前情提要:
这是大模型补课的第三篇文章,主要关注模型及其训练方法。做算法的人往往最喜欢看模型相关的东西,这期包含的内容也确实很有趣,不需要技术背景也能看懂。
Encoder vs Decoder
在模型层面,我认为大模型时代最重要的一个变化就是从前几年的Encoder为主变成了Decoder Only占据绝对的主流。相对应的,自然语言生成问题取代了自然语言理解问题成为了主流,并且是在用生成这种范式统一了理解问题。
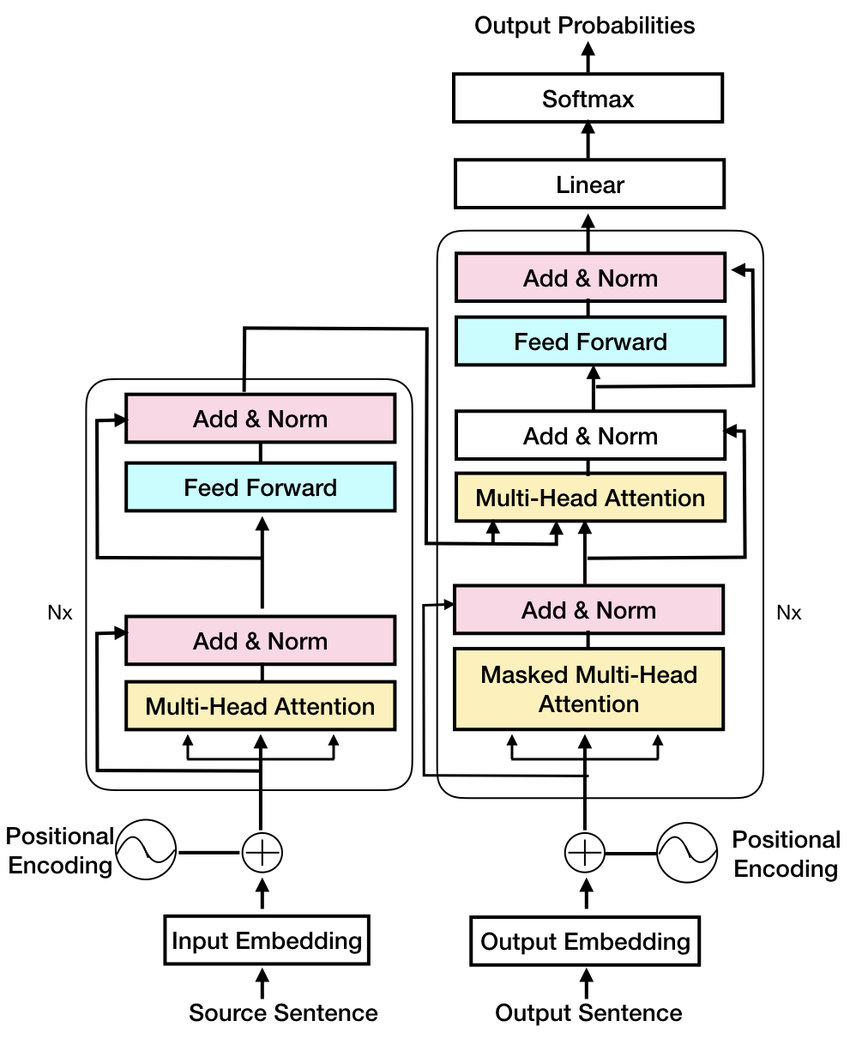
transformer编码器和transformer解码器的主要区别在于它们如何处理输入和输出序列。
 {: .align-center style=“width:80%”}
最开始的时候Transformer的Encoder和Decoder是成对出现的
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
最开始的时候Transformer的Encoder和Decoder是成对出现的
{: .align-caption style=“text-align:center;font-size:smaller”}
Transformer编码器处理输入序列(例如句子),并将其转换为一组隐藏表示,以捕获序列的含义。编码器由一堆相同的层组成,每个层对输入序列应用自注意力机制和前馈神经网络。
另一方面,Transformer解码器基于编码器产生的隐藏表示生成输出序列。它也由类似的层堆叠组成,但每个层还关注编码器产生的隐藏表示,以包含输入序列的信息。解码器还使用自注意力机制以自回归方式生成输出序列,这意味着它逐个标记地生成,条件是它已经生成的标记。
总之,虽然transformer架构中的编码器和解码器都使用自注意力机制和前馈神经网络,但编码器处理输入序列,解码器通过关注编码器产生的隐藏表示来生成输出序列。
当下火爆的大语言模型几乎都使用的是decoder only的结构。在知乎有一个问题为什么现在的LLM都是Decoder only的架构?,非常推荐大家阅读。GPT4发布之后,其处理context的能力从3.5的4k一下跃升到32k,不知道openai是不是又加入了encoder。
涌现、Scaling Law和科学炼丹
模型的规模增大无疑是最近AI进步的重要推动力。目前像GPT3.5这样的语言模型包含了1750亿个参数,相比于人脑中的神经连接其实还小了差不多一个数量级。模型的大小和其能力的关系实际是一个非常有指导意义的值得研究的问题。
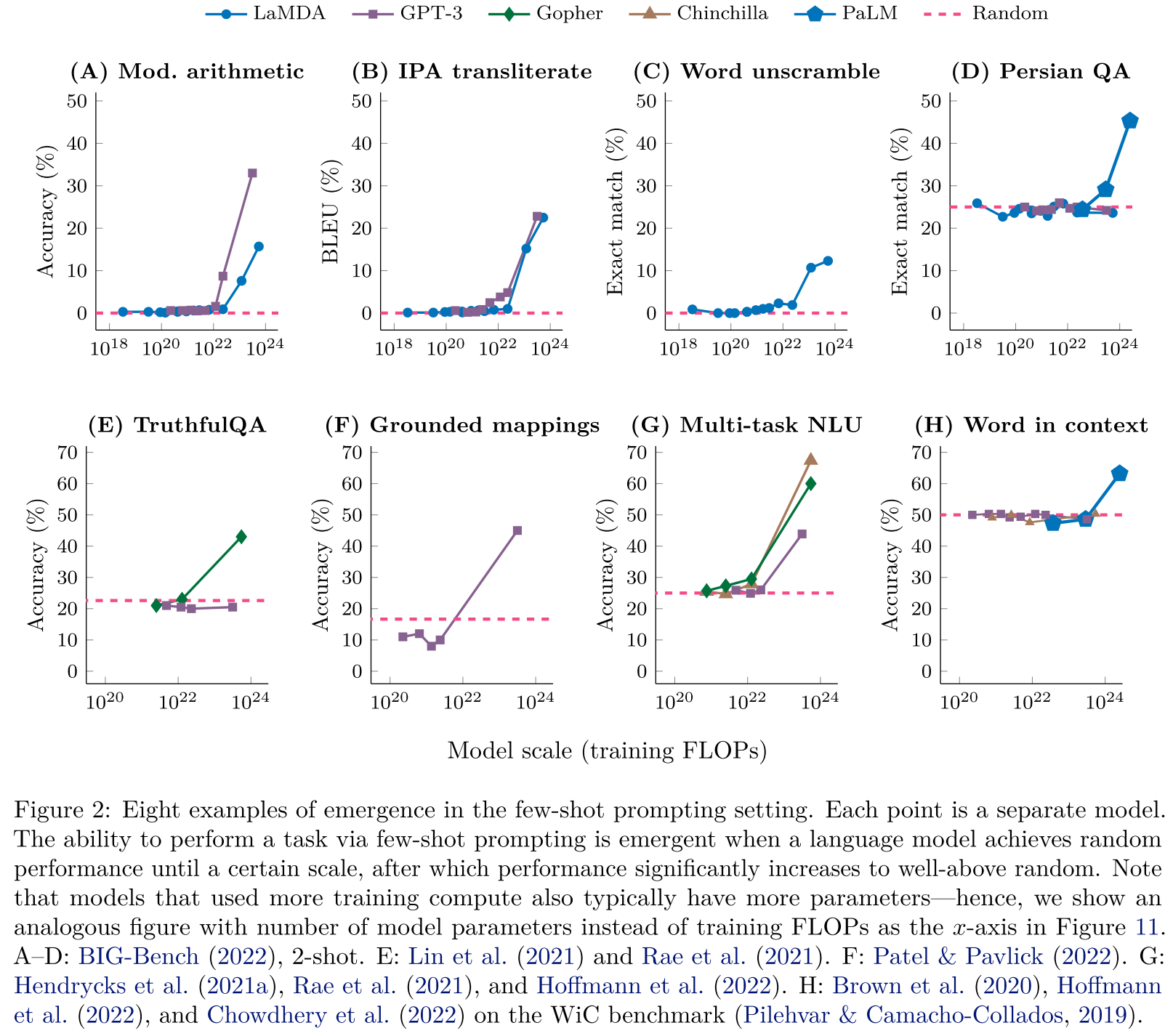
涌现(emergent abilities)是在2022年中的论文Emergent Abilities of Large Language Models 提出的概念,是指在大模型中出现的而在小模型里没有出现的能力,用咱们熟悉的话说就是"量变引起质变",而且这种现象是不可预测的。这种不可预测性给模型的开发带来了很大的麻烦,因为训练一个100B以上的模型成本是非常高昂的。这篇论文里列举了好几个任务里涌现的案例。
