上班路上听了号称线性注意力之母的Songlin Yang的一期播客,小姐姐在里面科普了线性注意力的原理。最近这个结构非常火,特别是国内几个一线大模型厂商都在押注这个赛道。我觉得有必要用自己的话把这件事再说一遍。
一个Token是怎么生成的?
为了简单起见,我们聚焦在大语言模型的推理阶段——通俗点讲就是普通用户向大模型提问这个场景。假设用户问了这么一个问题:“我想元旦去看雪,有什么地方推荐的吗?“用过大模型的人都知道,接下来大模型就会开始一个字一个字地回答你。
大模型回答的每一个字,都可以拆解成以下几个阶段:
1. Tokenization(分词)
简单讲就是把人类的语言变成一串数字,每个数字都是一个编号。比如上面那个问题在ChatGPT处理前会转变成这样一串编号:[37046, 33565, 111, 24186, 6079, 99…]。你会发现这个编号序列的长度和用户输入的问题长度不一样,这是因为这个过程可能会对一些字词进行合并或拆解,不过这个小细节跟我们今天的主线关系不大。
2. Embedding(嵌入)
这个过程很重要也很简单,可以理解成查字典。拿上面的编号去查一个大表,每个编号都会对应一个很长的向量,用来在所谓的"语义空间"表示这个编号代表的token。 理解清楚向量是什么需要一定数学背景,但它起到的作用其实很直观。比如"苹果"和"香蕉"两个词语的编号可能差得很远,一个是888,一个是6666,中间差了几千个别的词,这些词也不知道是些啥,可能是"硅谷”、“大模型"这些跟水果一点关系都没有的词。但变成语义空间的向量就不一样了,好的语义表示可以让近义词的向量之间距离近,无关的词之间距离远,甚至还可以做一些运算。
经典例子是在向量空间里"皇帝”-“男人”+“女人"约等于"皇后”。用这个例子应该能让embedding起到的作用更直观。这个很大的表在模型训练好后是固定的。
3. Transformer处理
Transformer这个词,以往的大众媒体宣传都在借用变形金刚的形象,可能是因为比较酷。其实人家的本意更接近变压器,是在把输入的信息转变成另一种形式来输出。现在的大模型会堆叠好多层的Transformer,也就是做好多次变换,但每一次其实原理都一样。
这个过程有两个重要的步骤:
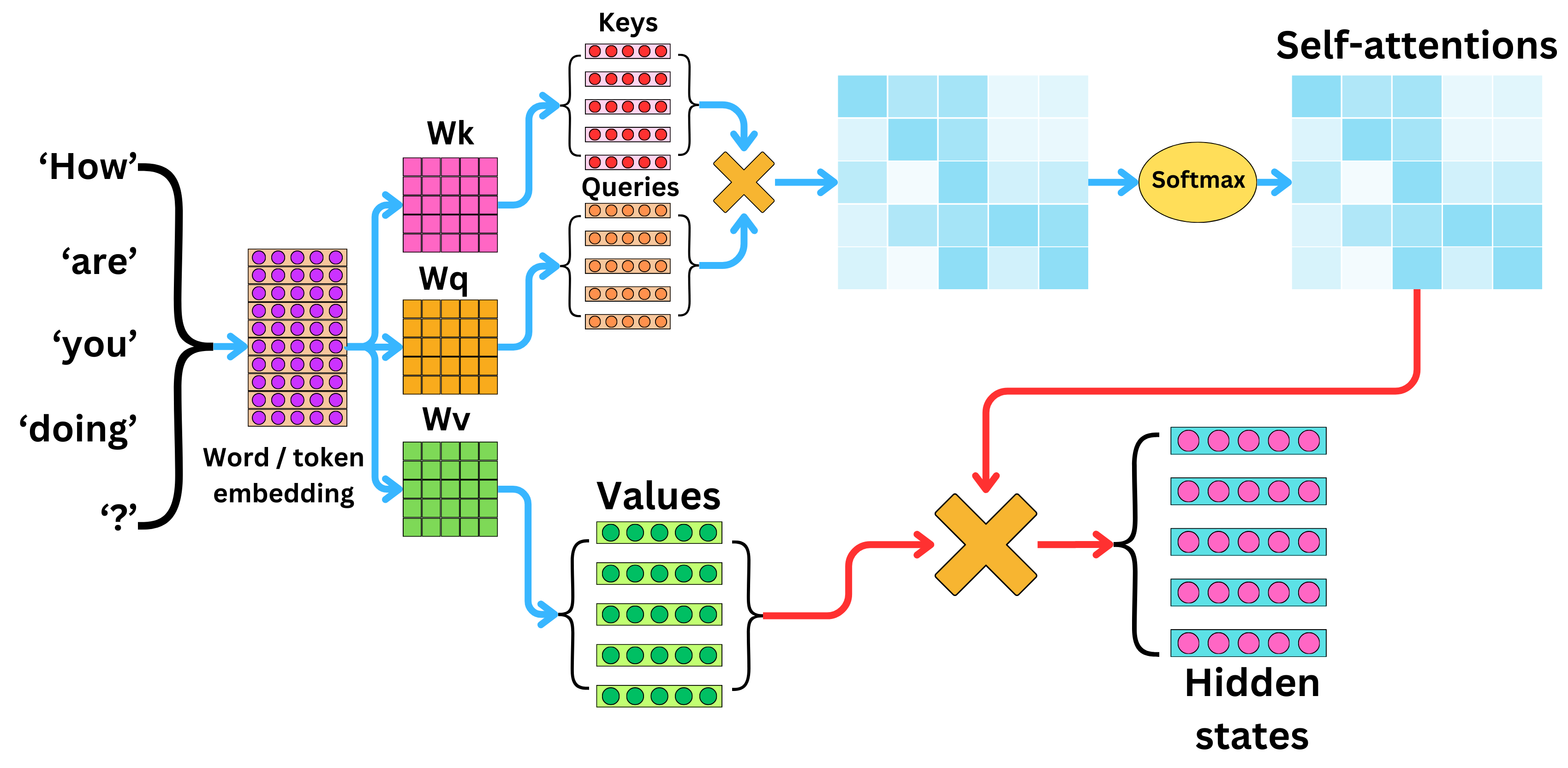
第一步:Self Attention(自注意力机制)
