按照第一篇的计划,这篇文章梳理一下常见的摘要生成方法。大部分方法并不复杂,更多的内容其实包含在seq2seq框架、语言模型、self/cross attention这些模块里。
[TOC]
抽取式摘要
所谓抽取式摘要,有点像之前写过的关键词抽取,就是把原文里重要的部分抽出来作为摘要。
前Transformer时代的方法
有好多基于统计的抽取式摘要生成方法,例如jieba里都集成的TextRank。这方面资料很多,大家搜搜就有。
Transformers-based方法
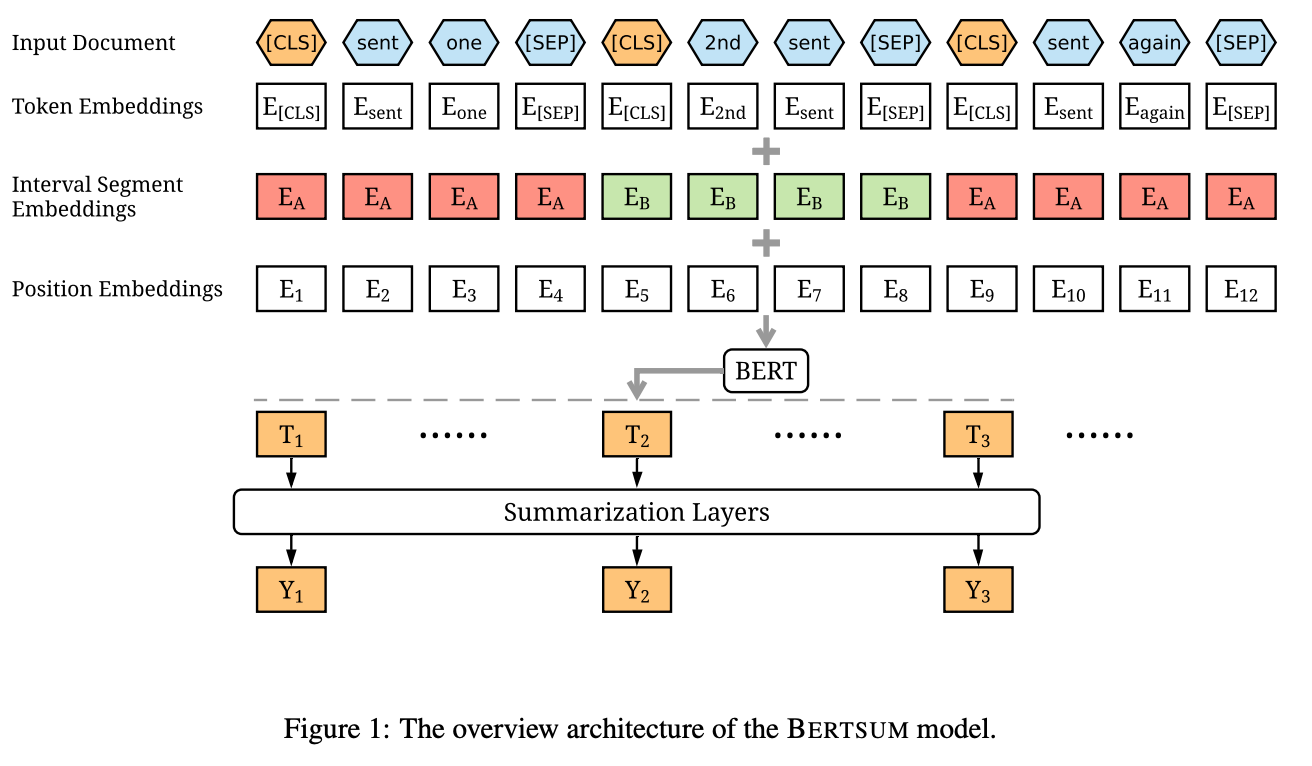
比较典型的工作是BERTSum,其结构如下图。相比原始BERT,几个主要的变化是
- 在每个句子前面增加
[CLS]token,后续用他们对应的隐向量作为句子表征; - 把BERT原有的token type改变成了0/1相间的形式;
- 在得到句子表征后,又增加了一个称为Summarization Layers的Transformer/LSTM模块,用户在句子表征间做交互。
