应该很多朋友知道,在训练下游任务之前先在任务的语料上做一下非监督的masked language model任务预训练可提高目标任务的性能。特别是当下游任务的标注数据少,相关语料多的情况下这个小技巧带来的提升更大。举个例子,假设你要做一个恶意评论分类器,但由于时间和成本关系,只标注了几万条评论,但系统里的评论已经有几百万条,这时候先在所有评论上做个MLM训练,再finetune恶意评论分类任务就是个比较好的选择。
这个问题多年前论文Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks做了比较详细的探讨。
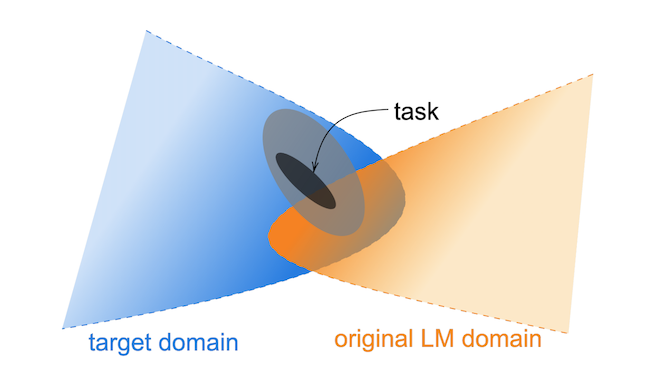
首先是个很好理解的现象,如下图所示,虽然现代化的Transformer语言模型都是由海量数据训练的,但难免跟我们目标任务的语料领域无法完全重叠
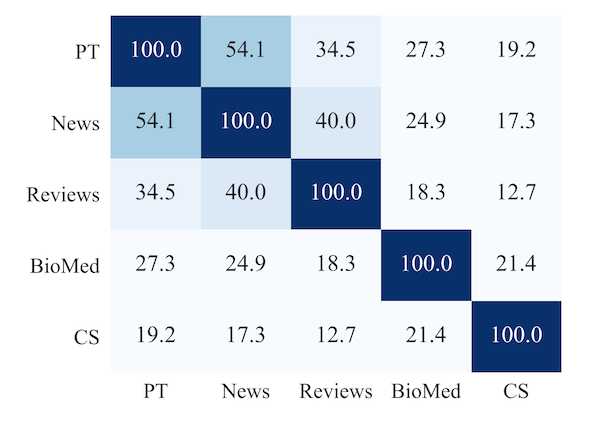
论文还做了定量的分析,它们选了几个领域,然后抽样了每个领域最高频的一万个token,看下重合度,发现确实不高。重合度最高的是新闻,那是因为Roberta训练的语料里其实就有新闻。
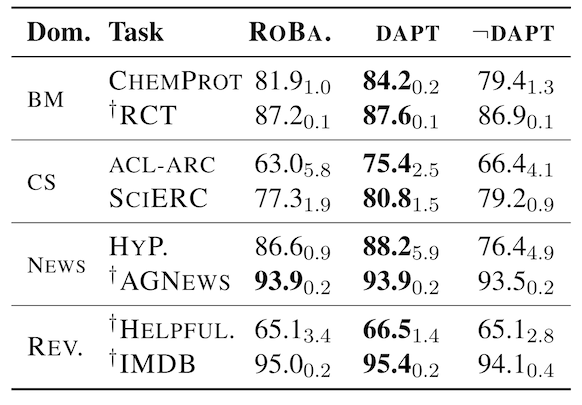
那既然如此,就在目标任务所在领域语料上继续做一把预训练(DAPT),然后再finetune目标任务。同样是上面几种领域的任务,发现经过DAPT之后都有明显提高,上面重合度最低的CS领域提升最明显。最后一列是个比较有意思的实验,它是为了排除单纯增加了训练数据带来的性能提升,选了一个非目标任务所在领域来进行预训练(数据同样变多,但领域和目标任务无关)。结果大多没提升,有些还下降了。这就说明在目标任务领域做预训练确实有效果!
这个论文后面还有不少内容,但我感觉对一般场景有些overkill,就不写了,有兴趣的朋友可以自己看。下面来给大家演示一下怎么用目前主流的transformers库来做MLM,相当简单,可以说是开箱即用。
首先你需要安装Transformers库,然后在transformers/examples/pytorch/language-modeling/目录下面找到run_mlm.py文件,把这个文件复制一份到你的工程目录。
为了做MLM训练,你需要准备好一些文本数据,将他们以一行一个样本的格式写在一个文本文件里,为了可以监控训练的进程,最好是像平常做其他机器学习任务一样准备一个训练集,一个验证集。但由于是MLM,验证集不需要太多。
准备好代码和数据之后就可以来运行这个脚本了,有三部分参数需要指定
模型参数
必须的模型参数只有一个,即
model_name_or_path,即你要使用的基础模型。给这个参数是最方便的,tokenizer等组件会配套使用。你也可以参考代码来精细控制每个组件。数据参数
- train_file,即训练数据路径
- validation_file,即验证数据路径
- max_seq_length,最长的序列长度,不给的话会使用tokenizer的默认最大长度
- mlm_probability遮蔽比例,默认是15%,之前陈丹琦组的论文说增大比例可以提高性能,但目前似乎还有争议
- line_by_line,因为我们的数据是line by line的,所以这个要设置为True
训练参数。这部分参数有很多,可以参考这个文件。比较推荐设置的有以下几个
- output_dir,这个必填,训练后模型保存的地址
- do_train,这个必填
- do_eval,如果有验证集必填
- num_train_epochs,默认为3
- fp16,如果你的显卡支持tensor core,那一定要把这个打开
- weight_decay,MLM的时候可以给点衰减防止过拟合,常用0.01
- per_device_train_batch_size,batch size
最后的成品可能像这样
python run_mlm.py \
--model_name_or_path roberta-base \
--train_file training_corpus.txt \
--validation_file validation_corpus.txt \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--fp16 \
--weight_decay 0.01 \
--line_by_line \
--output_dir ./my-roberta
运行之后可以看到每轮会输出验证集的困惑度,应该能比较明显地看到困惑度再逐轮下降。
我最近在Kaggle的**NBME - Score Clinical Patient Notes**数据上做了些实验,发现提升真的相当明显(符合前面说的领域语料多,标注语料少的情况),如果有在做这个比赛的朋友值得尝试一下哦。