2022年Q4,在项目里接触了一些跟召回相关的工作,但坦白讲做的比较匆忙。整好最近在家带娃,空余时间比较系统地学习了一下,这篇小作文做个总结。
本文总结的算法都有一个共同的发端,就是大名鼎鼎的协同滤波(collaborative filtering,CF)算法。这个协同只看字面也看不出个所以然,维基百科的解释如下
协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术。 该技术通过分析用户或者事物之间的相似性(“协同”),来预测用户可能感兴趣的内容并将此内容推荐给用户。
经典CF
最早的CF算法是user CF。这种算法包含两个主要步骤
- 对于当前用户,在所有用户中寻找与他最相似的一些用户
- 用相似用户对item的评价来作为当前用户对item的评价
我做的几个召回渠道也是基于CF的。如果把这个技术用在召回里,就是对于当前user,返回在与之相似的用户中受欢迎的item。这里面用户相似度的评价方式比较重要,例如通过计算两个用户交互过item的Jaccard距离来作为相似度。这种做法在用户集合很大时计算复杂度相当高。在早期的系统里,item的数量可能远远少于用户的数量,并且用户的相似度会随着用户行为的变化而变化。所以有人提出在item与item之间直接计算相似度,这种相似度相对稳定,离线计算好一个相似度关系表之后在线可以直接使用,这样就可以避免相似用户计算这个耗时的步骤,这种做法称为item CF。
矩阵分解 Matrix Factorization
上面的经典CF算法实际是个间接推荐的方法,人们发现可以从用户和item的交互历史中得到用户和item的关系,从而进行直接推荐。基本的思路是将user-item交互矩阵近似为user矩阵和item矩阵的乘积。具体来说,若用户数为N,item数为M,则交互矩阵为N*M,希望把它近似为N*K和M*K两个矩阵的乘积。K可以远小于N和M,这样相似度的计算复杂度将比jaccard大大降低。实际上也就是获得了K维的user和item的embedding。交互矩阵通常是0,1矩阵(称为implicit feedback data),上面的操作实际上要让有交互的user和item embedding之间的点积接近1,没有交互的embedding点积远离1。
以下图为例,我们获得了4个用户和5部电影的交互矩阵,右边是矩阵分解之后的结果。左边4*2的矩阵为用户矩阵,在一个二维空间对用户进行表征,上面5*2的矩阵是电影矩阵,在同一个二维空间对电影进行表征。右边的大矩阵是这两个矩阵相乘的结果,和左侧0,1矩阵是比较接近但不完全一致的(毕竟降维了)。对于一个user未交互过的item,我们可以拿user的embedding和item embedding做点积来预测用户发生交互的概率。
