最近ChatGPT火了,而且火出圈了。好多不是做技术的朋友都开始关注甚至转发相关文章。从广为流传的一些例子看,ChatGPT确实做出了让大家眼前一亮的效果。聊天机器人搞了这么些年,也终于有了一个让大家都比较认可的产品。
 {: .align-center style=“width:80%”}
ChatGPT的结果令人惊艳
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
ChatGPT的结果令人惊艳
{: .align-caption style=“text-align:center;font-size:smaller”}
小迷思
前几天几个小伙伴聊天,说起ChatGPT和OpenAI,纷纷感叹为什么国内没有这样的创新公司和突破性产品涌现。几个大厂的研究院,比如阿里达摩院、字节AI Lab虽然成果也很多,但跟deepmind、OpenAI比起来差距还是很大。其实ChatGPT背后的东西并不是有多难,但为什么做出来的是他们?
今天在知乎上发现也有类似的问题,还挺火的。不少回答都从大环境的角度分析,有说我们还穷的,有说国内资源和人才不匹配的。这些固然对,但作为个体我们也可以从自己身上找找原因。前几天看到一个做AI架构的大佬在朋友圈感叹,18年就在某大厂实现了500块GPU并行训练transformer,但大家都不知道这东西能干嘛。所以有的时候并不全是资源不到位的问题。我不禁想起了马老师“因为相信,所以看见”的观点,我感觉就是差在这个境界上。从学校毕业五年多了,我感觉这也是自己目前比较大的一个问题,我们有把事情做好的能力,但却缺少真正相信且原意长期坚持的东西。
ChatGPT背后的技术
还是聊回技术。ChatGPT还没有公开的论文,根据OpenAI的博客,基本上使用的技术和他们在今年早些时候公布的InstructGPT差不多。
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
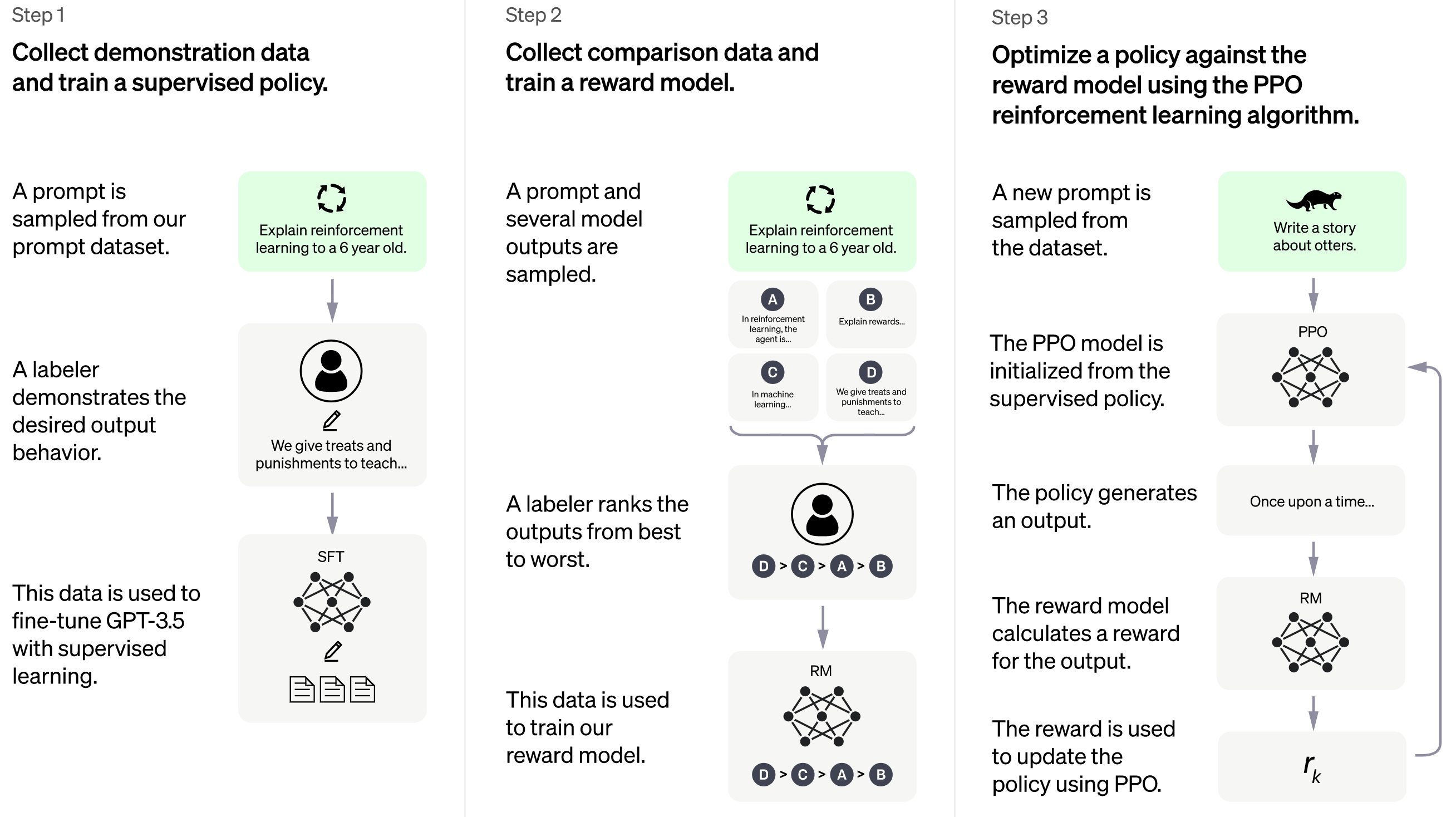 {: .align-center style=“width:80%”}