Emergence is when quantitative changes in a system result in qualitative changes in behavior. –Nobel prize-winning physicist Philip Anderson
 {: .align-center style=“width:80%”}
Few-shot任务里体现出来的涌现现象
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
Few-shot任务里体现出来的涌现现象
{: .align-caption style=“text-align:center;font-size:smaller”}
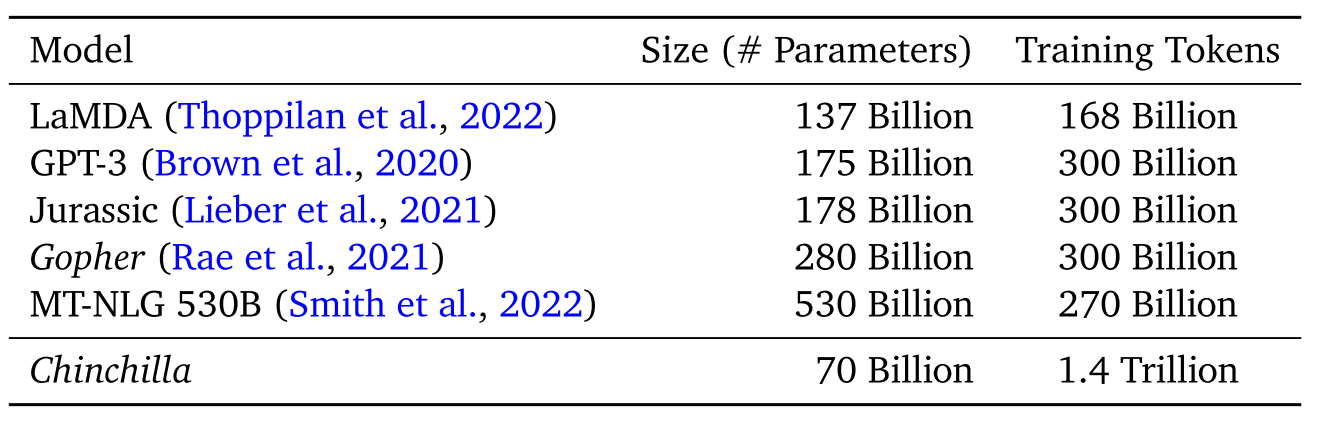
实际上,早在几年前人们就训练过巨大的模型,但那时候并没有出现现在这么强的模型。例如可能是世界上最喜欢大模型的公司Nvidia,在2022年训练过一个530B的超大模型MT-NLG,但可能知道这个模型的人都很少。Deepmind的论文Training Compute-Optimal Large Language Models讨论了这个问题,并给出了结论:之前的模型都训练不充分,把数据量提上去小模型也会有大能力。还给出了一套算力消耗一定的情况下合理分配模型规模和训练数据多少的方法论。
 {: .align-center style=“width:80%”}
典型的大模型参数量及训练数据量,Chinchilla参数少得多但性能更强
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
典型的大模型参数量及训练数据量,Chinchilla参数少得多但性能更强
{: .align-caption style=“text-align:center;font-size:smaller”}
现在的模型基本都会遵循这套scaling law。在LLaMA模型里,数据集的总token量也是1.4T,但是META他们每个token不一定只出现一次。其结果就是LLaMA更小参数的版本比Chinchilla的能力更强。
对scaling law掌握的最好的还是OpenAI。在GPT4的技术报告里,OpenAI说他们已经有了用小规模模型预测大规模模型的能力。这就是OpenAI恐怖的地方,大家还在苦苦等待涌现,他们已经能科学炼丹了。这个技术在涌现那篇论文里有一些端倪,那篇论文里有一个推测,我们挂测到的涌现可能是由于metrics用的是字符匹配,而这是一种离散的方法,只有当变化足够大的时候才能在指标上体现出来。但是在概率分布空间,性能的提升是可以提前观测到的。
