我的想法是剽窃、作弊成灾是会的,但扼杀人类的内容创造力是不会的。
首先人工智能模型造成剽窃、作弊的现象是近几年才出现的新情况,这也是模型水平进步的一个表现。而且,这种模型导致的剽窃和作弊相比于原来的形式还有比较明显的差别。要理解这件事情,还需要稍微了解一下这些模型的训练方法。
以ChatGPT为例,它最重要的一个环节是语言模型的预训练。它所依赖的语言模型是来自OpenAI的GPT-3.5。以他的前身GPT3来说,训练这个模型的数据来源如下
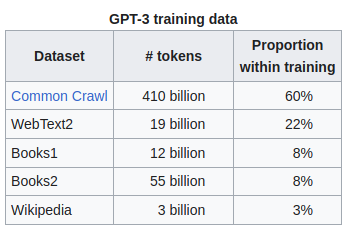
来自https://en.wikipedia.org/wiki/GPT-3#GPT-3.5
从表里可以看到,即使是让普通人觉得已经无所不包的维基百科只占到了训练数据的3%,可见训练一个顶级的语言模型需要多少数据。训练的过程有点像填字游戏,让模型看一小段文本,让它猜测后面接着的文本是什么。是不是有点像人类的背诵?
而这么巨大的训练语料就意味着这个模型可能阅读过这个世界上相当大比例的文本,不管是书籍、论文还是博客文章,甚至是代码片段,这也是为什么ChatGPT可以有如此令人惊艳效果的原因。它看过的这些文本,最终是形成了一个巨大的概率分布,例如看到“世界”,它会知道后面也许会跟着“杯”或者“地图”,它们有着不同的概率。
所以这种模型的剽窃和作弊是隐性且抽象的,需要人类用问题把模型的知识“钩”出来。虽然稍微不一样的钩子就有可能从模型钩出很不一样的结果,但由于这写结果本质上都符合模型训练时语料的概率分布,所以很有可能就会触发剽窃和抄袭。这确实是一个两难的问题,如果没有这海量的训练数据,就没有令人惊艳的模型,但这么大量的数据要把版权问题搞得清清爽爽也绝不是一件易事。
但对人类创造力的扼杀的担心我觉得大可不必。首先,模型暂时还没有实时进化的能力,ChatGPT的训练数据停留在2021年,它并不知道2022年底中国会突然放开防疫政策,那以此为题材的创作显然与他无缘。
其次,真正的创造欲望和创造力哪会因为创作之后会有人剽窃就减弱?那是一种使命感,是不吐不快的感觉。
大家都知道保护知识产权有利于激发社会创新创造,但近几十年来的开源运动也证明了这不是唯一的路径。在人人为我我为人人的开源软件世界,这种开放反而极大地促进了技术的进步和传播。说不定以后在AI模型领域也会有这样的运动,人们贡献出自己产生的语料供模型学习,然后用适当的license系统保证产出的模型可以被合理、公平地被使用。
我在知乎的原回答