ChatGPT训练流程
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
ChatGPT训练流程
{: .align-caption style=“text-align:center;font-size:smaller”}
上面是ChatGPT博客上的训练流程图,下面是早先InstructGPT论文里的训练流程图,嗯,可以说是一模一样,比较大的差别是基础语言模型从GPT3升级到了GPT3.5。
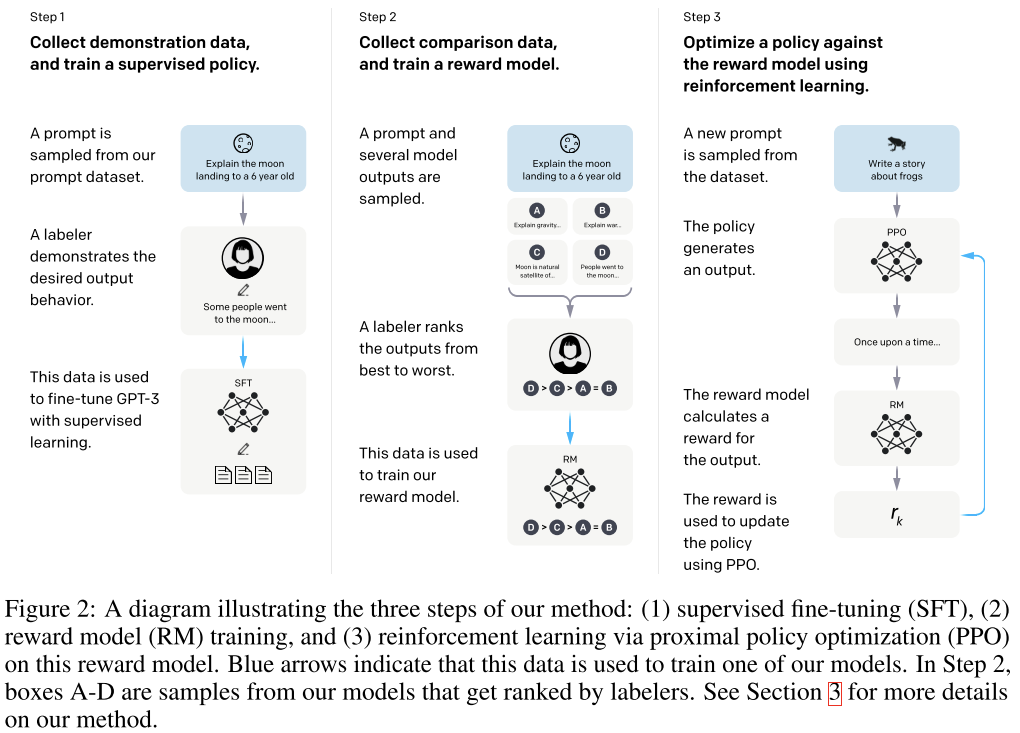 {: .align-center style=“width:80%”}
InstructGPT训练流程
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
InstructGPT训练流程
{: .align-caption style=“text-align:center;font-size:smaller”}
InstructGPT的介绍还有图例,更容易讲清楚ChatGPT是如何训练的。这个模型的训练分为3个步骤:
- 从预训练语言模型出发,用标注者产生的数据fine tune一个根据提示(prompt)生成答案的模型,这一步称为SFT
- 用上一步训练的模型生成大量的答案,每一个prompt都生成多组,并让标注者对这些答案进行排序。用这样获得的数据训练一个奖励模型(Reward Model,RM)。这个模型会作为后续强化学习环节的世界模型。
- 强化学习训练。这一步有点左右互搏的意思,用RM模型作为世界模型,SFT之后的生成模型做agent,进行训练,让生成模型尽可能地在RM模型那里拿到高分。这一步使用的算法也来自OpenAI,为2017年发布的PPO算法。
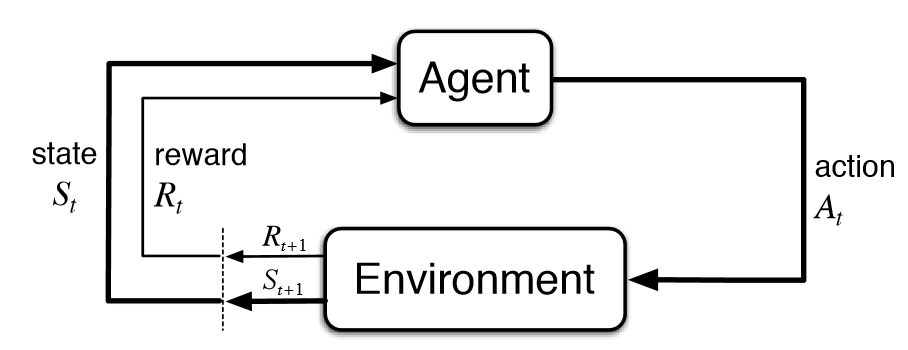 {: .align-center style=“width:80%”}
强化学习基本流程
