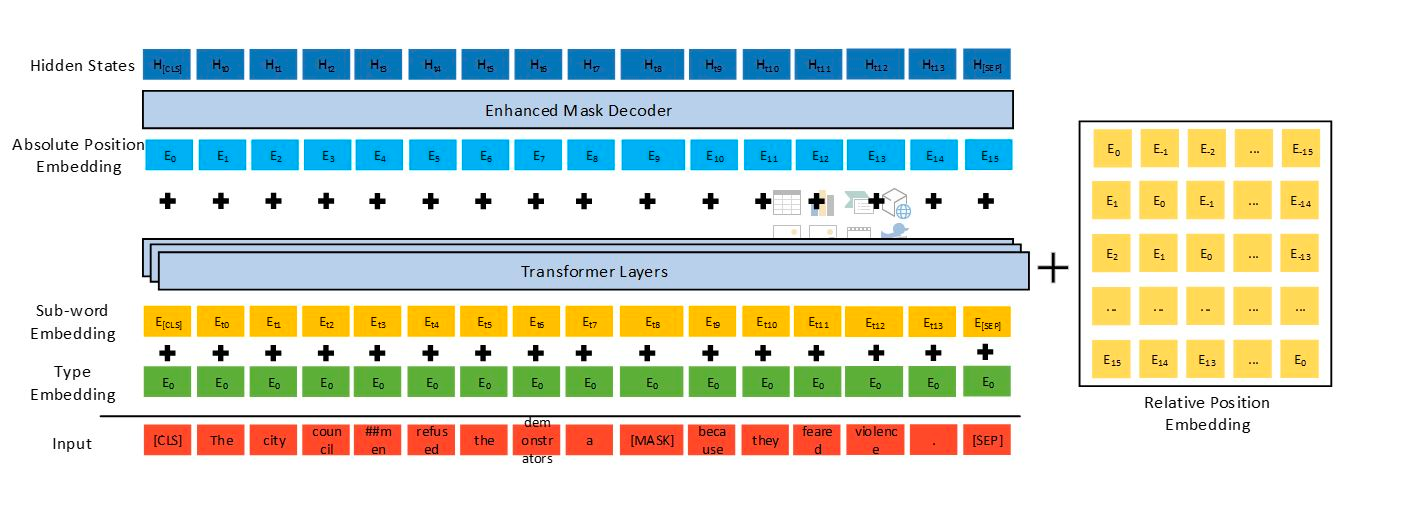
1.0版本在BERT的基础上有三个主要的改进点:
- 更加解耦的self attention,上图中右边黄色部分;
- 考虑绝对位置的MLM任务,上图中Enhanced Mask Decoder;
- 预训练时引入对抗训练
我认为其中1应该是最重要的,然后是3,2最不重要,因为在后面的3.0版本已经不再使用MLM作为预训练任务了。
Disentangled Attention
第一个改进其实有点“复古”,这里的解耦是将位置信息和内容信息分别/交叉做attention。想当年BERT横空出世时大家都津津乐道地讨论为什么可以把word embedding,position embedding加起来做注意力,没想到没过几年却又被分开了。当然,DeBERTa的相对位置编码不同于BERT的绝对位置编码,似乎也不好直接比较。
论文里定义了一个相对位置embedding P,和一个相对距离函数$\delta(i,j)$,除了和标准transformers一样的内容QKV,计算了相对位置QK,分别为$Q_r=PW_{q,r}$,$K_r=PW_{k,r}$。注意力矩阵的计算变成了
