最近AI大火,作为一名稍微有点赶不上趟的NLP工程师,感觉有很多课需要补。恰好昨天Meta发了新的大模型论文,浏览了一下发现很适合作为补课的切入点。
今天这部分是关于预训练使用的数据集,是重中之重,说数据是当代AI的基石一点也不为过。GPT3用的数据其实没有公开,Meta这次论文里提到的应该算是开源模型里一个最全的版本。他们使用的数据如下表所示,我们一一来看一下。
| Dataset | Sampling prop. | Epochs | Disk size |
|---|---|---|---|
| CommonCrawl | 67.0% | 1.10 | 3.3 TB |
| C4 | 15.0% | 1.06 | 783 GB |
| Github | 4.5% | 0.64 | 328 GB |
| Wikipedia | 4.5% | 2.45 | 83 GB |
| Books | 4.5% | 2.23 | 85 GB |
| ArXiv | 2.5% | 1.06 | 92 GB |
| StackExchange | 2.0% | 1.03 | 78 GB |
CommonCrawl
占比最大的数据集,他们的网站是https://commoncrawl.org/。我感觉这真是一个伟大的项目,7年时间爬了超多的互联网网页,涵盖了40种语言。
 CommonCrawl网站截图
{: .align-caption style=“text-align:center;font-size:smaller”}
CommonCrawl网站截图
{: .align-caption style=“text-align:center;font-size:smaller”}
根据他们博客的最新数据,2023年二月版的数据包含了400TB的数据(纯文本的数据是9个多tb),三十多亿个网页。
The crawl archive for January/February 2023 is now available! The data was crawled January 26 – February 9 and contains 3.15 billion web pages or 400 TiB of uncompressed content. Page captures are from 40 million hosts or 33 million registered domains and include 1.3 billion new URLs, not visited in any of our prior crawls.
而LLaMa里面CommonCrawl的数据只有3个多TB,大概是总数据量的三分之一。可见数据的后处理工作量是相当大的。
We preprocess five CommonCrawl dumps, ranging from 2017 to 2020, with the CCNet pipeline (Wenzek et al.,2020). This process deduplicates the data at the line level, performs language identification with a fastText linear classifier to remove non-English pages and filters low quality content with an ngram language model.
C4
占比第二大的数据集是C4,他的全称是Colossal Clean Crawled Corpus(4个C,所以叫C4)。这个数据集是在CommonCrawl数据集的基础上后处理而来。
根据C4官网的介绍,用500个worker处理CommonCrawl数据集得到C4数据集需要大约16个小时
The C4 dataset we created for unsupervised pre-training is available in TensorFlow Datasets, but it requires a significant amount of bandwidth for downloading the raw Common Crawl scrapes (~7 TB) and compute for its preparation (~335 CPU-days). We suggest you take advantage of the Apache Beam support in TFDS, which enables distributed preprocessing of the dataset and can be run on Google Cloud Dataflow. With 500 workers, the job should complete in ~16 hours.
Github
第三占比的是Github数据集,这个在多年以前的预训练语言模型例如BERT、GPT里几乎没有人用。之前似乎看过一种说法是代码数据的加入对语言模型的逻辑推理能力有极大的帮助。这个点后面计划专门花点时间学习。
Wikipedia
维基百科数据因为质量高、覆盖面广是预训练语言模型的常用语料了,多年之前大家就爱使用。和Books数据集一道基本是预训练语言模型的标配。这里有一个很有趣的数字是整个维基百科的数据量只有不到100GB,甚至比github上的代码还少,这可是人类很大一部分知识啊。
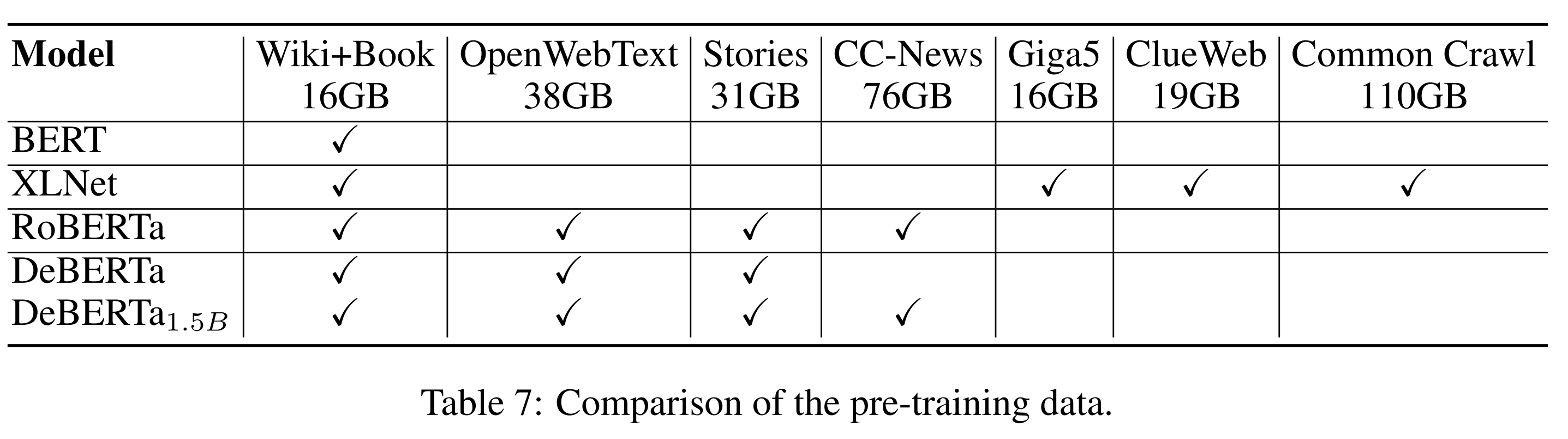 Deberta论文里不同预训练模型使用数据的对比。所有模型和2023年的大模型比数据量都小了一个量级
