为了迎接宝宝的诞生,前段时间收集了一些中英文故事,做了一个讲故事小程序。

在收集故事的过程中遇到不少问题,比较典型的情况是只有音频,或者只有文字,或者没有配图。在深度学习模型日新月异的2022,我决定尝试用最新的开源模型来解决一下这些问题。
[TOC]
插图生成(text2img)
这是目前大火的领域,每天各种营销号都有大量文章狂轰滥炸。不论是生成梵高画作还是生成性感waifu,似乎AI画师现在已经无所不能。
但我实际使用下来感觉要让AI直接给故事画插图还是蛮困难的。我使用的是最近红的发紫、大名鼎鼎的Stable Diffusion,短短几个月已经发展到第四版了。我的做法也比较简单,直接把故事标题嵌入在一段prompt里面,例如a story illustration for children of the story about The crow and the water bottle 。这个prompt模板是参考了一些prompt编写指南结合尝试之后得到。
在尝试的过程中发现几个比较明显的现象
- 通过art by xxx控制风格非常灵敏,试了梵高和莫奈,得到图片的风格都很强
- 细节效果都比较差,不管是脸还是手,只要有这种部位的图都不太能用
- AI产生的图片有时给人感觉阴森森的,给小朋友做故事书插画估计真会吓死宝宝
下面是几个我生成出来的例子

这个乌鸦喝水的图是我比较满意的,两个东西都画的比较正常,水瓶子里还有点石头,估计是模型训练时有见过这个phrase和相应图片,直接给记住了。

