Went to the Silicon Valley 101 Alignment conference today. After being a listener for several years, I finally saw Jane and Qian in person. Did not expect the scale to be this big—absolutely packed, and not just Chinese attendees; plenty of international friends too. As Xiaodi Hou said: Silicon Valley really is the promised land. The collective hunger for new tech and new chances is just awesome.
Got quite a lot out of today. First, I was struck by how dramatically their subscriber numbers have grown since ChatGPT launched. A few days ago I also peeked at the stats for “数字生命卡兹克” (Digital Life Kazik). Nowhere near Silicon Valley 101’s level, but still clearly a beneficiary of the AI Eastward Rise narrative. As a half‑hearted tech content creator and a somewhat vague AI practitioner, it’s hard not to feel I’ve let time slip by. On the other hand, being involved in a content product that hasn’t grown for years feels even worse. This AI content wave is absolutely open to us—and honestly quite suitable—but our “bucket + luck” style (throwing things at the wall) means we haven’t even crossed the threshold in properly framing and executing on content.
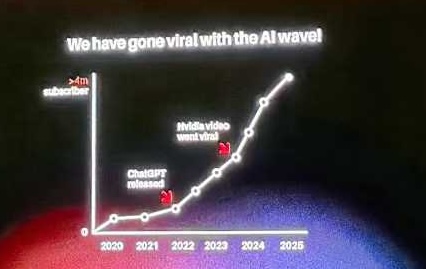
A few panels (and viewpoints) that really stuck:
- The first panel—what Yubei said about data efficiency was intriguing. If learning efficiency gets high enough (human‑like), then each person can have their own AI (because everyone’s data is different). It does feel like thinking machines are drifting in that direction?
- Bill’s reinforcement learning panel. First: Bill is noticeably rounder than his Zhihu avatar. This panel was the most detailed. Zheng Wen was basically “I agree” for the beginning, but in the final outlook segment: two thirds of the guests felt hierarchical reasoning has a promising future. Process reward might resurrect? Overall it sounded like there aren’t many active contrarian takes in RL right now. Although I did a fair bit of SFT early on, never pushing further into RL remains one of my bigger regrets. Need to find a window to patch that gap.
- Mu Shen’s keynote had a lot of substance. First time I’ve heard him live; honestly his onsite delivery felt a bit weaker than his recorded deep‑dive videos. Points like: even with vertical models you still need to keep general task performance from dropping too far; and how AI easily makes mistakes in fine‑grained QA systems—all of that aligns with what I’ve seen in past work. Their final metric curve was eye‑catching too: catching GPT‑4o in six months, surpassing specialized humans in eight. That pace feels quite reasonable to me: faster would probably be unrealistic (or valueless); slower and a startup can’t survive. So dear founders: after you define the problem sharply, set the expectation that the team gets 6–8 months to build.
- Xiaodi Hou’s keynote was the quirkiest—big theme: how to survive after the hype. First time hearing him as well. Very compelling. Similar energy from Yuanming Hu on the panel. They’re both still young but have already been ploughing their fields for years, riding through peaks and troughs. At that stage, focus and persistence start to radiate value. Echoing Silicon Valley 101 itself: years of accumulation, then a surge. Looking back at us—we’re actually on a decent track, but randomly hammering at everything means we’ve produced basically nothing.
New Tech & New Products
This week’s Product Hunt felt a bit bland. The #1 product positions itself as “lovable for slides”—almost vertical for the sake of being vertical. Is making slides lovable really that hard? That framing alone lowers the perceived ceiling. Strata—the MCP product—feels like it’s growing out of emerging consensus around tool calling, and it does target a real pain point. Buried inside is a lot of technical surface area. Doing:
One MCP server for AI agents to handle thousands of tools
properly is not trivial. But I’ve always been skeptical about MCP’s actual value. Any rigorous agent developer will pour time directly into Tools. Adding an MCP layer adds little. And nobody is seriously running “thousands” of tools. If you can wield a few dozen well, you’re already extremely strong.
Thinking Machines released something called Tinker—a post‑training platform. I get the sense that with the release of some high‑quality open models lately (e.g. OpenAI OSS, Qwen Next, etc.), post training is heading into a new spring. I believe base model capability inevitably hits a slow‑growth plateau. At that point—like Yubei said—non‑public, personalized data becomes more valuable. Combined with a rising floor of open models, post training becomes more effective. He only talked about training efficiency; using LoRA for serving efficiency is indeed a solid approach. You can’t realistically deploy a pile of “slightly different” full models—GPU memory efficiency would be awful. It’s plausible the next generation of OpenRouter evolves from standardized model routing into supporting personalized model deployment + routing.
Planting a Flag
I’m starting a “Weekly AI Observations” series: at least one post per week. This AI era changes daily—too much worth recording and sharing. Please keep an eye on me, and critique freely.