- 最后对于每句话输出一个应该包含进摘要的概率,最终结果由得分top3句子产生。
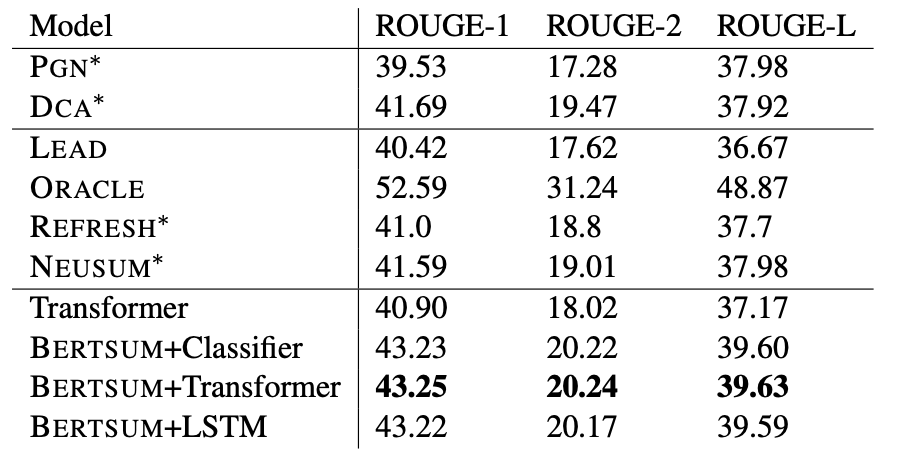
来看一下BERTSum的表现,如下图,总体还是不错的。可以发现加上所谓的Summarization Layers模块并没有很明显的提升,预训练语言模型大部分时候确实很强,光魔改结构往往收效不大。这篇文章的结构我感觉很工整,句子前加[CLS]的操作给人一种细腻的感觉。
生成式摘要
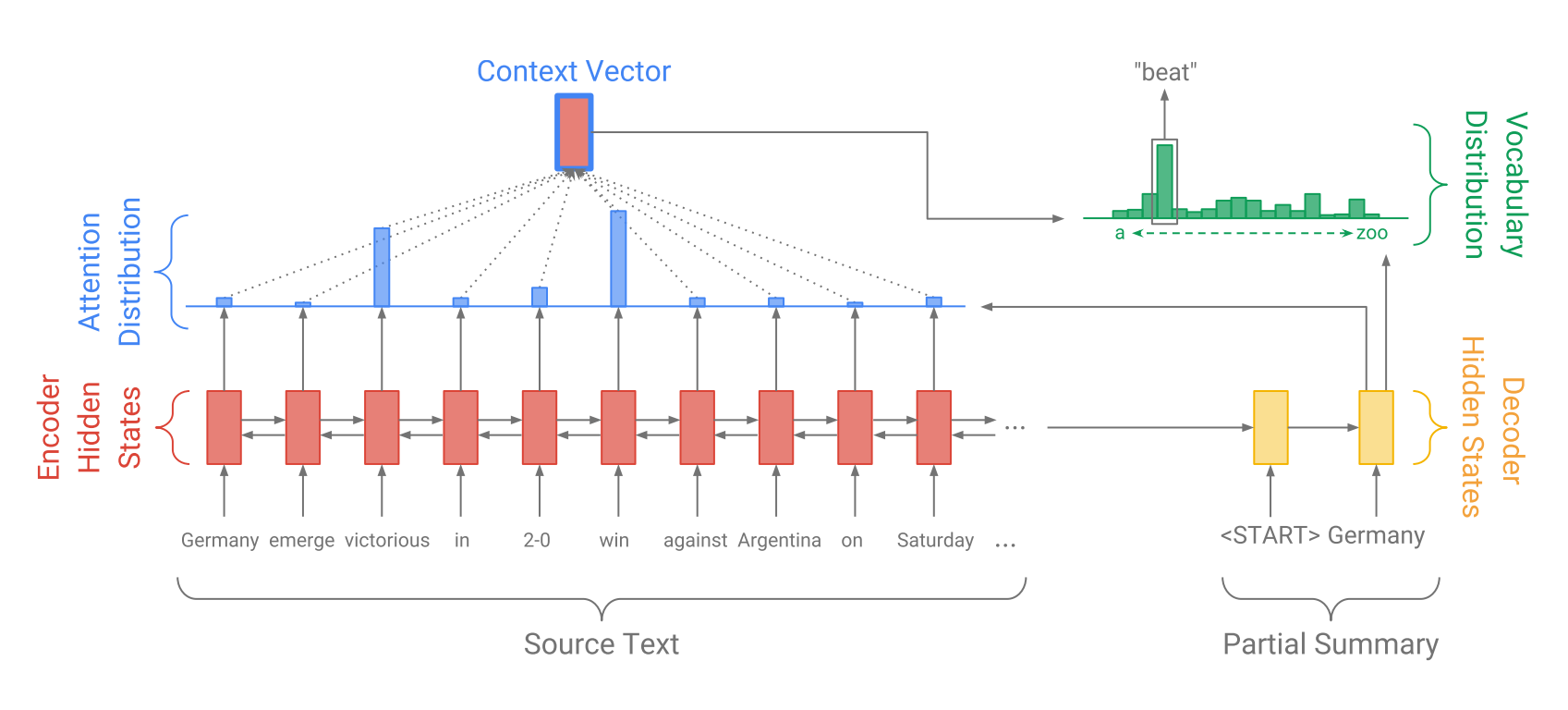
生成式摘要的大体框架很久都没有变过了,大概就是下面这张图。左边是一个encoder,用来编码原文,右边是个decoder,用来生成摘要。
前Transformer时代的方法
在RNN之后,Transformer出来之前,主要的改进是加入各种各样的attention,原文间,摘要间,原文和摘要间等等。大家可以看出来上面那张图已经是有attention的了。
