上一篇文章介绍了大模型是用什么数据训练的,这一篇文章重点来看大模型的评价方法。Chatgpt这轮出圈很大原因是对话这种评价方式非常直观,普通大众就可以从对话质量看出来现在的模型比之前的"人工智障"要强很多。但真正开发大模型肯定不能用这种方式,不仅效率低、价格高,还存在不小的主观因素。这篇文章就来总结一下大模型的评价方式。
还是先来看LLaMA论文里使用的评价指标。LLaMA里一共使用了**20种数据集(或任务)**来评估和对比模型。这些任务可以分为两大设定:零样本任务和少样本任务,涵盖以下几个大类
- 常识推断
- 闭卷问答
- 阅读理解
- 数学推理
- 代码生成
- 大规模多任务语言理解
下面一一来看。
常识推断
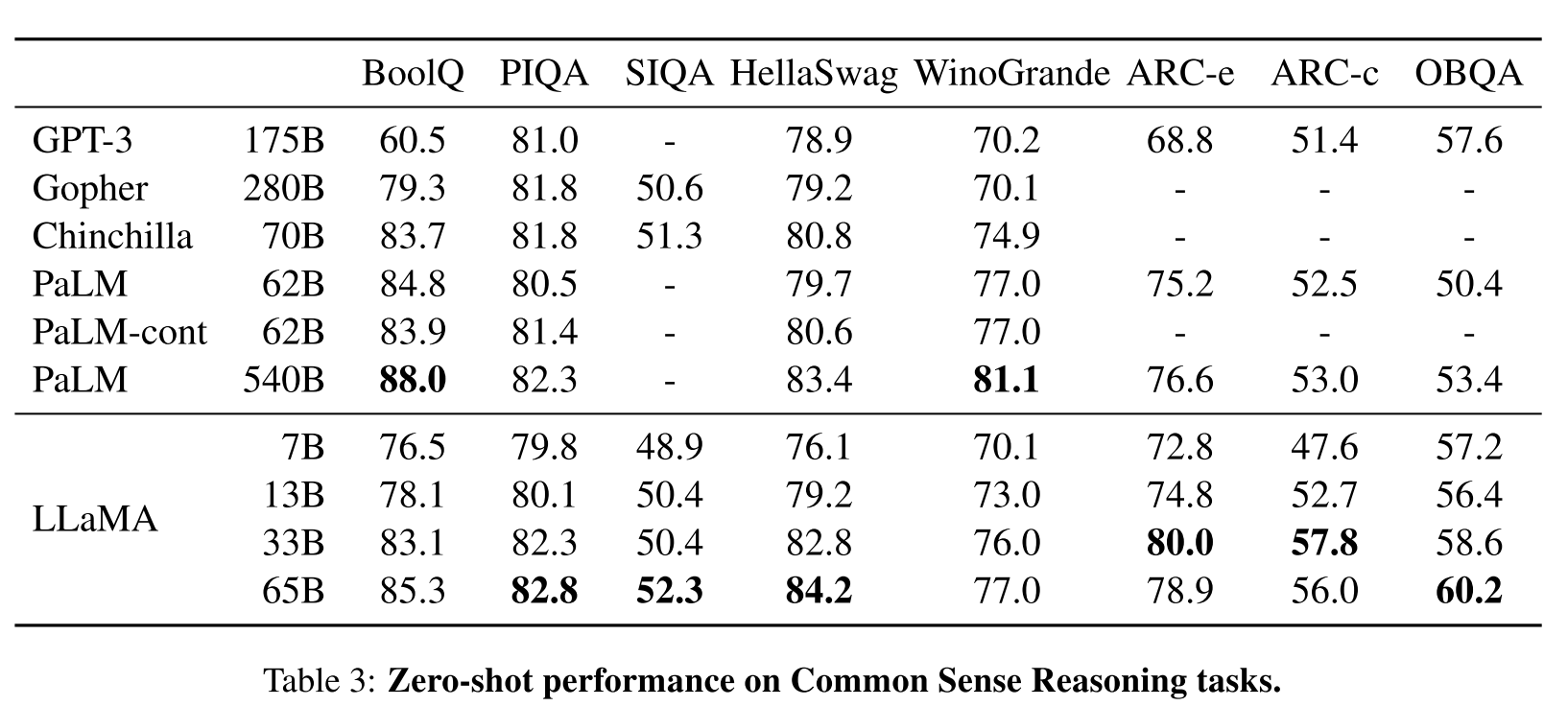
这个任务用了8个数据集,分别是BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC easy, ARC challenge和OpenBookQA。不同数据集有不同的形式,包括填空、威诺格拉德模式挑战(英语:Winograd Schema Challenge,缩写WSC)、多选问答。这些数据集在评价中都属于零样本,就是让模型通过预训练来直接回答问题。
一个威诺格拉德模式的例子为:“ 市议会拒绝给示威者颁发许可,因为他们[担心/宣扬]暴力。 ” 当这句陈述中使用“担心”一词时,前面的“他们”指的是市议会。而当使用“宣扬”一词时,“他们”所指的则变成了示威者。人类通过常识可以很简单地看出两种情况下“他们”所指分别为何,但对于机器而言这个问题则十分困难。
 {: .align-center style=“width:80%”}
不同模型常识推断结果比较。这种常识问题现在的模型基本都能对个六成以上。
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