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
强化学习基本流程
{: .align-caption style=“text-align:center;font-size:smaller”}
我对强化学习并不熟悉,只是稍微看了下PPO的介绍,这个算法的目标函数可以用下面的公式来概括,这个目标函数包含了三个部分,第一部分是标准的强化学习目标,即在reward model那得高分;第二部分是PPO的创新点,即KL惩罚,目的是让强化学习的每一步都不要更新太多(新模型和老模型的KL散度要小);第三部分是针对语言模型精调新加的,为了防止语言模型在精调的时候退化,他们在精调时把语言模型loss也加了进来。三个部分通过两个超参数β和γ进行调节。
 {: .align-center style=“width:80%”}
PPO环节的目标函数
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
PPO环节的目标函数
{: .align-caption style=“text-align:center;font-size:smaller”}
ChatGPT没有公布具体的训练数据情况,但从InstructGPT论文看,训练一个这样的模型并不需要特别多的数据,跟语言模型的训练数据比起来差了好几个数量级。从论文可以看出,用户在他们网站上调戏机器人的数据都有可能被用来做后续模型的训练,所以大家可以感谢自己为人工智能的发展做出的贡献。
The SFT dataset contains about 13k training prompts (from the API and labeler-written), the RM dataset has 33k training prompts (from the API and labeler-written), and the PPO dataset has 31k training prompts (only from the API).