A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4’s performance based on models trained with no more than 1/1,000th the compute of GPT-4.
指令微调和In Context Learning
指令微调(Instruction Finetuning)我认为是大模型领域近几年最重要的技术发展之一。在LLaMA论文里,他们开宗明义地讲
we show that briefly finetuning on instructions data rapidly leads to improvements on MMLU. Although the non-finetuned version of LLaMA-65B is already able to follow basic in- structions, we observe that a very small amount of finetuning improves the performance on MMLU, and further improves the ability of the model to follow instructions.
经过指令微调后的LLaMA在MMLU数据集上的表现提升了5个点。超过了同等大小,指令微调的开山鼻祖Flan系列模型。
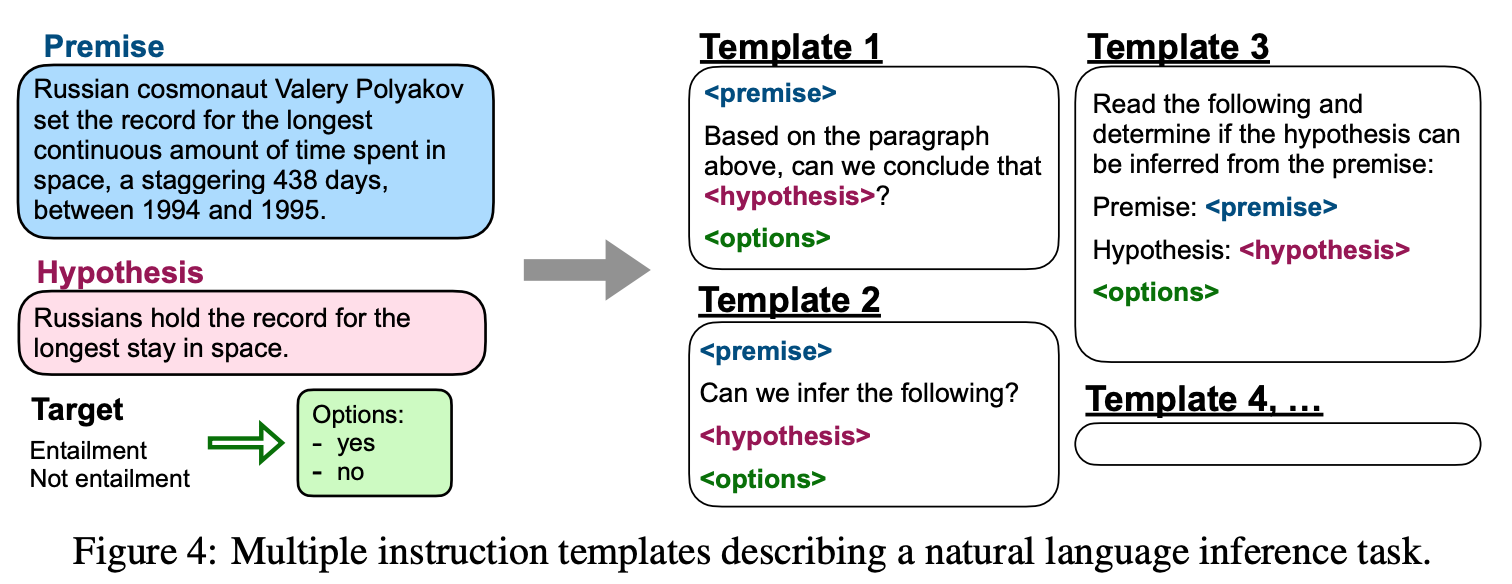
指令微调是在finetuned language models are zero-shot learners这篇论文提出的,这篇文章的想法比较简单,就是把各式各样的NLP任务转化为指令的格式(更接近使用时的输入范式)。
 {: .align-center style=“width:80%”}
把各种NLP任务转化为指令
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
把各种NLP任务转化为指令
{: .align-caption style=“text-align:center;font-size:smaller”}
这种做法其实不是完全原创的,之前的模型例如T5和GPT3也采用了类似的方法来让生成式模型获得zero-shot学习的能力。下面是一组对比,可以看出FLAN模型的PROMPT和GPT3确实很像。
T5 prompt:
cb hypothesis: At my age you will probably have learnt one lesson.
premise: It’s not certain how many lessons you’ll learn by your thirties.