不同模型常识推断结果比较。这种常识问题现在的模型基本都能对个六成以上。
{: .align-caption style=“text-align:center;font-size:smaller”}
闭卷问答
这个任务包括两个数据集Natural Questions和TriviaQA。所谓闭卷,是相对于数据集原来的设定来说的。已Natural Questions为例,原来的设定是模型可以访问相关维基百科文本,然后根据百科内容回答问题。然而在评价大语言模型的时候,就不给看这个维基页面了。闭卷问答包括zero shot和few shot两种设定。zero shot很好理解,跟上面的常识推断很像,下面是论文附录里few shot的例子,实际上就是列几个问答对作为context。我目前还不太懂这种无关问答对对模型回答问题有什么帮助。
Context → Answer these questions: Q: Who sang who wants to be a millionaire in high society? A: Frank Sinatra Q: Who wrote the book the origin of species? A: Target -> Charles Darwin
阅读理解
阅读理解和前面提到的开卷问答有一点像。只是常见的阅读理解数据集用于支撑问题回答的背景材料比较短(相比于NQ里的维基页面)。在LLaMA论文里,使用的是RACE数据集,这个数据集对于做过阅读理解的朋友一定不陌生,是为初高中中文学生设计的英语阅读理解题。
 {: .align-center style=“width:80%”}
RACE数据集样例
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
RACE数据集样例
{: .align-caption style=“text-align:center;font-size:smaller”}