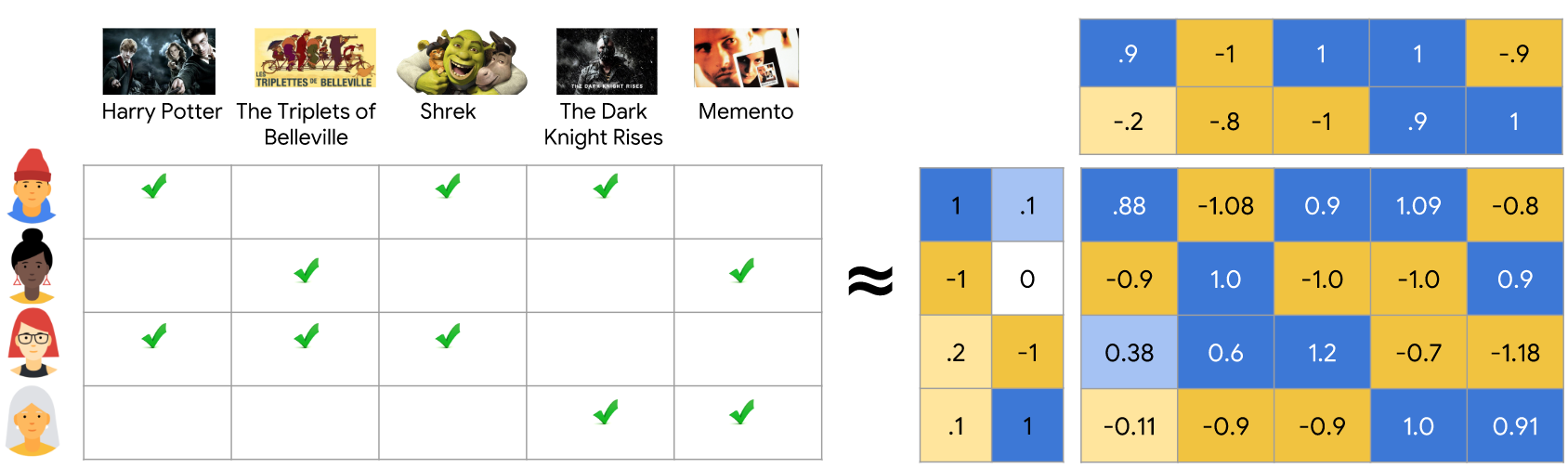 {: .align-center style=“width:80%”}
Matrix Factorization示意图
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
Matrix Factorization示意图
{: .align-caption style=“text-align:center;font-size:smaller”}
这个算法实际上优化的是下面这个目标
$$ \min_{U \in \mathbb R^{m \times d},\ V \in \mathbb R^{n \times d}} |A - U V^T|_F^2. $$
学过数值分析的话会知道矩阵分解有一些经典算法,例如SVD。但这个交互矩阵A实在是太稀疏且太大了,经典算法比较难处理,因此实用的损失函数是这样
$$ \min_{U \in \mathbb R^{m \times d},\ V \in \mathbb R^{n \times d}} \sum_{(i, j) \in \text{obs}} (A_{ij} - \langle U_{i}, V_{j} \rangle)^2 + w_0 \sum_{(i, j) \not \in \text{obs}} (\langle U_i, V_j\rangle)^2. $$
这里w0是负样本权重,在正负失衡数据集里是个重要的超参数。同样的,也可以对正样本加一些权重,例如常见的策略是对全局热门的item进行降权。这样就把矩阵分解问题转化为了机器学习问题,可以用梯度下降的方式求解。
这么一个算法如果用现在的深度学习框架来实现也非常方便,输入就是user和item的id,定义两个embedding layer,然后将同一条数据的user和item embedding进行点积,再和标签求loss即可。
分解机 Factorization Machines
把矩阵分解再扩展一下就可以得到另一个大名鼎鼎的算法Factorization Machines。MF里面只是把交互矩阵分解为U和I两个矩阵的乘积,实际上我们可以引入更多除了id以外的特征来解释交互矩阵,数学一点表达就是把交互概率 [P(y|user_id, item_id)] 扩展为 [P(y|user_id, item_id, other_features)]。