GPT-3 prompt:
At my age you will probably have learnt one lesson.
question: It’s not certain how many lessons you’ll learn by your thirties. true, false, or neither? answer:
FLAN prompt:
Premise: At my age you will probably have learnt one lesson.
Hypothesis: It’s not certain how many lessons you’ll learn by your thirties.
Does the premise entail the hypothesis?
这个指令微调有一些有趣的结果,首先是这样获得的模型零样本推理能力比原始模型强,但在绝大部分任务上并不能超过在领域数据上训练过的小模型。所以,我认为那些认为NLP工程师会被大模型取代的说法是有一些耸人听闻的,在有业务数据的情况下,搞个小模型不仅性能好,而且成本低(虽然算上人力成本可能就不一定了,chatGPT的计费方式简直是倾销😭)。
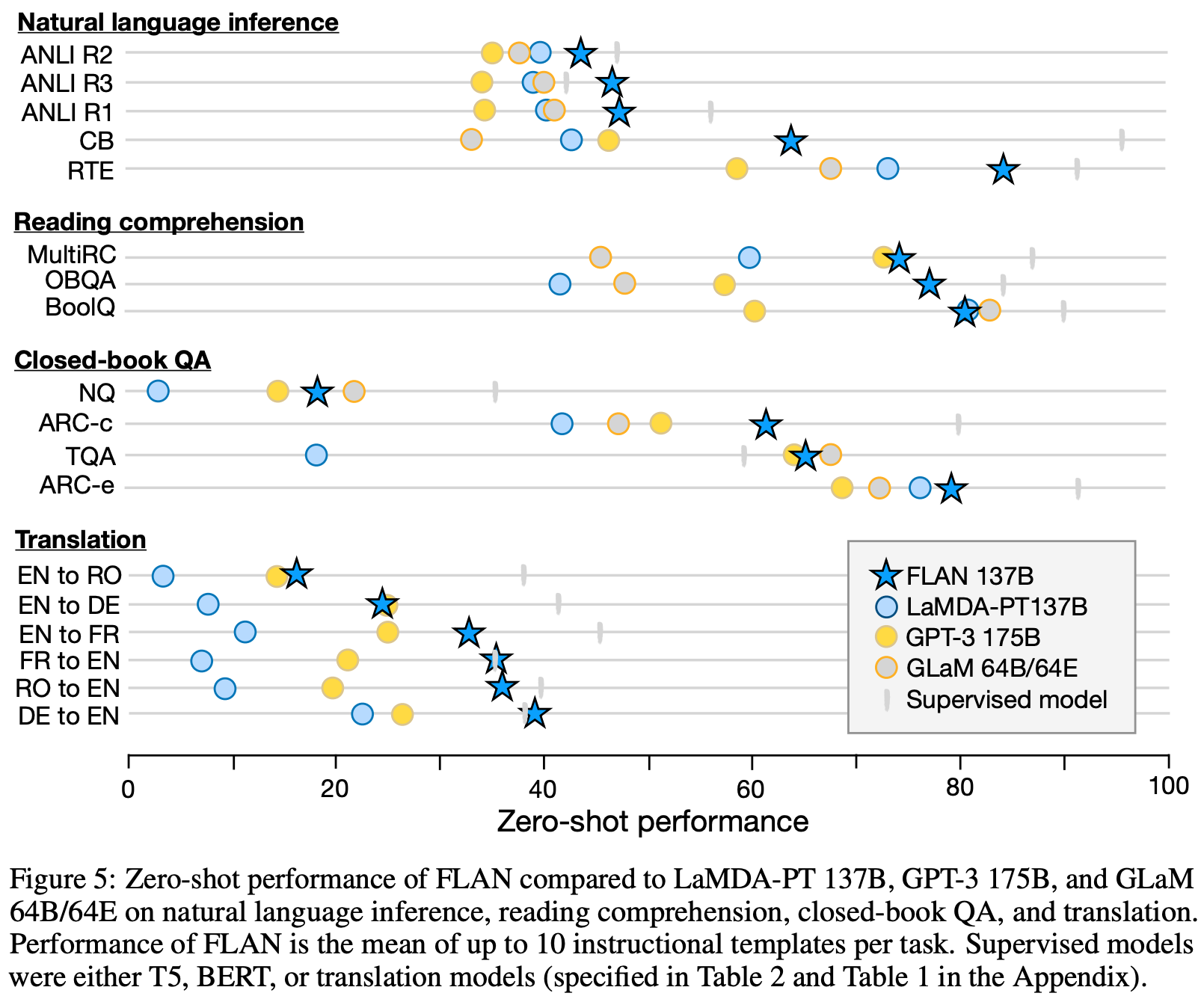 {: .align-center style=“width:80%”}
指令微调提升很大,但通常不如监督学习得到的小模型
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
指令微调提升很大,但通常不如监督学习得到的小模型