$$A_{i,j}={H_i,P_{i|j}}\times{ H_j,P_{j|i}}^T=H_iH_j^T+H_iP_{j|i}^T+P_{i|j}H_j^T+P_{i|j}P_{j|i}$$
第一项是常规的内容自注意力(content-to-content),第二第三项分别是content-to-position和position-to-content,第四项论文里认为不重要,直接省略了。具体看是下面这个公式
$$A_{i,j}=Q^c_i{K^c_j}^T+Q^c_i{K_{r,\delta(i,j)}}^T+K_j^c{Q_{r,\delta(j,i)}}^T$$
这一部分其实看一下代码也比较清晰。
SiFT
对抗训练也是NLPer经常使用的技术了,在做比赛或者公司业务的时候我一般都会使用FGM对抗训练来提升模型的性能。DeBERTa预训练里面引入的对抗训练叫SiFT,比FGM复杂一些,他攻击的对象不是word embedding,而是embedding之后的layer norm。整个过程需要forward 3次,亲测比FGM慢一些。微软已经把代码放出,大家可以参考,在自己的任务里试一试。
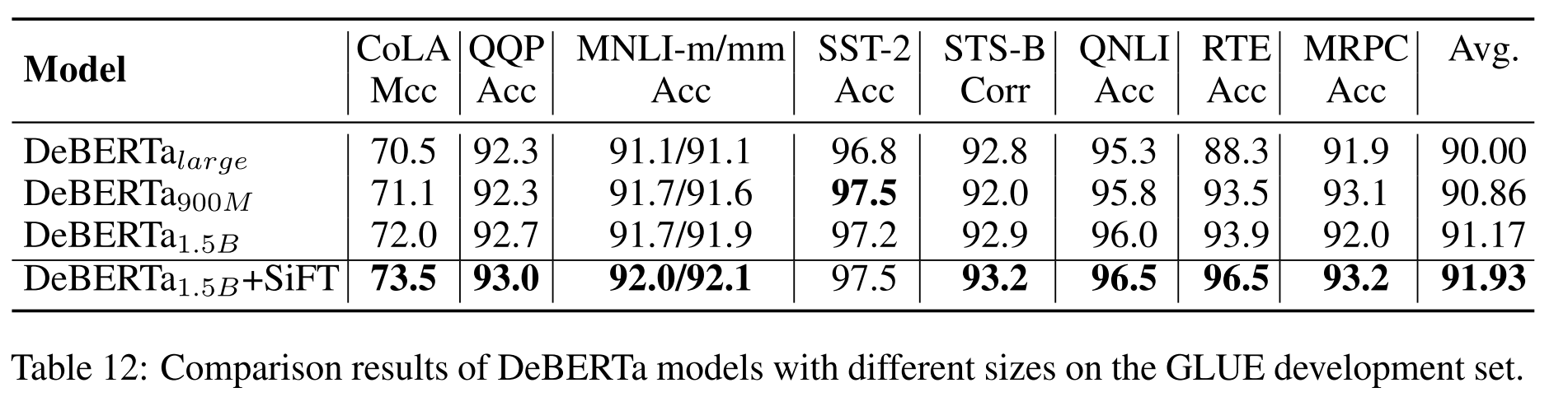
DeBERTa 2.0
2012年2月放出的2.0版本在1.0版本的基础上又做了一些改进:
- 更换tokenizer,将词典扩大了。从1.0版的50k扩成了128k。这个扩大无疑大大增加了模型的capacity。
- 在第一个transformer block后加入卷积。这个技巧在token classification、span prediction任务里经常用到。
- 共享位置和内容的变换矩阵
- 把相对位置编码换成了log bucket,各个尺寸模型的bucket数都是256
这些变化里1和2是把模型变大,3和4是把模型变小。总的效果是V2版本模型比V1版本变大了。
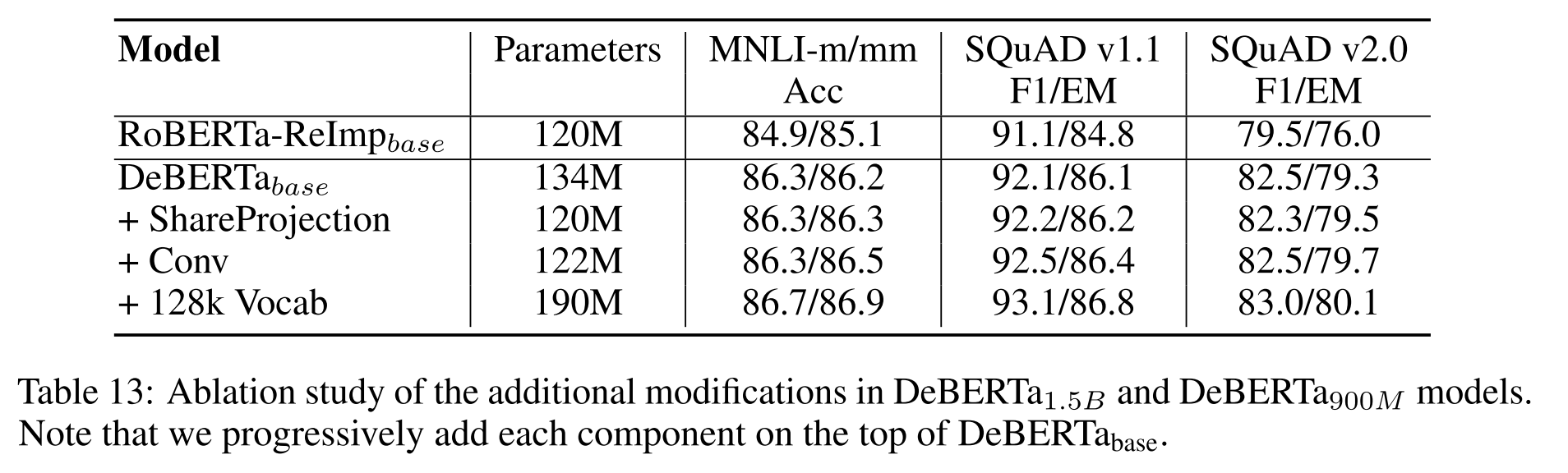
2.0版几个变更对模型的影响,增大词典效果最显著
DeBERTa 3.0
2021年11月微软又放出了3.0版本。这次的版本在模型层面并没有修改,而是将预训练任务由掩码语言模型(MLM)换成了ELECTRA一样类似GAN的Replaced token detect任务。因为多了个生成器,DeBERTa 3.0的论文中也更多的是对不同的embedding sharing的探讨,下面这种图是对文中对比的三种方式的简介。