这个图不知所云,没看到有奶牛,青蛙也怪怪的。

这张丑小鸭算是平均水平,虽然鸭头有点怪,但是在可以接受的范围内。
后来我又调研了下,有的朋友为了给故事生成插图做得还是比较fancy的。例如这个小姐姐的repo,大家感兴趣可以看一下,也是开源模型攒的pipeline。
更多生成图片的例子,可以参考这个故事集。
语音转文字(ASR)
虽然各种有声故事大大减轻了讲故事的负担,但给婴儿或者胎儿讲故事最好还是由爸爸妈妈亲自来。毕竟这个时期故事内容肯定是听不懂的,更重要的是让宝宝听到父母的声音。为了能亲自讲故事,我需要把之前找到的一些故事音频(主要是英文的)转换成文本。
经过一番调研,目前比较好的ASR模型是最近openAI开源的来源于论文《Robust Speech Recognition via Large-Scale Weak Supervision》的Whisper。 这个模型是个transformer seq2seq model,从插图来看multi task这块比较复杂。
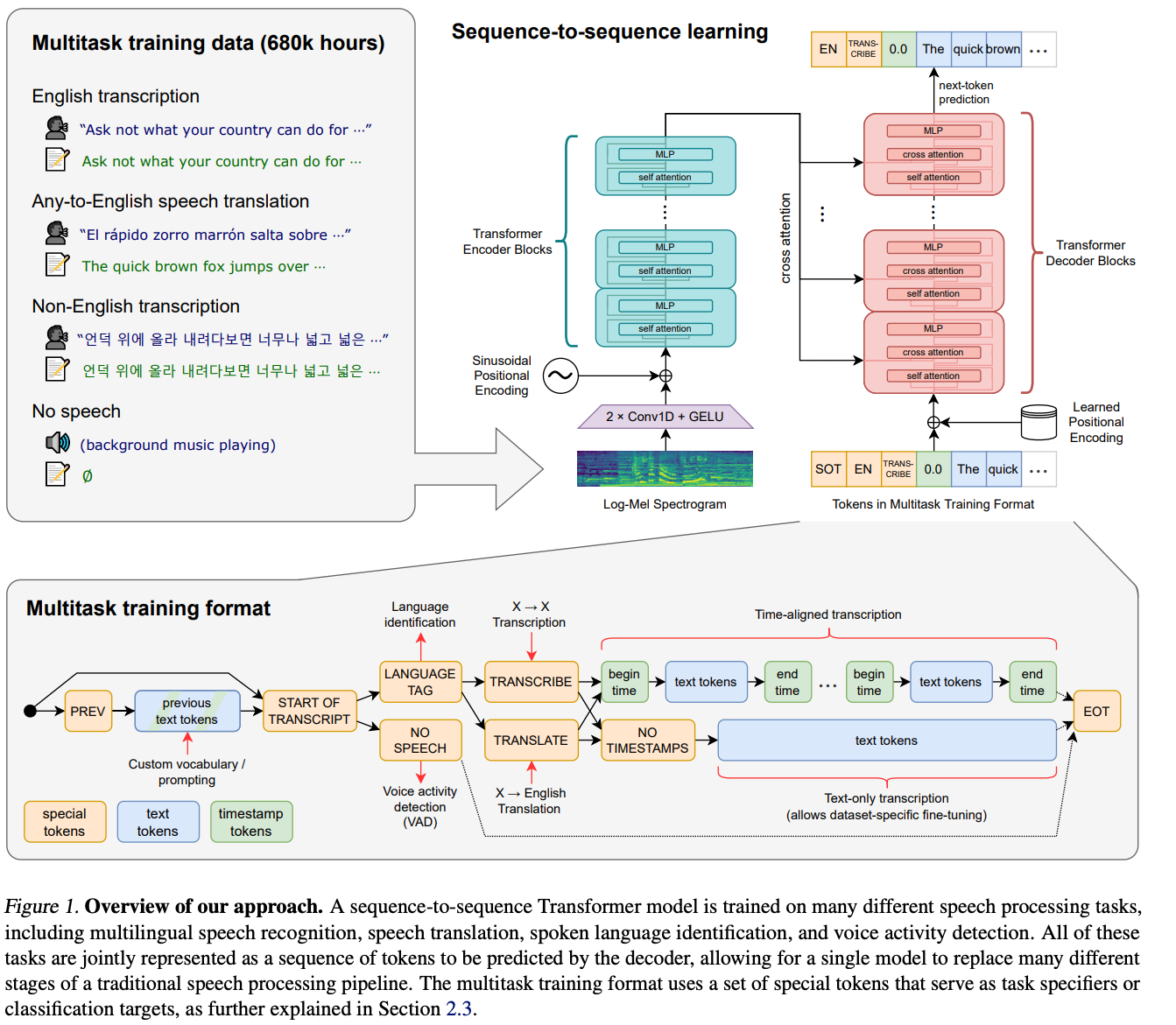
待转写的故事听起来都比较清晰,我直接搞了个base.en单语模型试了一下。跑出来的效果简直惊艳,几乎没有错误的单词,甚至连时态都识别得很准确。唯一美中不足的是有些文章转写出来没有标点符号,也几乎没法识别出段落,给阅读带来一些障碍。为了解决这个问题,我又找了个punctuation restore模型后处理了一下。现代化的语言模型做这个事情简直是易如反掌,效果也相当好。