{: .align-caption style=“text-align:center;font-size:smaller”}
第二个是必须有一定规模的模型才能被指令微调提高(也是一种涌现现象),一些小模型上用指令微调反而会让效果变差。
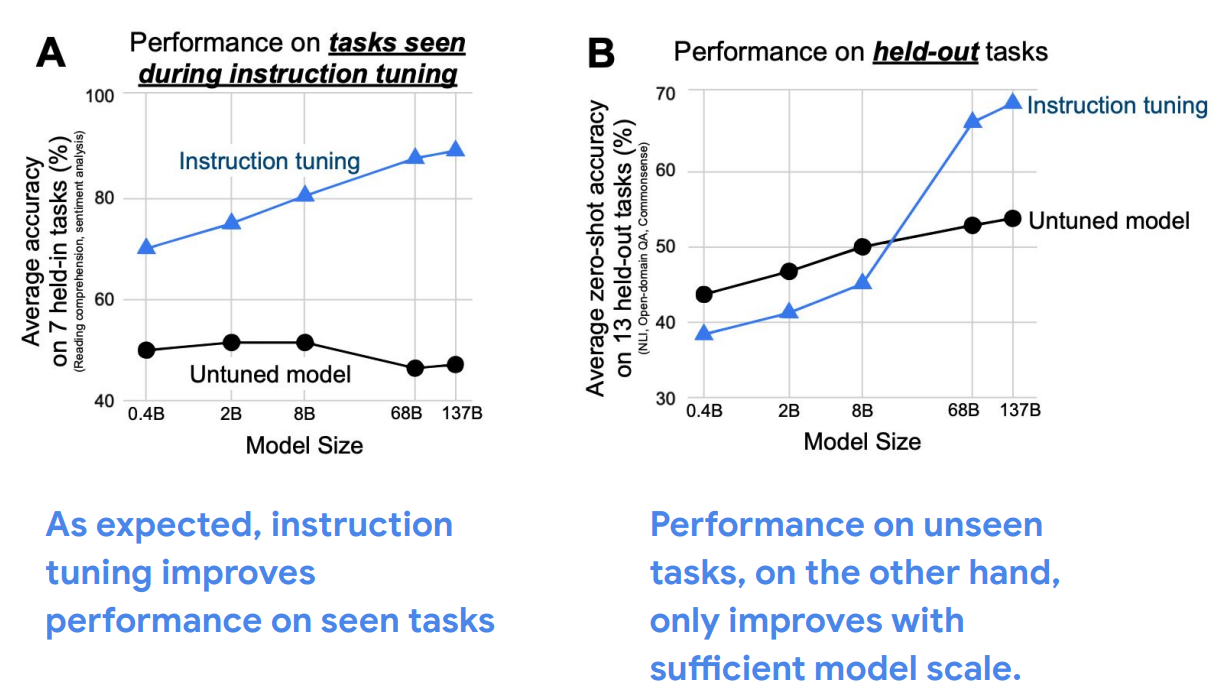 {: .align-center style=“width:80%”}
结果来自FLAN论文一作Jason Wei的博客
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
结果来自FLAN论文一作Jason Wei的博客
{: .align-caption style=“text-align:center;font-size:smaller”}
和指令微调很像的一个概念是所谓的In Context Learning,是指一个大型预训练语言模型 (LM) 观察一个测试实例和一些训练样例作为输入,并直接解码输出,而不进行任何参数更新。也就是说和指令微调的不同一个是不训练,相当于一种TTA,另一个是Prompt的内容不太一样,给到模型的是一些样例,而不是指令。
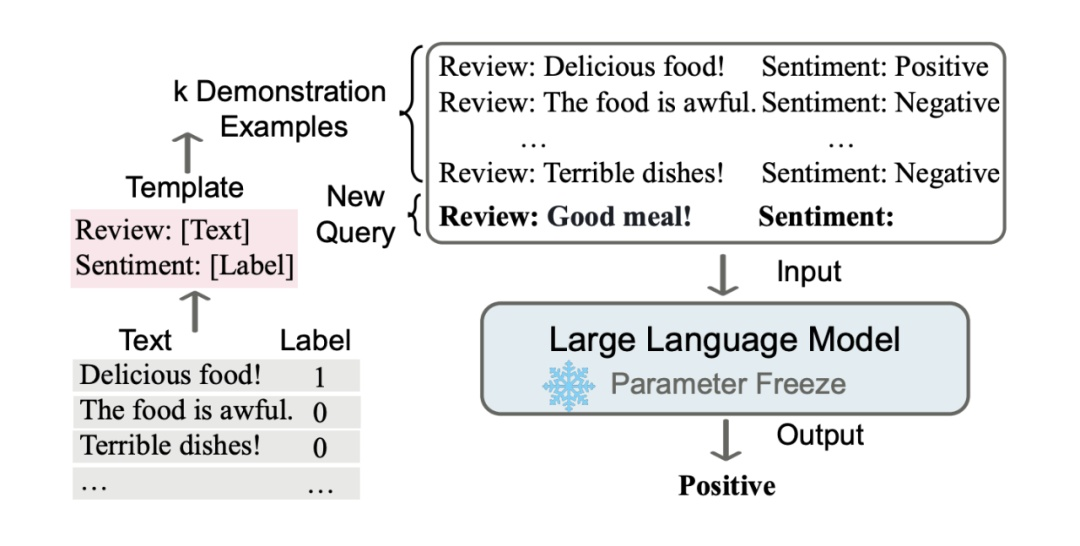 {: .align-center style=“width:80%”}
In context learning示意图
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
In context learning示意图