以下图为例,除了user和item的id,引入了三个(组)新的特征,分别是对电影的评分(黄),打分时间(绿)和上一部打分的电影(棕)。凭直觉也可以知道对其他电影的评分对于预测当前用户对当前电影的评分一定是个强特征。这个信息在MF里面不能说完全没有,而是通过学习历史交互然后隐含在用户embedding里,而在FM里则显式地引入了进来。
 {: .align-center style=“width:80%”}
FM的输入
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
FM的输入
{: .align-caption style=“text-align:center;font-size:smaller”}
因为特征变多,FM的的交互也变多了,所有的特征间两两都有交互,它的数学公式是下面这个式子。这个算法在召回层用得不多,但在排序的时候,其扩展例如deepFM仍然算是一个值得尝试的算法。
$$ \hat{y}(x) = \mathbf{w}0 + \sum{i=1}^d \mathbf{w}i x_i + \sum{i=1}^d\sum_{j=i+1}^d \langle\mathbf{v}_i, \mathbf{v}_j\rangle x_i x_j $$
对交互方式的另一种扩展
上面的矩阵分解算法非常强大,但也有很多可以改进的地方。例如在MF中,user和item的交互方式非常简单,就是通过点积,embedding的各维度间是不交互的。2017年的著名论文Neural Collaborative Filtering就在交互方式上往前进了一大步。
上面提到了MF的实现方式,NCF的做法实际也很简单,就是将交互环节中的点积换成了若干层的全连接网络。这么做之后,embedding的所有的维度间都可以进行交互了,并且通过引入非线性激活函数进一步增强了这种交互的表现力。
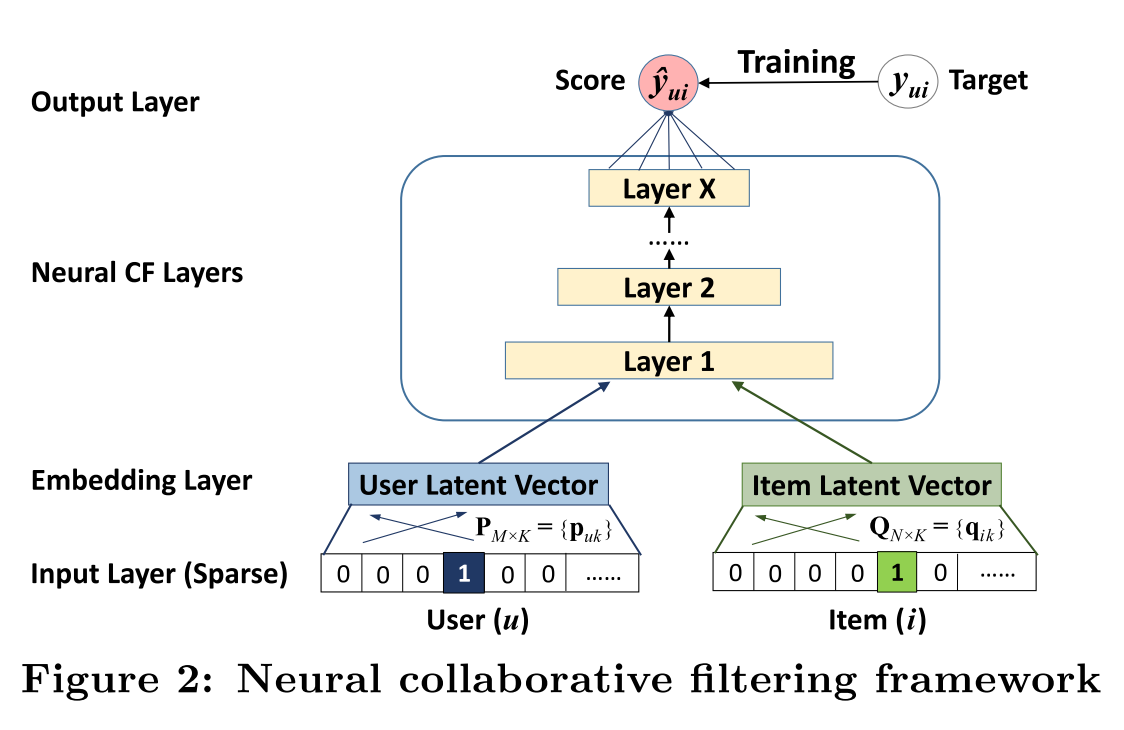 {: .align-center style=“width:80%”}
NCF结构图
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
NCF结构图
{: .align-caption style=“text-align:center;font-size:smaller”}
这么一搞,在各个benchmark数据集上都大幅度提升。这种单塔的结构在线上因为计算复杂度高较难大规模使用,在精排阶段可以,但基本无法在候选集巨大的召回阶段使用。
基于多分类的做法