再往前追溯的话,这种RLHF技术出现在2020年OpenAI的论文Learning to summarize from human feedback。这篇论文的工作是使用RLHF技术来改进摘要生成模型。论文里也有一张训练流程图,跟上面两张几乎一样,可以说已经打下了后面两个工作的基础。也就是说这项工作并不是什么突然爆发的突破,而是一个持续了已经有三年的项目。
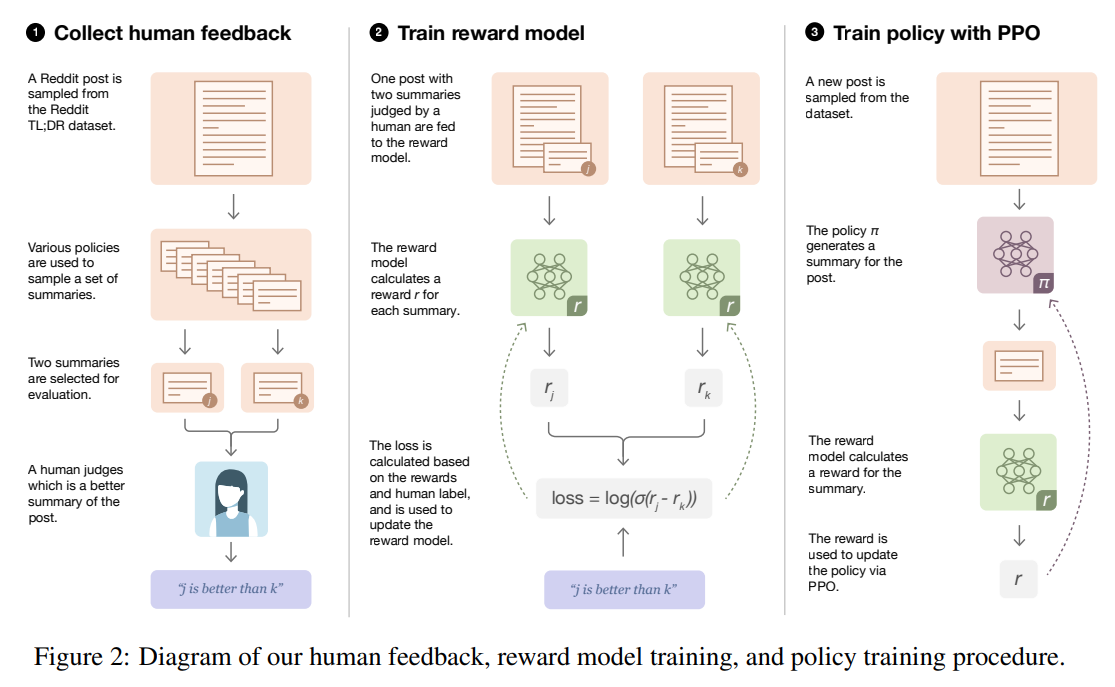 {: .align-center style=“width:80%”}
Learning to summarize from human feedback训练流程.
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
Learning to summarize from human feedback训练流程.
{: .align-caption style=“text-align:center;font-size:smaller”}
我怎么看ChatGPT
不管在网上看到的效果多惊艳,都不能改变ChatGPT是个统计学习模型的事实。它的173 Billion权重体现的本质上还是字词的共现规律。它并不理解你说的是什么,只是对于你打下的问题,他可以得到一个符合训练数据中的统计规律且能在reward model那里得到高分的答案。
网上有很多关于它会不会替代搜索引擎的讨论,我感觉这根本不是一个层面的东西。搜索引擎虽然有排序,但本质上还是你来在信息间做选择。但在对话里,你只能选择信或者不信。而且把知识固化在参数里也意味着不好更新,ChatGPT虽然见多识广,但记忆只停留在2021年。
网上还有不少看热闹不嫌事大的文章鼓吹这个技术的诞生会让多少人的饭碗消失。这个担忧,我倒觉得不无道理。ChatGPT给出的是符合概率分布的结果,并不是出众的结果,和它类似的东西其实还有很多。比如我常常使用的作图工具“可画”,可以用它快速得到一些还看得过去的素材,但这些素材和艺术肯定不沾边。很多白领工作会因为这些工具的诞生蓝领化,然后无人化。作为人,我们只能尽量让自己有输出“分布外”结果的能力。就像不管机床多精密,机器人多牛逼,大师的雕塑还是可以价值连城。