{: .align-caption style=“text-align:center;font-size:smaller”}
当然,现在指令prompt和context prompt常常是一起使用的。In context learning也有类似指令微调的scaling law,并且前段时间被Jason Wei的弟弟Jerry Wei用一个很巧妙的方法,翻转标签,又验证了一遍。
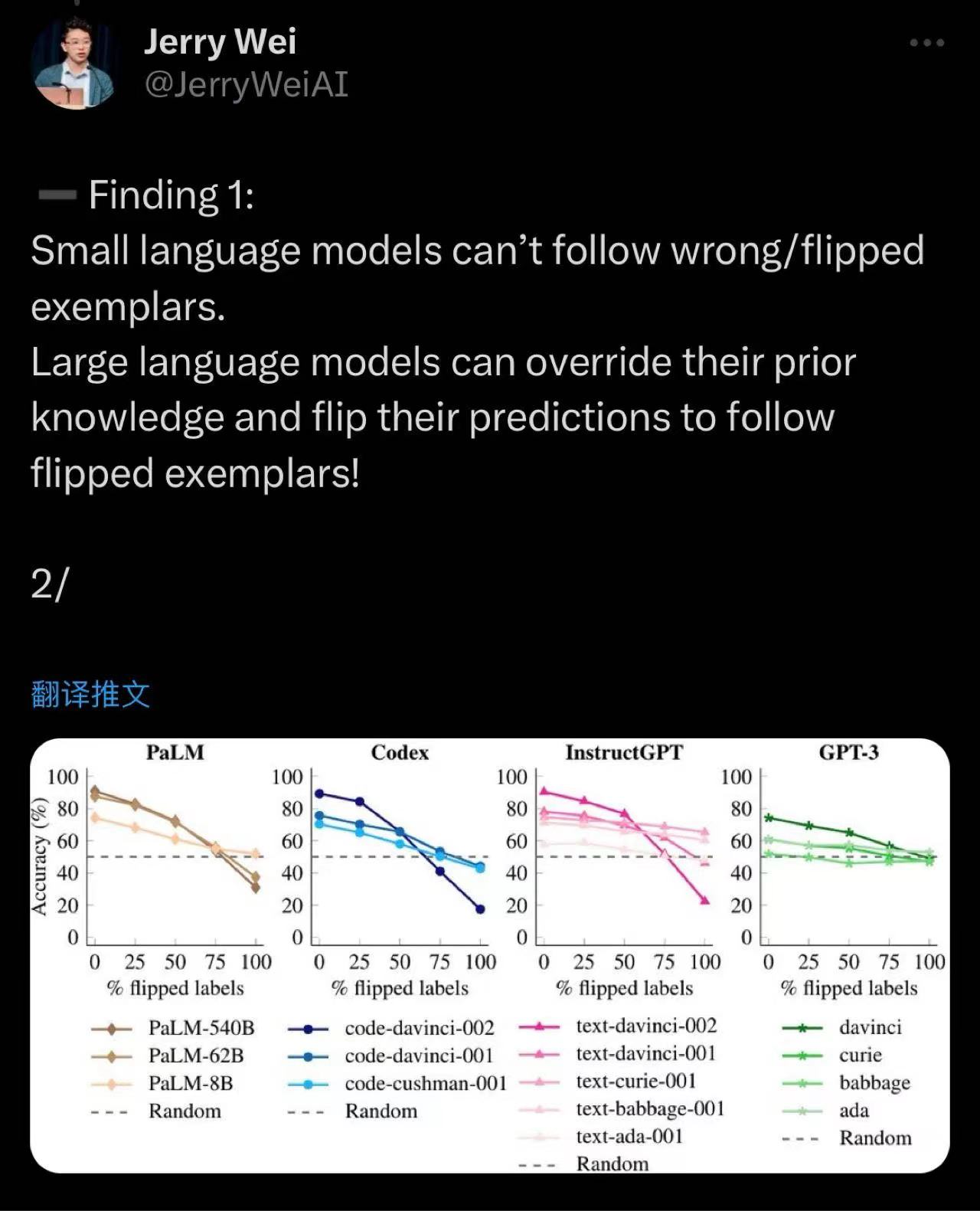 {: .align-center style=“width:80%”}
小模型没法跟随翻转过的context,而大模型可以
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
小模型没法跟随翻转过的context,而大模型可以
{: .align-caption style=“text-align:center;font-size:smaller”}
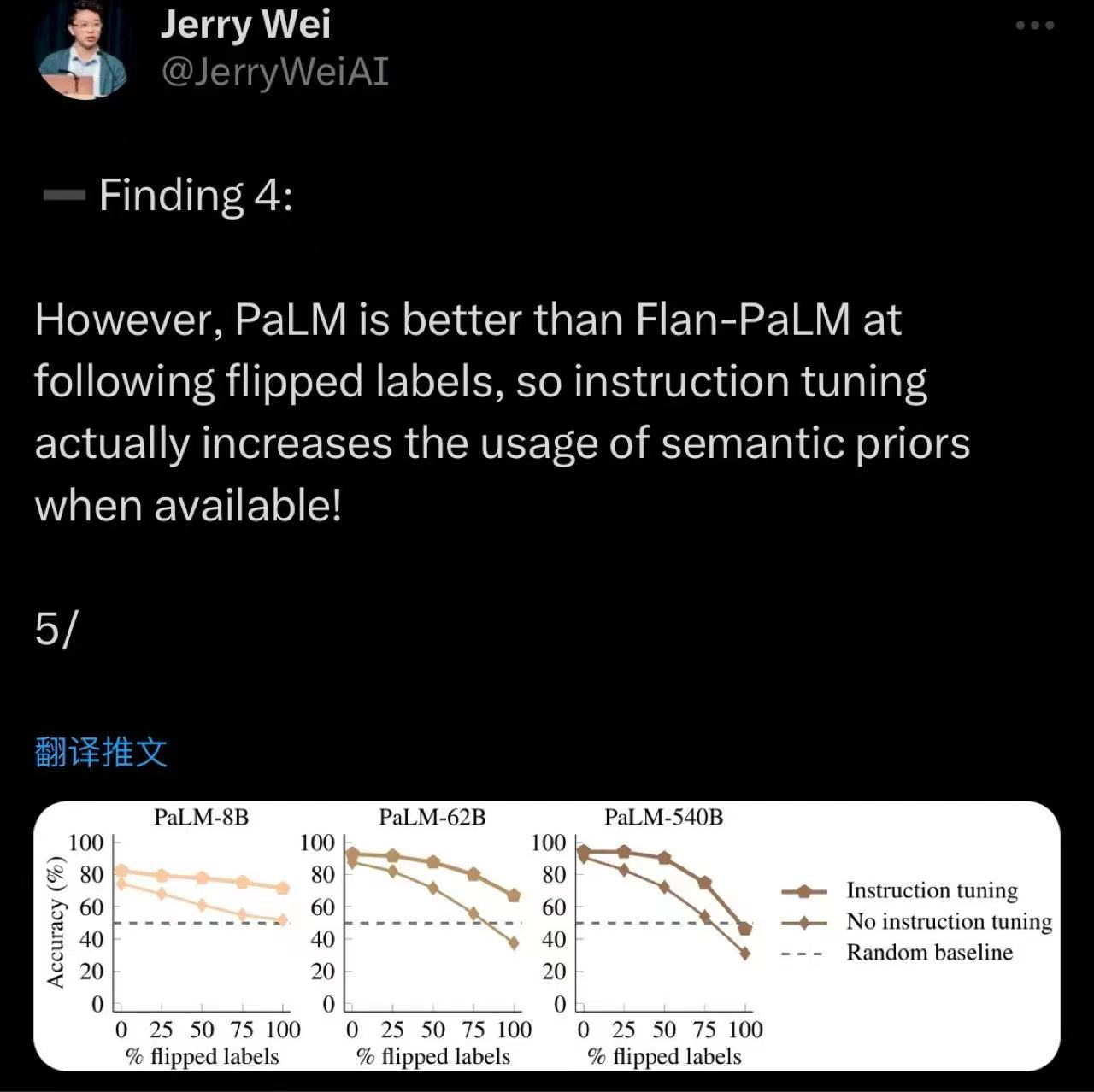 指令微调过的模型更难跟随翻转过的context。这也说明指令微调强化了模型对先验知识的使用。
{: .align-caption style=“text-align:center;font-size:smaller”}
指令微调过的模型更难跟随翻转过的context。这也说明指令微调强化了模型对先验知识的使用。
{: .align-caption style=“text-align:center;font-size:smaller”}
CoT