大家可以看这个故事集里面的内容,都是ASR转写出来的。
文字转语音(TTS)
亲自讲故事虽好,但英语内容不是所有家长都能驾驭的。对于只有文本的英语故事,我也希望能生成相对应的音频。
目前开源模型里面SOTA水平的应该是来自Facebook(Model Card里是叫fastspeech2,但正文里又写是S^2,微软也有一个叫fastspeech的模型,我还没搞懂他们之间关系)的FastSpeech2,这个模型是用faiseq来实现的,但也在huggingface的hub上托管。
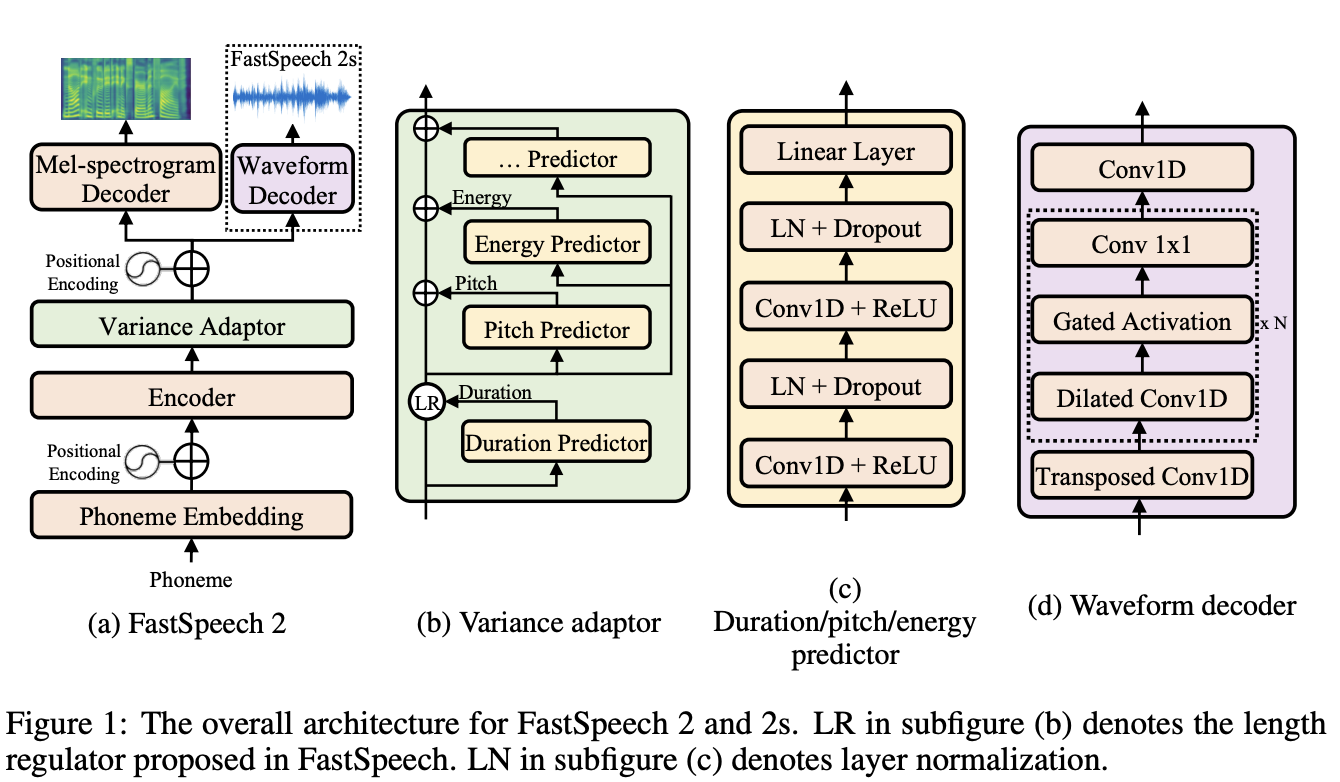
样例代码有点bug,按照讨论区的指导可以跑通。给一段文字的话生成很快,但句与句之间有点黏连太紧,听感不佳。我稍微做了点小后处理,让文章听起来自然了一些。大家可以参考这个故事集的内容。
在做TTS和扫论文的过程中隐约感觉TTS是一个很有意思的领域,后面有时间可以多学习一下。
总之,经过这些有趣尝试,我基本上解决了我遇到的内容问题。虽然这些模型都还有一些问题,但确实已经可以很大得提升生产力。原来需要特别专业团队才能做的事情现在只要几行代码就可以搞定。内容类、工具类产品的玩法也更多了,可以用这些模型和人相互激发促进来产生更多有趣的创意。
本文就先写到这,如果你也需要经常给宝宝讲故事,欢迎使用这个简单的小程序!后面我还会写一两篇关于这个小程序工程和算法方面的心得,如果你感兴趣,欢迎关注公众号,及时获取更新。