数学推理
从这里开始都是比较有意思任务,感觉也是这一两年才开始有人搞。这个任务用了两个数据集MATH和GSM8k(OpenAI搞的数据集)。其中MATH数据集包含了一万多条初高中数学题,GSM8k是初衷数学题。特别注意的是MATH是用LaTeX写的,也就是说并不全是自然语言,而有点像代码阅读了。
 {: .align-center style=“width:80%”}
GSM8k样例
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
GSM8k样例
{: .align-caption style=“text-align:center;font-size:smaller”}
代码生成
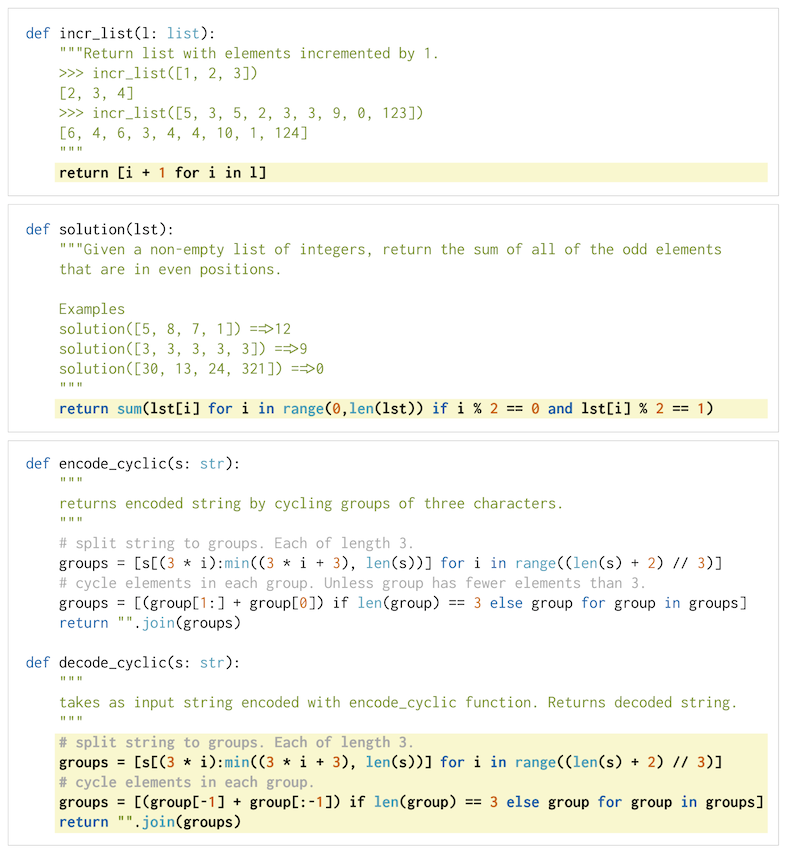
这是个令码农颤抖的任务,包括两个数据集HumanEval和MBPP,两个数据集都是2021年才出来的,非常新。两个数据集里模型输入都包含一个功能描述和一些输入输出样例,在HummanEval数据集里,函数的的定义也给出了。模型根据这些信息写一个Python函数,看能否通过测试样例。HumanEval也是OpenAI搞的数据集,看到这里,我感觉真的是被OpenAI的创造性折服了,贡献了这么多数据集真的是引领了行业的发展。下面是HumanEval数据集的一个测试问题。
 {: .align-center style=“width:80%”}
HumanEval数据集样例
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
HumanEval数据集样例
{: .align-caption style=“text-align:center;font-size:smaller”}