CoT是Chain-of-Thought Prompting,思维链的缩写,是论文Chain-of-Thought Prompting Elicits Reasoning in Large Language Models提出的一种Prompt技巧。
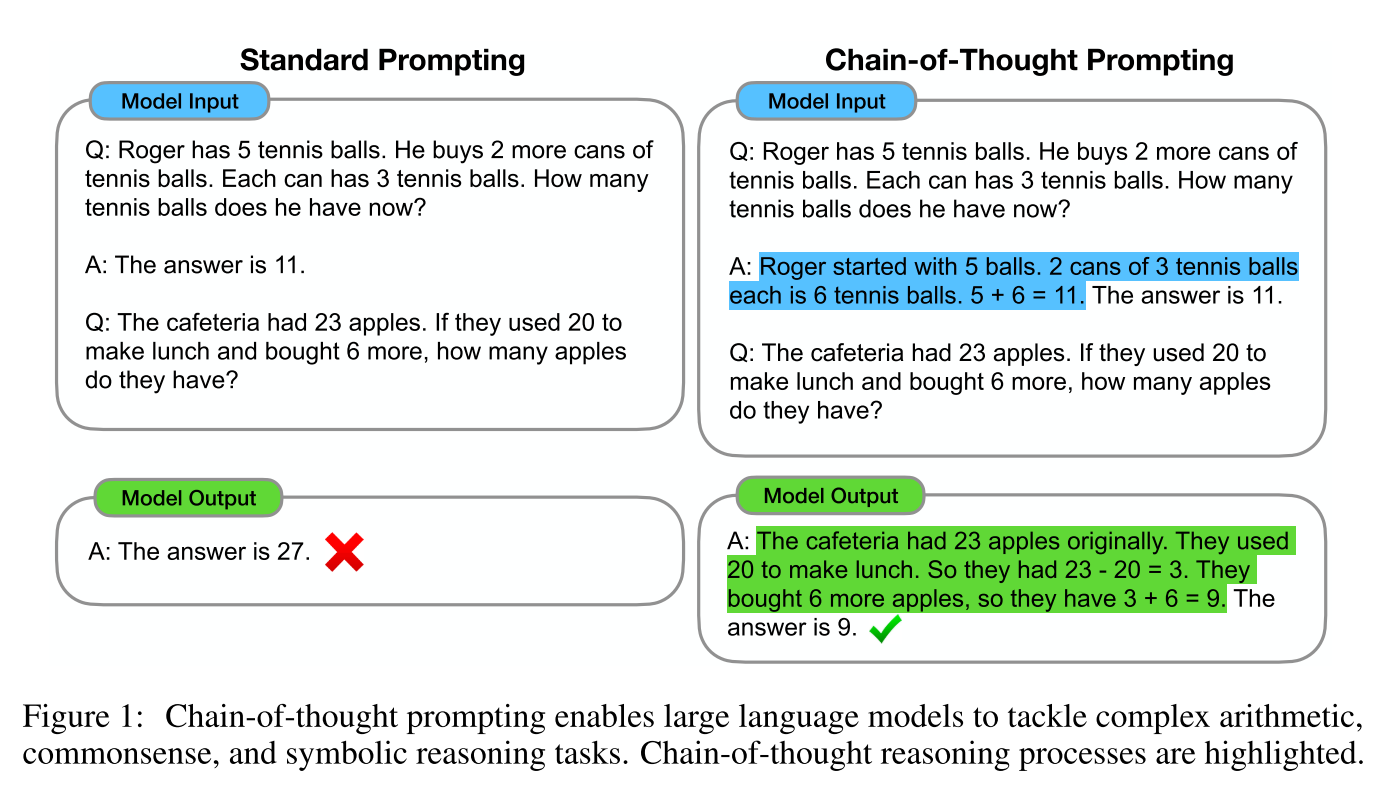 {: .align-center style=“width:80%”}
简单prompt和思维链prompt。右边的CoT prompt在context里引入了推理过程,使得模型得出了正确的结果
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
简单prompt和思维链prompt。右边的CoT prompt在context里引入了推理过程,使得模型得出了正确的结果
{: .align-caption style=“text-align:center;font-size:smaller”}
这个技巧也非常简单,就是在输入模型的prompt里加入推导过程,这样模型就能大大提高推理能力。这也确实比较像人类的思考模式,大部分人都需要一步一步来到达那个思考的终点。从下面的图可以看出,思维链的能力也具有涌现的性质,只有在模型够大的时候才有效,而且GPT模型的COT能力特别强。
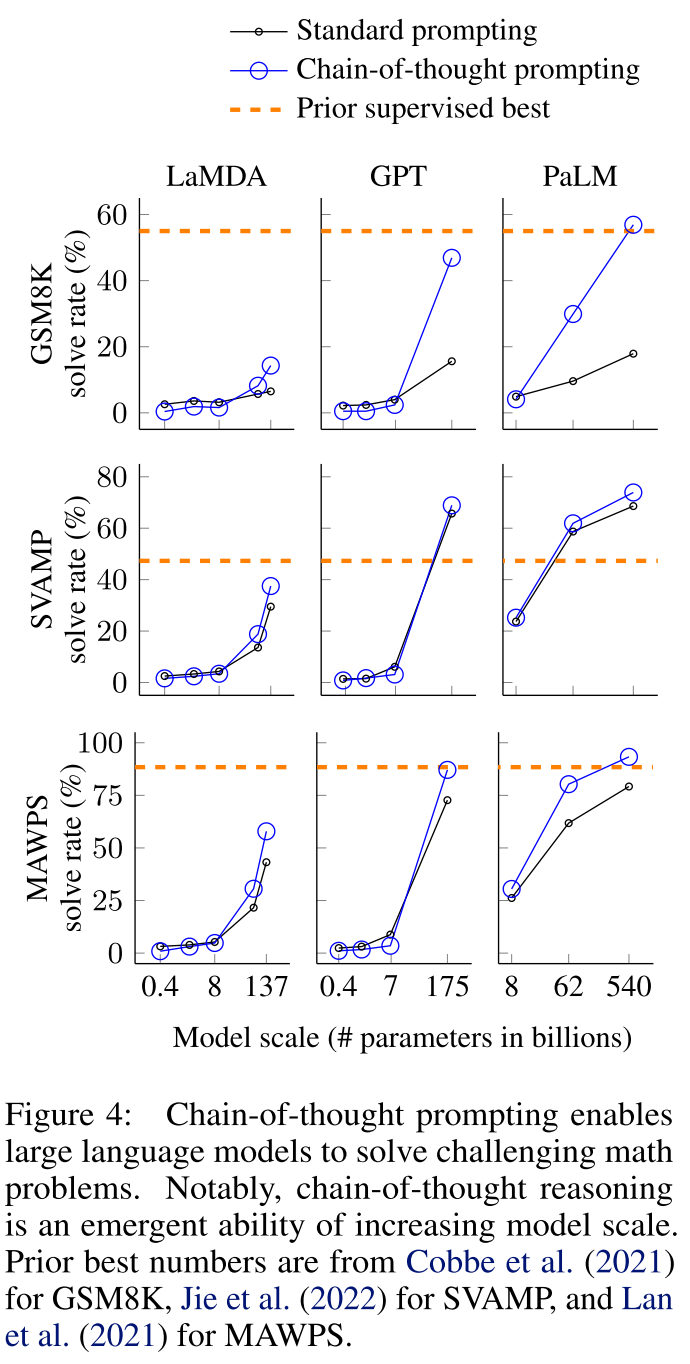 {: .align-center style=“width:80%”}
思维链的能力也具有涌现的性质,只有在模型够大的时候才有效,而且GPT模型的COT能力特别强
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