{: .align-caption style=“text-align:center;font-size:smaller”}
Deberta论文里不同预训练模型使用数据的对比。所有模型和2023年的大模型比数据量都小了一个量级
{: .align-caption style=“text-align:center;font-size:smaller”}
Books
论文里的books数据集特指books3,这个数据集没有特别正式的官网,其介绍出现在一个github issue里。根据作者的介绍,它包含了约20万本书籍。
books3.tar.gz (37GB), aka “all of bibliotik in plain .txt form”, aka 197,000 books processed in exactly the same way as I did for bookcorpus here. So basically 11x bigger.
这个数据集也是社区共同努力的结果
This is possible thanks to two organizations. First and foremost, thank you to the-eye.eu. They have a wonderful community (see discord), and they are extremely interested in archiving data for the benefit of humanity. Secondly, thank you to “The Pile”, which is the project that has been meticulously gathering and preparing this training data. Join their discord if you’re interested in ML: https://www.eleuther.ai/get-involved
略显讽刺的是,以Open命名的OpenAI却没有公开他们在论文里使用的Books2数据集。
books3.tar.gz seems to be similar to OpenAI’s mysterious “books2” dataset referenced in their papers. Unfortunately OpenAI will not give details, so we know very little about any differences. People suspect it’s “all of libgen”, but it’s purely conjecture. Nonetheless, books3 is “all of bibliotik”, which is possibly useful to anyone doing NLP work.
ArXiv
这个数据集感觉也是最近几年才流行加到预训练语言模型里的。学术论文的逻辑性比较强,我估计这也和近年来模型的推理能力提升有密切的关系。
StackExchange
StackOverflow各位读者,特别是码农朋友可能更加熟悉,StackExchange可以理解为是它的超集。StackExchange包含有不限于计算机的各种各样不同领域的高质量问答。在LLaMA的训练数据里,Meta只保留了若干个子领域。
We kept the data from the 28 largest websites, removed the HTML tags from text and sorted the answers by score (from highest to lowest).
小结
我感觉除了Books以外CommonCrawl应该包含了剩下的其他数据集,Meta在训练的时候还显示地加入它们,是否等价于调整了数据的权重让高质量的网络内容出现地更多一些?论文中在C4数据集处有提到一点原因,说是加入不同预处理的数据有助于模型提升。
During exploratory experiments, we observed that using diverse pre-processed CommonCrawl datasets improves performance.
从这个角度看,要训练一个高质量的基础模型真的是有很多细节需要掌握,不是简单地堆数据、堆算力就能搞定的。
另外,我今天在微博上看到有人嘲讽说Meta一开源,国内的“自主创新”马上就要来了。但其实不难看出这个模型里中文语料的比例应该是很低的。首先最大头CommonCrawl只保留了英文,维基只保留了拉丁语系20种语言的内容,ArXiv和StackExchange上面本来就几乎没有中文。也就是说,中文基本只有可能比较大规模地出现在Books和Github这两块。如此说来,这个模型的中文水平应该不会好到哪里去,这个博主也有点为黑而黑的意思。
 {: .align-center style=“width:40%”}
国内模型将迎来共产主义?
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:40%”}
国内模型将迎来共产主义?
{: .align-caption style=“text-align:center;font-size:smaller”}
3年前GPT3的repo里有个按照语言统计的数据量,在文档维度,中文只占到了0.11631%。从这个角度,各位家长一定要坚持让孩子学好英文,即使将来人工智能真的到来了,最好的版本一定是用英文交互的。