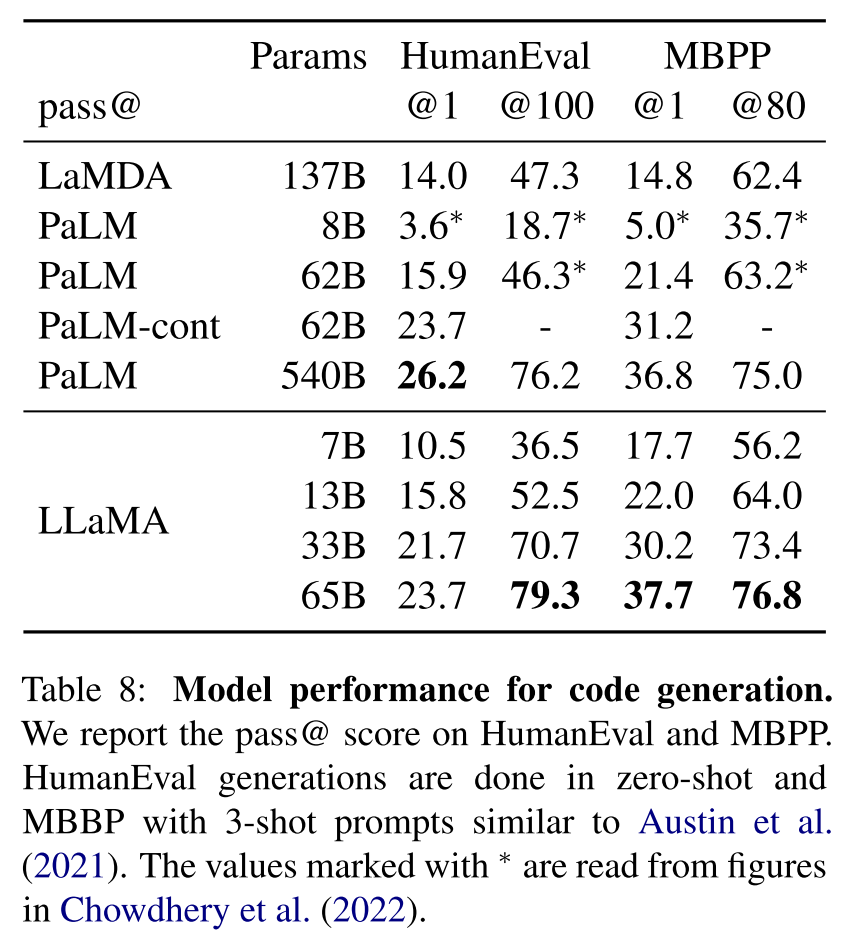
模型的评价指标称为pass@x。pass@1就是greedy生成结果的测例通过率。大家一定很好奇模型的水平到底如何,可以看下面这张图。总的来说,通过率还是挺低的,而且从上面的例子看问题也不算复杂。有意思的地方是pass@100是远高于pass@1的,pass@100是概率采样生成100次能通过的概率,这还真有点像我们写程序,多试几次总是能跑通的。。
 {: .align-center style=“width:80%”}
Code Generation结果
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
Code Generation结果
{: .align-caption style=“text-align:center;font-size:smaller”}
大规模多任务语言理解
这是一个2020年推出的数据集,名叫MMLU,是选择题的形式,内容包括了科学、社会学等等多个方面。在这个任务数LLaMA落后于Chinchilla-70B和 PaLM-540B,META的作者推测这是因为LLaMA的训练数据里书籍的数量比较少。参考上一篇文章,书籍和ArXiv加起来是177GB,而对标的两个模型使用了足足2TB之多的书籍数据。
 {: .align-center style=“width:80%”}
MMLU数据集样例
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
MMLU数据集样例
{: .align-caption style=“text-align:center;font-size:smaller”}
这个数据集的Few-shot形式和前面也类似,就是放几个给出答案的问答对,再跟一个需要模型回答的问题,然后留一个空。
 {: .align-center style=“width:80%”}