对于MF和NCF这两种方法,一条数据就是一个user-item pair,标签也是针对这个pair的。如果交互只分0,1的话实际上对应的就是个二分类任务。在2016年的时候谷歌发表了一篇经典论文,介绍他们的YouTube推荐系统。这篇名为Deep neural networks for youtube recommendations的论文相当经典,算是开了深度网络做推荐的先河。网上的解读有很多,但都不是很透彻。这篇论文覆盖面比较广,这里只解读召回阶段网络,文中称为Candidate Generation。
下图是这个网络的结构图,乍一看和上面的NCF很像,其实差别很大。谷歌这个网络的输入只有用户(和正例样本,example age)相关的信息,包括历史点击过的视频的mean embedding、历史搜索过的query的mean embedding、性别、年龄、地域等等。这个模型还有点后面大火的序列建模的味道,把简单的mean pooling扩展一下其实就和DIN等模型比较像了。这些输入经过一个单塔后,输出的就是用户的embedding。user和item的交互发生在最后一层,也就是图中是softmax,softmax通常指一种激活函数,这里实际上在前面还有一个全连接输出层。这个全连接的输入维度是user embedding的维度,用K表示,输出维度是训练数据集的视频数量,用M表示,M大约是一百万(因为类别众多,文中称这种问题为extreme multiclass)。
有metric learning经验的朋友应该很容易理解,实际上全连接层就是在做矩阵乘法,这里就是把用户的embedding和所有的视频embedding做点积,然后通过softmax函数将这M个点积结果转化为一个概率分布。当然,实际操作时不会和所有视频都交互,论文中采用了负采样的方式,只取了1000个左右的负例来训练。
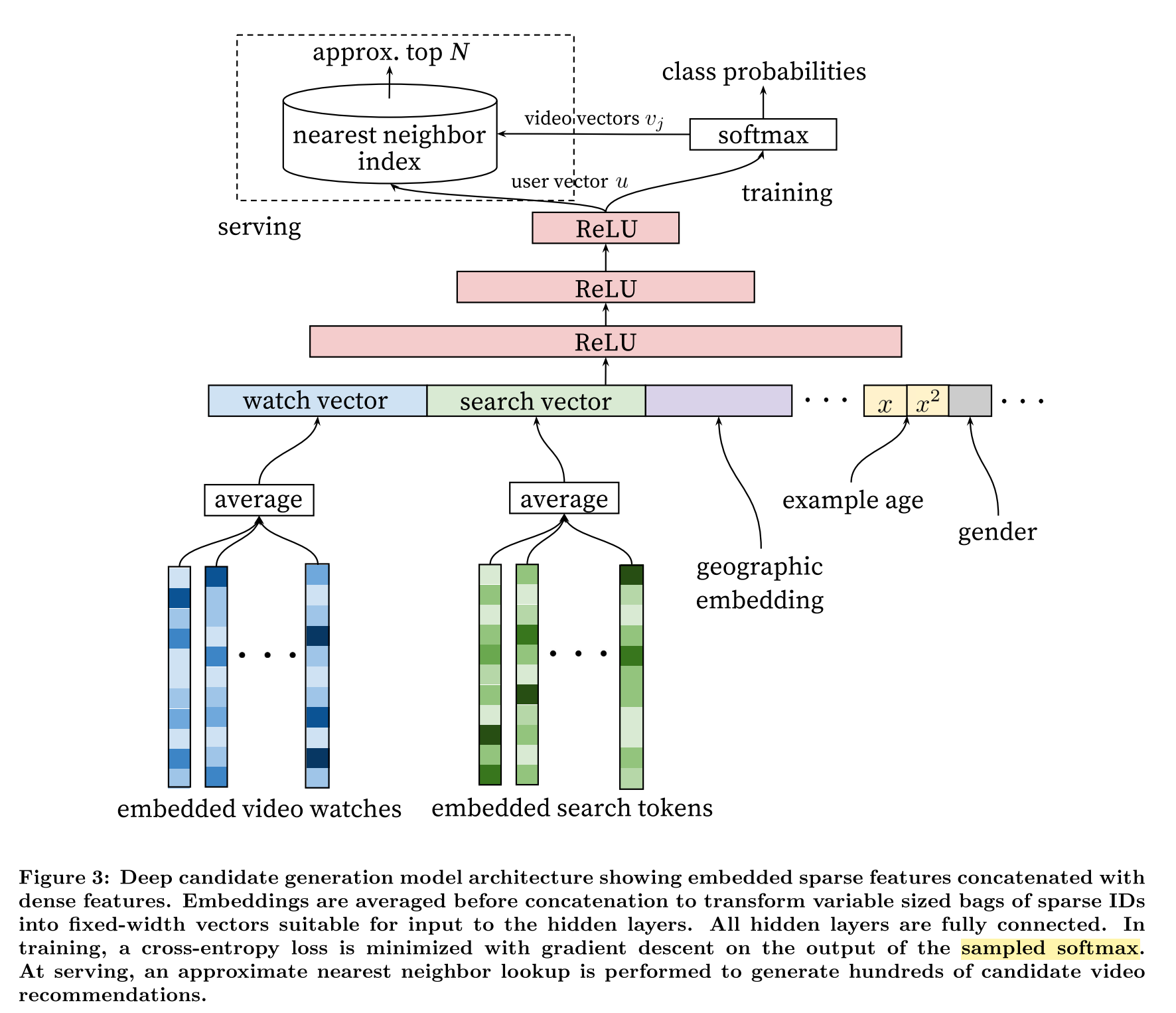 {: .align-center style=“width:80%”}
Youtube Candidate Generation网络结构
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
Youtube Candidate Generation网络结构
{: .align-caption style=“text-align:center;font-size:smaller”}
现在上面的图就比较清晰了,实际上输入层的视频embedding并不是在召回时使用的embedding。在做召回的时候,是把这个网络的输出层参数导入到一个向量检索引擎中,然后拿用户的embedding去query。正如论文中所说,这也是一种基于深度神经网络的协同滤波。