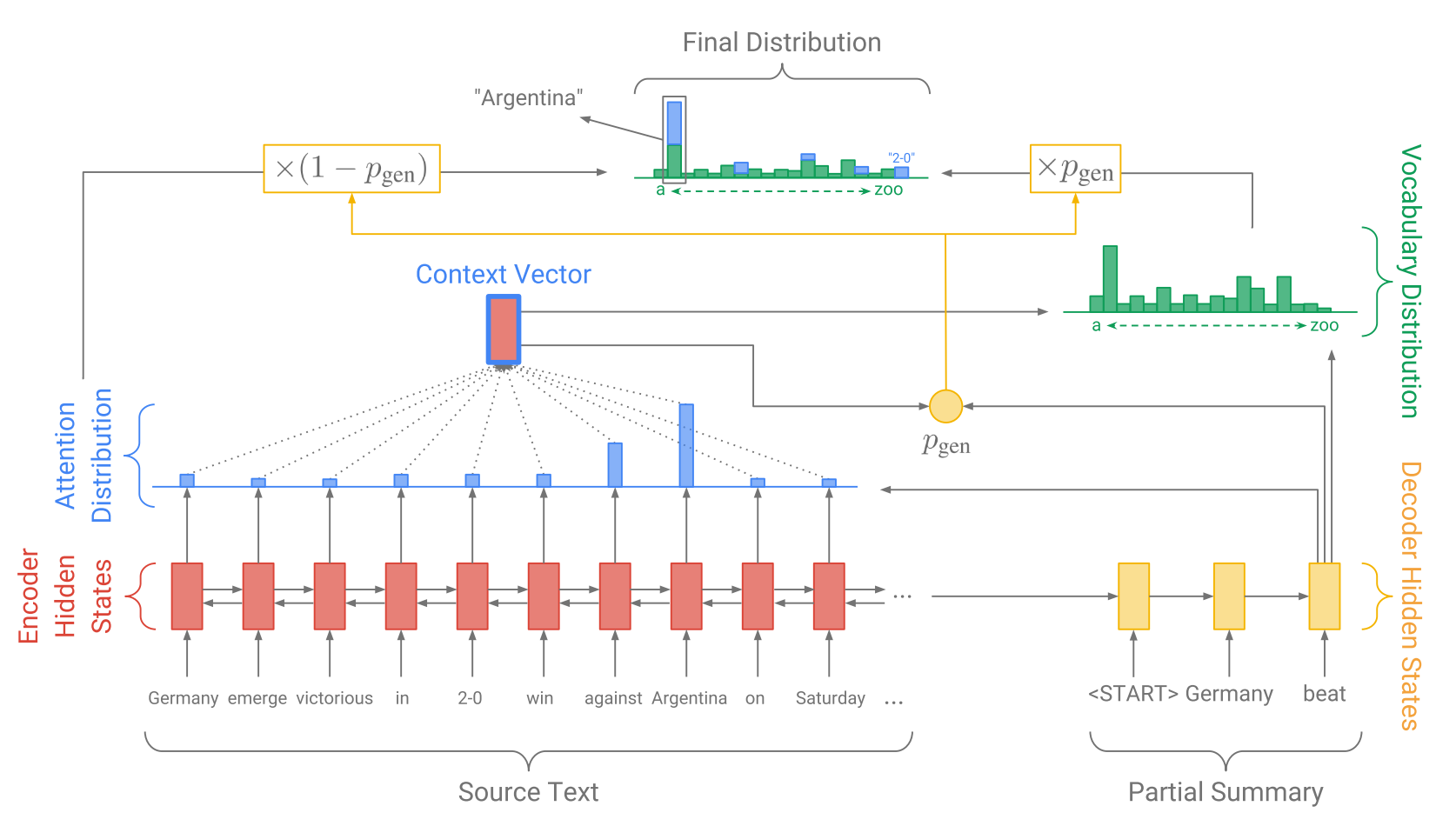
我个人认为前Transformers时代最特别的一个问题是OOV。有不少工作是针对这个问题展开的,其中比较有名的是Google的Pointer Generator。对比和上图的区别可以发现,对于next token的预测,概率分布里出现了"2-0"这个从原文copy出来的词(也是不属于词典的词,是没有copy mechanism之前不可能被生成的词)。真的是要感谢subword tokenizer的广泛使用,让大家省去了很多类似的dirty work。
目前主流的方法
目前的encoder-decoder transformer早已把各种attention玩到登封造极的程度,原文、生成结果间相互的联系已经大大加强。这几年的提升很多都是来自于非结构方面,例如BART用一种新颖的预训练方法来提高,GPT用超大语言模型来提高等。摘要生成逐渐成为了一个跟随语言模型水涨船高的领域(调参调结构当然也有用,但至少大的提升我认为是这样)。