MMLU Few-shot设定
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
MMLU Few-shot设定
{: .align-caption style=“text-align:center;font-size:smaller”}
训练对指标的影响
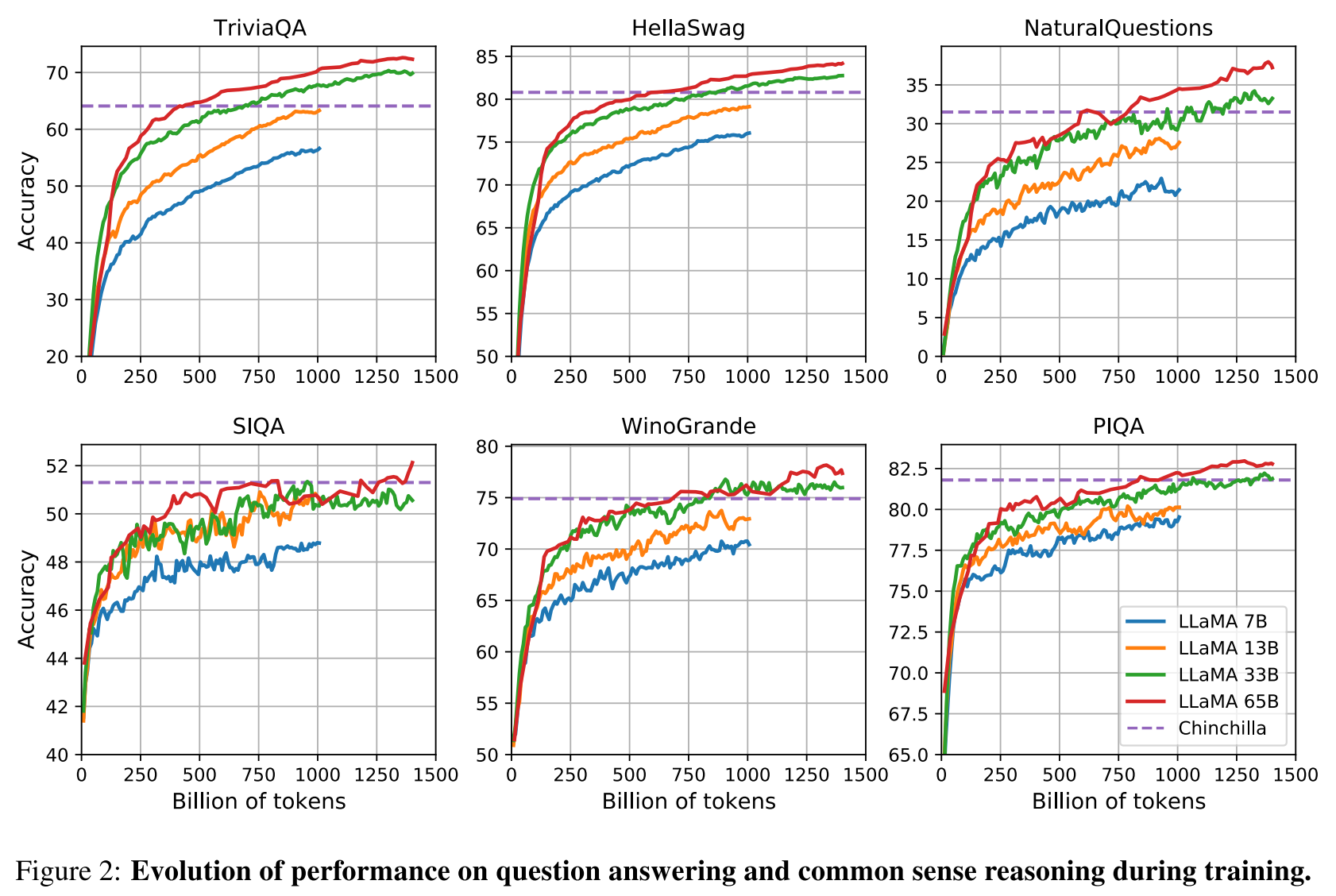
LLaMA这篇论文还报告了一个比较符合预期的结果,就是随着训练进程的推进,模型在上面这几个数据集上的表现是在提升的。这可以解释为什么这篇论文他们选择用比其他模型更多的数据来训练模型,而没有往更大模型的方向走。
 {: .align-center style=“width:80%”}
训练过程中模型水平的提高
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
训练过程中模型水平的提高
{: .align-caption style=“text-align:center;font-size:smaller”}
总结
生成式模型在NLP里面真的统一了原来五花八门的任务,原来做阅读理解都是预测span,现在直接给生成答案了。
回望从2018年GPT2至今,学术界和工业界真是没少搞数据集。之前的文章我也表达过这个观点:数据集是深度学习,或者时髦点说是人工智能这门学科发展的北极星。正是这些数据集的出现,人们可以评估、比较模型的结果,涌现更多的科学发现。在上一篇讲语言模型数据集的文章里我们发现中文在数据中所占比例不大,在今天的benchmark数据集里同样也难见到中文的影子。这方面不得不佩服百度,他们和中国计算机学会一起搞了个千言数据平台,感觉是国内中文数据集比较齐全的地方了,但总体质量和英语数据集还是有一些差距。下周他们的文心一言就要发布了,且看能否打响中文大语言模型的第一枪。