It’s the first day of Thanksgiving break—thanks for reading. Last week’s vibe coding interview piece became my most-read article ever, thanks to Ruanyifeng for featuring it in his tech weekly.
This week I want to talk about model selection for AI apps at the end of 2025. It’s critical: it drives both quality and cost. Don’t shrug off the difference between $0.20 and $0.25 per million tokens—that’s a 25% gap. If a candidate can rattle off capabilities, pricing, and quirks of today’s mainstream models, that’s a big plus in my book.
How to Use OpenRouter
OpenRouter is a handy reference for what people are trying, but its rankings diverge a lot from real usage.
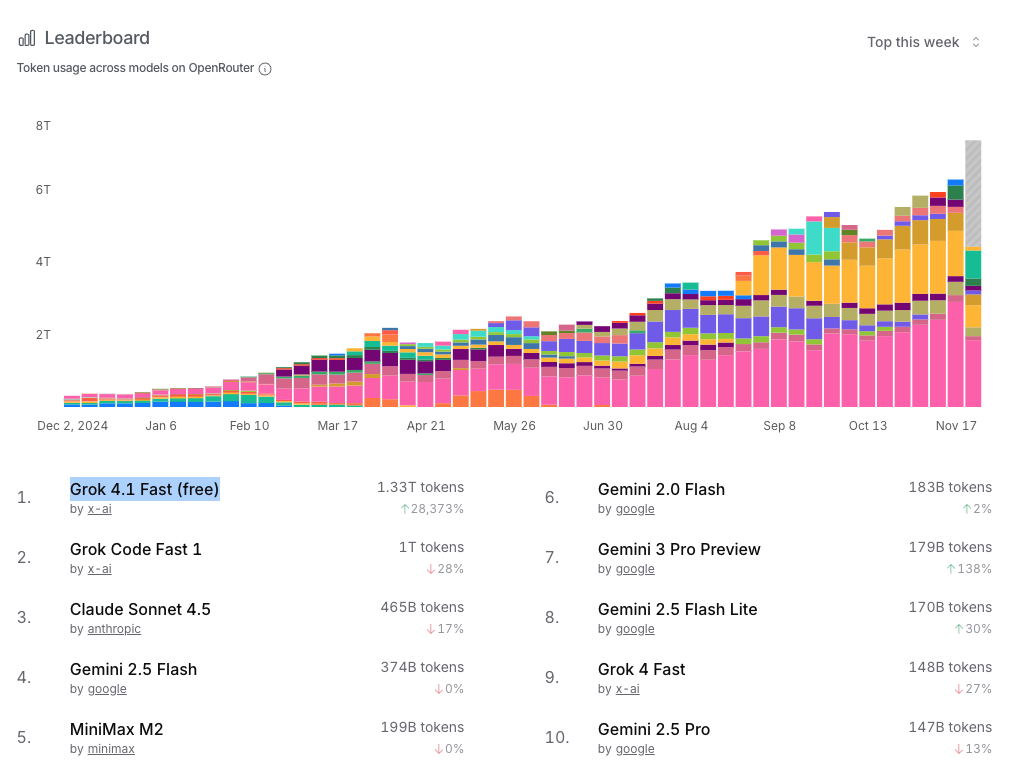
Plenty of models come with free tokens; once it’s free, usage spikes—see Grok 4.1 Fast (free) at the top. Many OpenRouter users are devs; the top apps make that clear. And serious production apps rarely run there because of the 5.5% fee—middleman margin is pure overhead.

A Quick Reference Table
I pulled together the models I watch most. The full sheet isn’t great to share on WeChat, so here’s an image. I’m focusing on text models—even if some are multimodal—and only on base models, not finetunes. Among the big three, Anthropic is the priciest overall; even their “medium” tier beats the flagship price of the other two. The flip side: their monthly plan is the best value (heavy API use for Claude Code can burn dozens of dollars per day easily).

Pick the Right Cup Size
Serious closed-source vendors offer small/medium/large tiers. OpenAI has nano, mini, and numerically named models; Anthropic has haiku, sonnet, opus; Google has flash lite, flash, pro; Alibaba has flash, plus, max. Newer vendors with thinner product lines, like X.ai, may just have “fast” and “not fast.”
From experience: large models fit user-facing needs—chatbots, AI agents (e.g., coding). Small/medium models fit offline tasks like data processing and workflows. Running large models at scale will bleed your wallet, so think hard before launch.