大名鼎鼎的自注意力机制,也是本公众号名字的由来。名字很玄乎,做的事情说起来却很直观——把当前上下文中与生成下一个token最相关的信息聚合起来。 具体地说,我们在上一步已经把每个token都转化成了embedding向量。假设当前上下文的长度是L,embedding的维度是d,那就变成了一个$L×d$的矩阵。首先,会对这个矩阵做三种不同的变换,数学上就是乘以三个不同的矩阵,得到三个变换后的矩阵Q(query)、K(key)、V(value)。
现在我们取出第L个Q向量(也就是最后一个)去和1L-1个K里面的向量分别计算相似程度。算完之后我们可以取出最相似的那个K向量对应的V向量来作为预测下一个token最有用的信息。但这种取max相似的做法太生硬了,所以用了一种叫softmax的方法——按照和第L个K向量的相似程度把1L-1个V向量加权求和起来。
可想而知,为了做这个加权求和,我们要做L-1次向量点乘。每生成一个字就要做L-1次,如果生成总长度为n,那这个计算量的量级就是n的平方。现在的大模型已经会思考了,随便就能给你生成几千上万个token,这个计算量就非常巨大了。
第二步:FFN(前馈网络)
这一步不是本文重点,是对上面算出来的聚合后的上下文向量做一些变换。用的网络结构叫前馈网络FFN。因为生成下一个token只要处理一个向量,所以计算耗时不大。 但这个网络也很重要,实际上是大模型的全局记忆或永久记忆之所在(自注意力主要是在操作上下文,是工作记忆)。其特点是参数量特别大,因为参数量越大,可以记忆的东西就越多。但参数大也会带来计算量大的问题,于是就有了MoE混合专家网络——把总参数量用很多个专家来撑大,但大家术业有专攻,每次只取几个专家来激活处理。在此先按下不表,有兴趣的朋友可以自行扩展阅读。
4. 输出Token
对变换后的向量,再通过一个分类器分到token集合上,取出概率最大(根据采样方式不同也可以不是最大的)的那个token作为这一步的输出。
如何串起来?
这个也比较容易理解。当用户输入问题之后,我们走完上面的流程就会得到一个新的token。然后我们又可以拿它的id去查embedding,对这个embedding做qkv变换,然后拿这个q去和1~L的k去做softmax拿到聚合后的上下文向量,再经过FFN和分类器就又得到了下一个token。如此循环,直到世界的尽头——啊不,直到输出停止token。
线性注意力解决了什么问题?