近期刷榜方法
如果大家有关心今年的ACL,会发现摘要相关的论文很多,前段时间还看到丕子老师发微博感叹。不仅数量多,今年在CNN/Dailymail数据集上还有个不小的涨幅,在本文的最后一起来看下是什么神奇的方法。

近几年的刷榜方法我认为可以总结为更加充分地挖掘数据集提供的信号,同时在模型上结合生成模型和判别模型。
我们先从一篇直白的论文Abstractive Summarization with Combination of Pre-trained Sequence-to-Sequence and Saliency Models讲起。这篇论文把原文和摘要中都出现的token认为是重要token,用这个作为监督信号,训练了一个重要性模型(saliency models)。然后尝试了多种组合方式来在解码器上使用重要性模型产生的辅助信号。
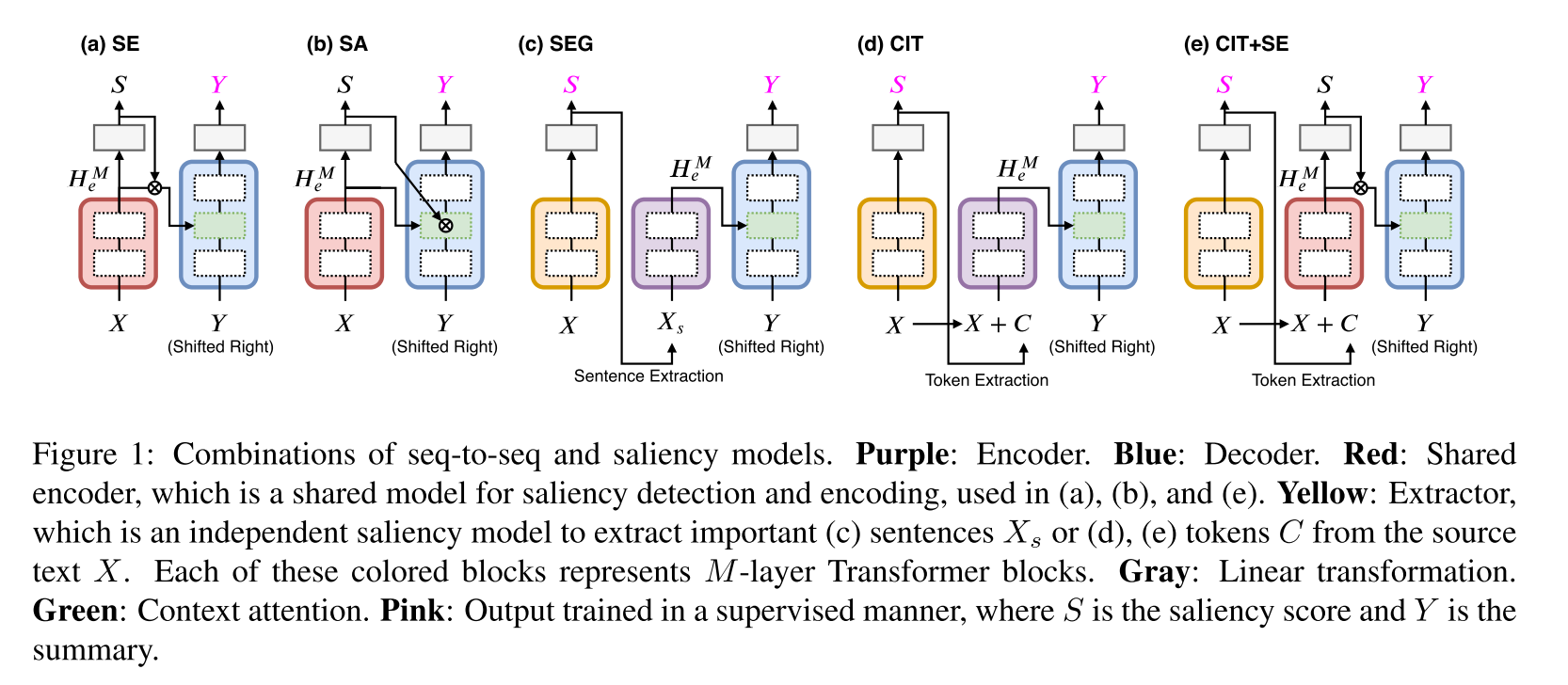
这里解释一下里面出现的几种方式:
- SE,Selective Encoding:用重要性得分来控制编码器输出
- SA,Selective Attention:用重要性得分来控制解码器cross attention
- SEG, Sentence Extraction then Generation:相当于精简原文输入
- CIT, Conditional Summarization Model with Important Tokens:把重要的Token选出来跟原文一起输入编码器
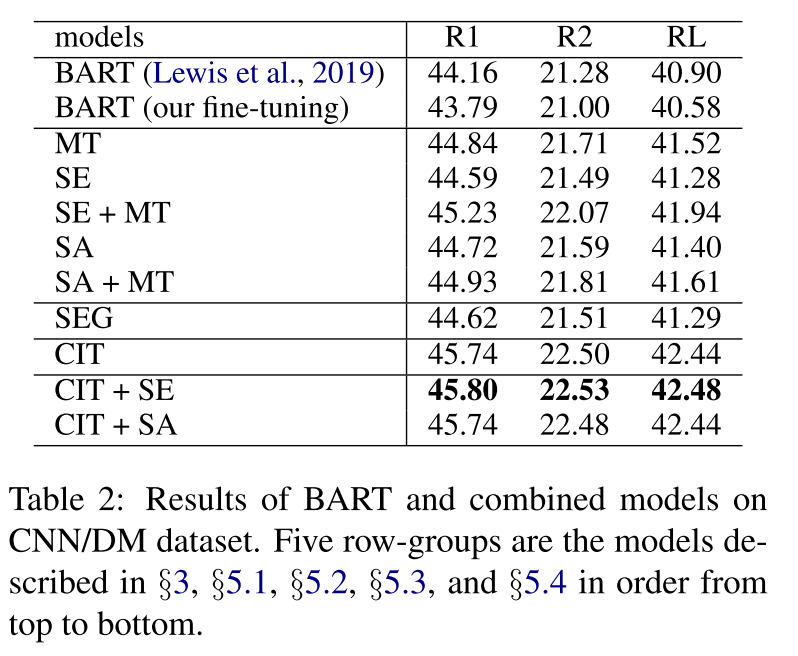
来看一下各种方式的表现,只是单独增加一个siliency model训练任务(MT)就提高了1个点的R1,CIT表现也不错,提升接近两个点。
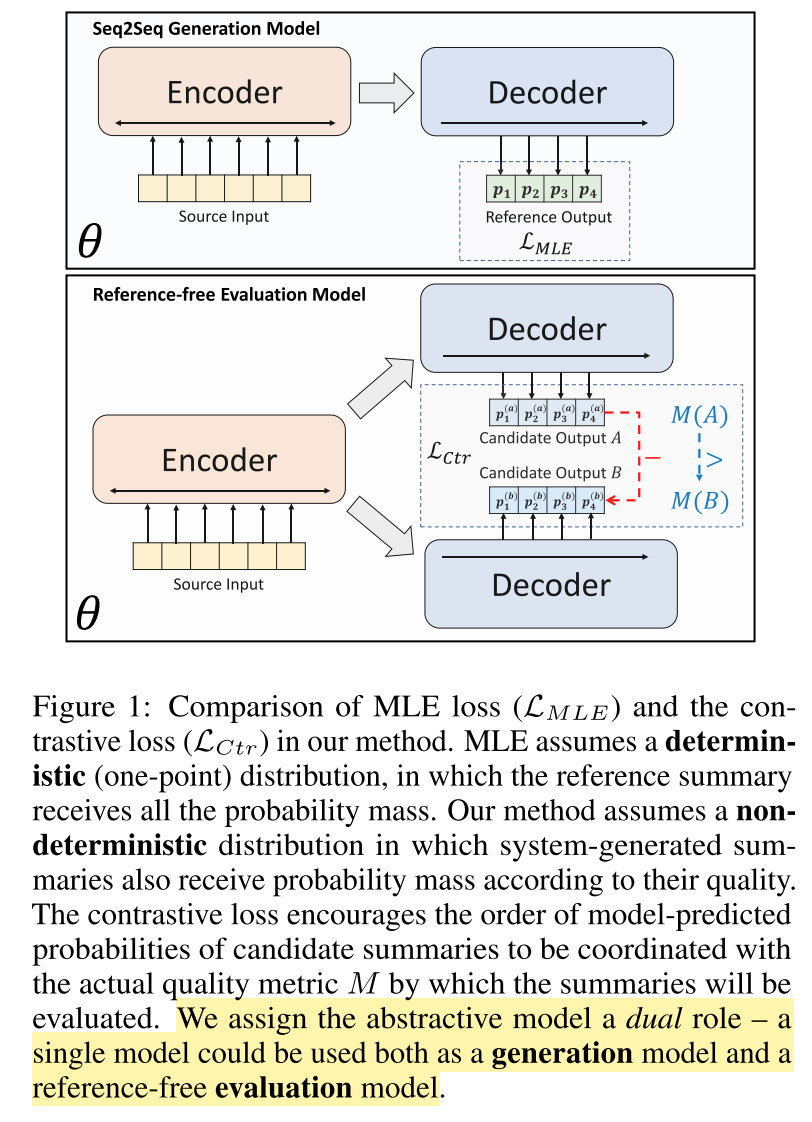