Upgrade with the Vendor
Within one vendor’s lineup, always upgrade alongside them. At OpenAI, anyone still on GPT-4o in November 2025 deserves at least a warning, maybe the door.
Look at the numbers: GPT-4.1 is roughly 20% cheaper than GPT-4o on input/output and half price on cached tokens. As models improve, you often see 4.1-mini matching 4o quality—at under 20% of the cost.
Thinking vs. Non-Thinking
Balance thinking and non-thinking models.
GPT-5 is an oddball—everything thinks, and you can’t turn it off. Simple tasks might burn 400 thinking tokens; complex ones, thousands. Thinking tokens are billed as output. If your output is short, you might be spending more on “thinking” than words.
GPT-5.1 fixed this: you can skip thinking. If your prompt already includes a chain-of-thought, don’t let the model freewheel; choose a non-thinking variant and pocket the savings.
Cache Hit Rate
Input/output pricing and cache hit rate matter a ton. Build internal cache monitoring and push hit rates as high as possible. Cache hits often price at ~10% of list, which slashes cost.
If your input/output ratio is high, favor models with cheaper input; if output dominates, pick models with cheaper output. Output is usually several times input, but the multiplier varies. OpenAI/Google are ~8x, Anthropic ~5x, Kimi ~3x, and X.ai is a quirky 2.5x.
Throughput Polarization
Throughput is critical and now highly polarized. OpenAI/Google APIs tend to run tens of tokens per second. Some ASIC inference vendors hit thousands per second—but you’re usually limited to a handful of open-source models.
That speed difference is huge, though most users haven’t felt it. Everyone streams chatbot answers because a full response can take tens of seconds; streaming makes the wait tolerable. TTFT (time to first token) is a key metric.
Boost speed by two orders of magnitude and the whole answer arrives almost at once. We still stream, but the user can’t tell. If Claude Code currently spends five minutes on your task, an ASIC-backed setup might take five seconds—the model finishes before you finish describing the request. :P
The Sweet Pain of Rate Limits
Rate limits are a good problem; they mean you have steady volume. For GPT-5.1, Tier 1 allows 500k TPM and 500 RPM. If your prompt is 10k tokens—tiny for agentic apps—you can only handle ~50 requests per minute. Tier 5 bumps limits by ~80x, which is usually enough. Many “neo cloud” vendors keep limits low—they lack the burst capacity of the big clouds.
If you’re Tier 5, you’re likely burning serious money—tens of thousands per month on tokens—so cost discipline becomes vital.
Practical Trade-off: 5 nano vs. 4.1 nano
We use a lot of OpenAI models and are generally happy. Under $0.10 per million input tokens, they’re solid. The $0.05 5 nano isn’t bad—open-source models at that price are typically ≤8B parameters and underwhelming unless finetuned.
Let’s compare 5 nano (thinking) vs. 4.1 nano (non-thinking): inputs are $0.05 vs. $0.10; outputs are both $0.40. Assume medium reasoning effort—about 500 thinking tokens. The cost outcome depends on output length and input/output ratio.
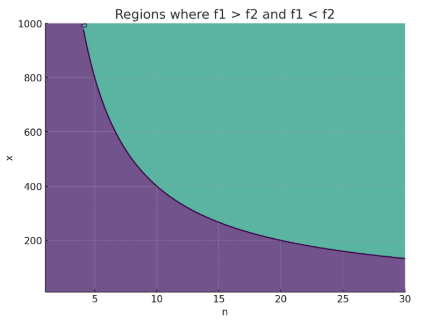
On the chart, the x-axis is input/output ratio: higher favors 5. The y-axis is output tokens: longer outputs favor 5. If outputs are short, thinking overhead makes 5 nano pricier than 4.1 nano; if outputs are long, thinking overhead is small and 5 nano’s input advantage wins. Cost depends on your workload—pick accordingly.
Wrapping Up
Model selection ultimately depends on your workload. There’s no “best model,” only the best fit. My checklist:
- Understand your task profile (input/output ratio, depth of reasoning needed).
- Instrument cost monitoring (especially cache hit rate).
- Review regularly; upgrade with the vendor.
- Don’t worship large models—small/medium often deliver the best value.
China’s market differs from overseas. I’d love to hear how you pick models for AI apps—drop a comment.