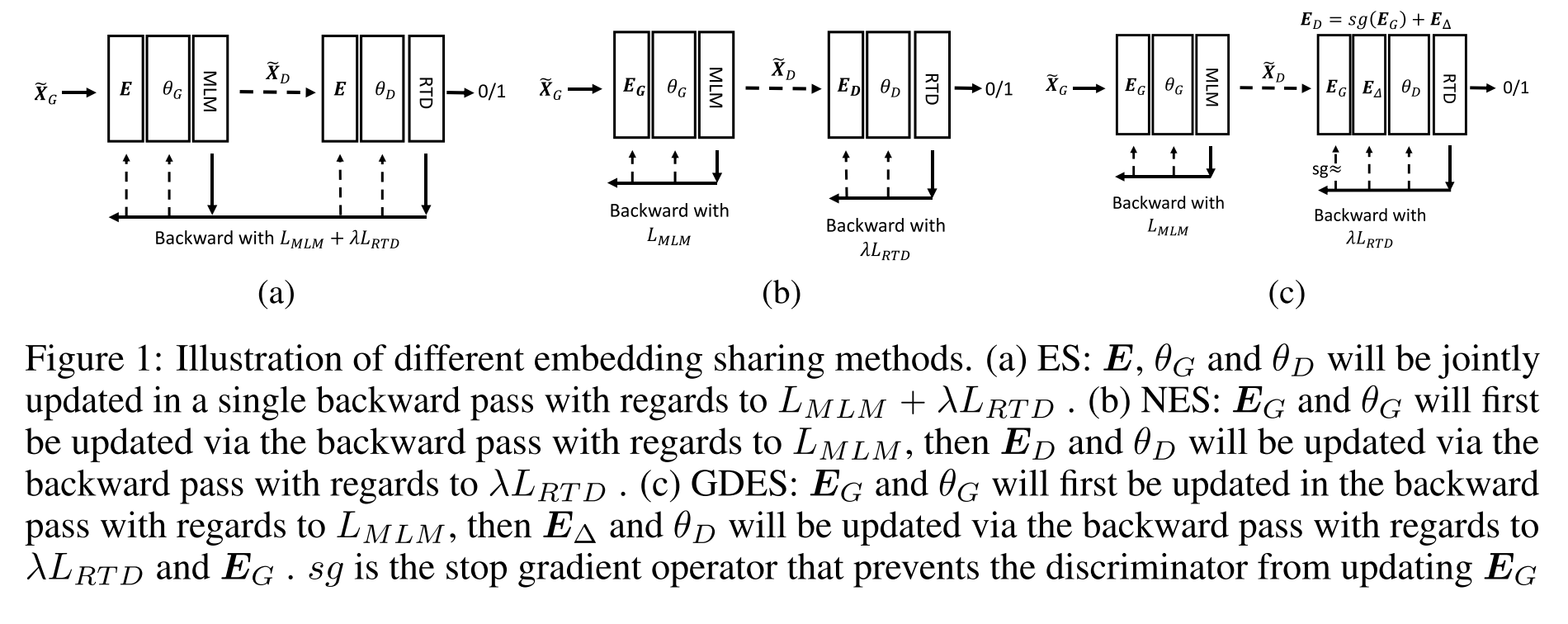
3.0论文探讨的集中参数更新方式
根据下图所示论文的结果,3.0的改进进一步提升了DeBERTa模型的性能(实际并不是所有任务都有提升)。DeBERTa-v3也确实成为了Kaggle上最常见的DeBERTa版本。
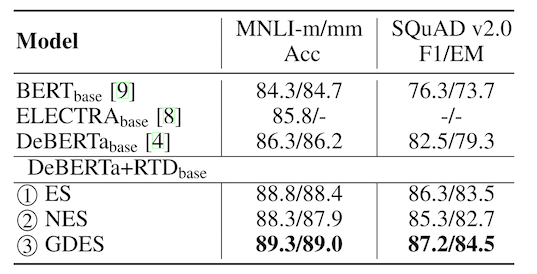
DeBERTa 3.0在某些任务重相比2.0又有不小的涨幅
比较遗憾的是目前代码库中尚未放出RTD任务预训练的代码。
各版本DeBERTa在主流任务上的性能如下表所示。
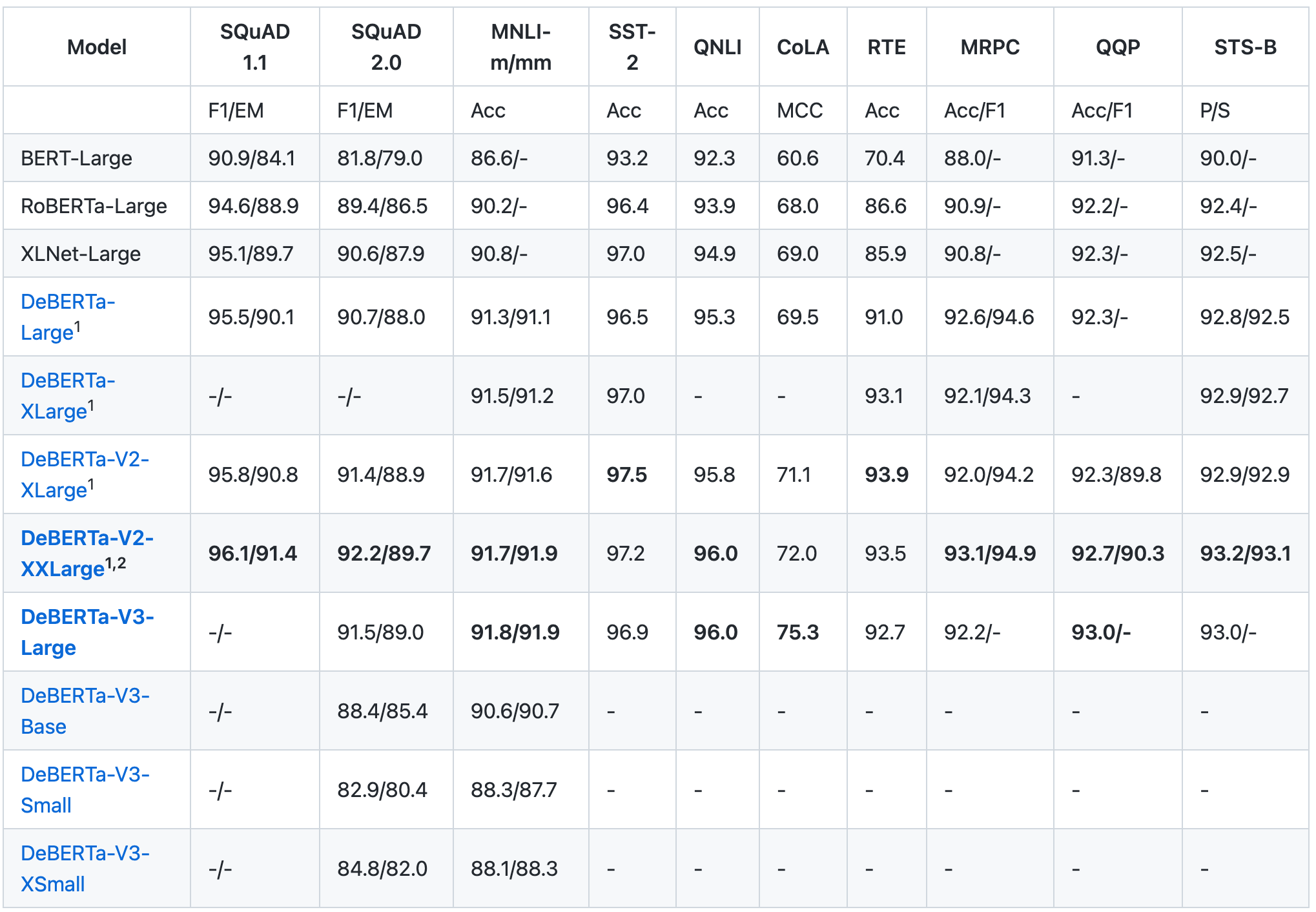
DeBERTa总的来说没有很多非常创新的东西,算是一个集大成的产物,其中的一些方法还有很浓的螺旋前进意味。预训练语言模型发展了这么些年,和刚开始百花齐放时比确实已经没有太多新鲜的东西,但模型水平的进步还是肉眼可见的。以上就是关于DeBERTa的内容,希望对你有帮助。