自注意力机制在这里最主要的问题是速度,因为O(n^2)的时间复杂度,随着模型输出变长,会越来越慢。
从上面的过程里聪明的你可能发现了一些讨巧的地方,那就是每个位置的token对应的QKV向量如果能保存起来的话,做一次embedding到向量的变换就可以一直用,一劳永逸,省下一些时间。
但这种方法是以空间换时间。GPU上的存储是很宝贵的,而且模型这么大,也需要占据很大的空间。所以现在大家就想办法把这个缓存搬到内存上,甚至是固态硬盘上。于是推波助澜了今年存储股的暴涨(参考镁光、SanDisk以及国内的兆易创新)。
线性注意力就是要解决这个问题。总体的框架并没有变,但是做了一些关键的修改。首先就是把softmax这个函数给干掉,于是这个上下文计算变成这样:
$$ \begin{aligned} &&&&\mathbf{o_t} = \sum_{j=1}^t \mathbf{v}_j(\mathbf{k}_j^\top \mathbf{q}_t) &&&&& \mathbf{k}_j^\top \mathbf{q}_t = \mathbf{q}_t^\top \mathbf{k}j \in \mathbb{R}\\ &&&&= (\sum_{j=1}^t\mathbf{v}_j\mathbf{k}_j^\top)\mathbf{q}_t &&&&&\text{By associativity} \end{aligned} $$于是可以发现,整个过程可以逐步计算得到了,每一步的计算复杂度跟当前的长度无关,只跟V和K的大小有关。同时,因为括号里的东西是累加的,我们可以不用记录历史的kv了,KV cache完全不需要了。假设称括号里的东西为状态矩阵:
$$ \mathbf{S} = \sum \mathbf{v}_i\mathbf{k}_i^\top $$
但天底下没有免费的午餐,这种向RNN一样的更新方式会让1~L-1的上下文"糊掉”,因为全部东西都坍缩到一个大的状态矩阵里去了。
假设我用1~L里的某个位置j的key向量去从原始版的kv缓存里用max取最相关的v,我一定能取出$v_j$,因为自己和自己一定是最像的。softmax会让事情模糊一些,但总体还好。但如果从S里取,则会有以下结果:
$$ \begin{aligned} \mathbf{S}\mathbf{k}_j &= \sum \mathbf{v}_i (\mathbf{k}_i^\top \mathbf{k}_j) \\ &= \mathbf{v}_j + \underbrace{\sum_{i\neq j} (\mathbf{k}_i^\top \mathbf{k}_j)\mathbf{v}_i}_{\text{retrieval error}} \end{aligned} $$理论上就会有后面那坨噪音,除非任意两个不同位置的k向量都是正交的。但是如果我们的向量是d维的,那理论上正交向量最多只有d个。毫无疑问,在上万、十万甚至百万的上下文长度面前,我们很难有一个足够大的$d$。
所以上面这种简单的线性注意力比self attention性能差远了。但经过一系列的改进,已经有了长足进步。很多国产模型也都用上了这种结构来提升模型长上下文的处理能力。而且,不用存kv cache的话一下子就把存储的很多需求打掉了(d×d vs L×d,长上下文时L»d)。特别声明,以上公式都是直接从Sonling Yang介绍DeltaNet的博客抄的。听完播客去看了下她的知乎和博客,确实后生可畏,大家也可以去看看。
AI泡沫和中美竞争
每次技术的变化都可能会催生一些AI鬼故事。
25年初DeepSeek号称500万美元就完成了训练(他们用了另一种方式来省kv cache),一度让英伟达暴跌。这次用线性注意力的Kimi K2已经只要460万美元了,结合其他一些因素,最近AI泡沫要破裂的传闻又有卷土重来之势。
我个人对AI的发展还是比较乐观的。AI的用量还有很大的空间,现在算力也真的还蛮紧张的。之前我们想让某公司给我们提高rate limit,其waitlist竟然长达六个月,主要原因是盖新的数据中心需要时间。但万物皆有周期,等到目前在建的数据中心都落成的时候需要再观察供需关系。
另一个最近常出现的话题是中国AI超过美国AI。我感觉这在技术上(综合效果和效率)应该是可以预期的。
早在两年前,好多大佬都会认为AI未来是commodity(我理解是像水、电这样的标准化必需品)。那就有理由相信制造业的故事会在AI领域上演。但制造业的故事并不是一个完美的喜剧。
Kimi K2最旗舰的模型现在API的价格每百万token输入/输出是4/16元人民币。对比之下,OpenAI的顶级模型是12/120美元,OpenAI的旗舰模型是1.25/10美元。价格上是有数量级上的差异——输入和Kimi差不多,输出比Kimi贵4-5倍。
这里Kimi的价格优势当然有一部分是因为前面提到的技术路线优势带来的,但同样肯定也是定价策略的因素。我不知道里面有没有摊上研发费用,因为模型是开源的,肯定有很多第三方推理服务商会跟进上线。对美国厂商而言,Llama拉胯之后,中国厂家Qwen、Kimi、Minimax简直是衣食父母。但没有研发费用的推理商成本上就会有很大的优势。
我总觉得大模型开源这条路在商业上比较难评价,但为了打国际市场,特别是美国市场,开源又是中国厂商为数不多的几个选择之一。至于为什么非要打国际市场特别是美国市场,我认为逻辑其实和制造业是一样的,失去这块市场的结果,大家这几年应该也有体感。
以上就是本周的观察。前半段技术内容基于客观规律和事实,后半部分纯属一家之言,仅供参考。