相比于NCF,这个工作着重挖掘用户的历史行为,不仅引入了id序列,还进一步引入了很多非id特征(在经典MF和NCF里,输入都只有user,item的id)。但这个网络user-item交互实际还是最简单的点积,虽然表现力不如NCF,但也让这个网络在做召回的时候更加实用。这种训练方式弊端也相当明显,最大的弊端我认为是必须使用fixed vocabulary,也就是item的范围是定死的,对于新鲜的item这个candidate generation模型就无能为力了。
双塔范式
时间来到了2019年,各种神经网络层出不穷,Youtube的推荐系统在3年时间里应该也进步了不少。这篇文章介绍了当时Youtube采用的双塔召回系统,这个系统已经和目前被广泛使用的结构差不多了。这个网络可以理解为是对上面2016年单塔网络的扩展,把item从简陋的输出层里提升到了独立tower建模的地位。这么做的好处有几个:
- 可以像user侧一样加入更多的特征
- 可以更容易处理冷启动。新的item来了也可以通过item tower获得表征
现在这种双塔结构不仅在召回时很常用,在排序的时候也经常用到。
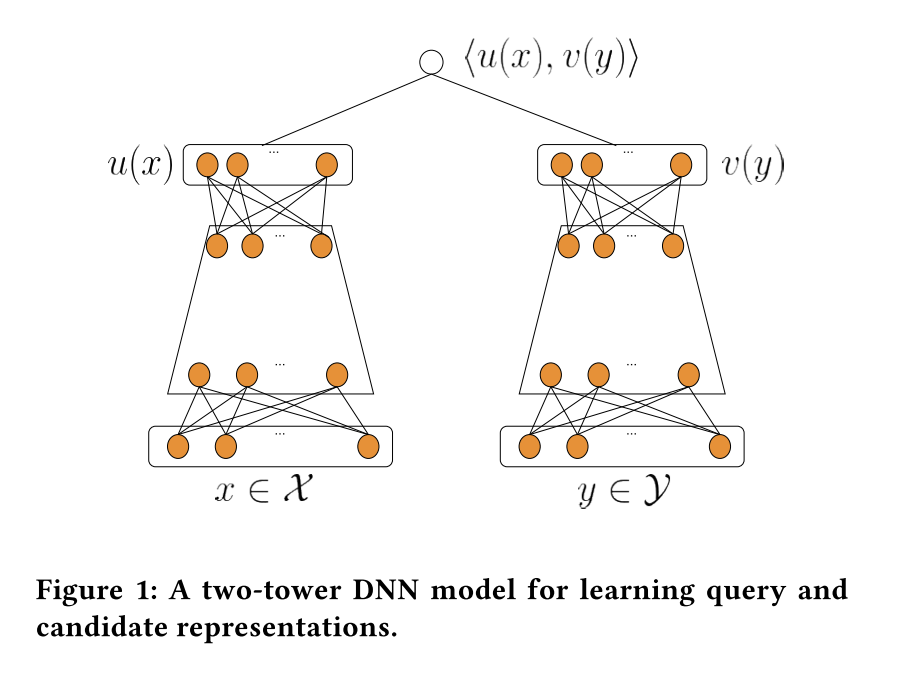 {: .align-center style=“width:80%”}
Youtube 双塔网络结构
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
Youtube 双塔网络结构
{: .align-caption style=“text-align:center;font-size:smaller”}
不过这篇论文的最大贡献并不是这个网络结构,而是一个流式场景下item frequency估计的算法。在推荐系统的模型训练中,由于正负样本不均匀、item和user出现的频率不均匀,给每条样本合适的权重是非常重要的事情,否则容易给系统引入bias,影响性能。
小结
CF算法诞生几十年,其变种和引申很多。在做召回的时候,基本上思路还是通过对交互数据的学习尝试获得user和item的embedding。只不过输入的特征从最开始的id已经扩展到了序列和其他特征,用来做编码器的模型也从越来越复杂。如果是做召回,user-item的交互部分不宜太重,否则难以使用;如果做排序则可以在这部分多加强,提升模型表现力。
随着CV、NLP技术的发展,内容的相似性已经可以很好地用算法评估,这也意味着CF算法可以更多地用上内容信号。但是在实践中发现,通过交互信号学习出来的user、item表征往往在性能上还是有优势。基于内容信号的CF更适合冷启动等交互不足的场景。
以上就是我对协同滤波引申出来的各种算法的一个学习总结,希望对你有帮助。