有了上面这篇文章作为基础,我们来看下目前的SOTA,BRIO: Bringing Order to Abstractive Summarization,他们组其实工作是一脉相承的,感兴趣可以看下他们之前的论文GSum: A General Framework for Guided Neural Abstractive Summarization和SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization。
上面的CIT之类工作在原文端利用标签来训练重要性模型,而BRIO在摘要端利用标签来训练排序模型(和生成模型是同一个模型)。结果相当不错。
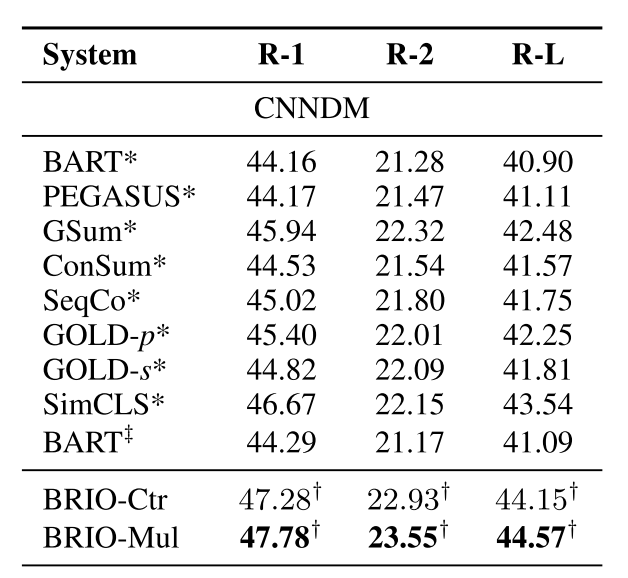
这个模型作者已经开放了权重下载,大家可以去体验一下,看下你能否感受出这相对于BART 3个点的Rouge提升。
本文就先写到这,如果你对这些话题感兴趣,欢迎关注公众号,及时获取更新。