思维链的能力也具有涌现的性质,只有在模型够大的时候才有效,而且GPT模型的COT能力特别强
{: .align-caption style=“text-align:center;font-size:smaller”}
这篇论文的一作也是Jason Wei,这个小哥我感觉有点神奇。他的两篇重要论文其实里面都没有一个公式,充满一股巧劲。我还特地去领英看了下他的背景,本科毕业就进了谷歌,升得特别快,现在已经是OpenAI的Technical Staff了。
在这篇文章里介绍指令微调、in context learning和CoT不仅仅是因为他们对理解现在的模型很重要,还因为他们对于使用模型非常重要。在目前的情况下,能够开发模型的人很少,但使用模型的人会越来越多。具有这些知识对提高模型的使用效果有很大的帮助。In Context Learning, COT是一些高级Prompt设计的基础。
RLHF和Alignment
语言模型的对齐(Alignment)也是大模型时代流行起来的一个话题,指的是将模型训练成能够生成与特定价值观或目标一致的文本的过程。这个过程涉及微调模型参数和调整训练数据,以确保生成的文本与期望的结果一致。和上面的指令跟随(是提高alignment的手段)也有千丝万缕的联系。
例如,用于情感分析的语言模型可能被对齐为生成准确反映给定文本中表达的积极或消极情绪的文本。同样,用于语言翻译的语言模型可能被对齐为生成准确传达原始文本在目标语言中的含义和语调的文本。
对齐是语言模型训练中的一个重要考虑因素,它可以显著影响模型的准确性和效果。通过确保模型与特定的价值观或目标一致,研究人员和实践者可以确保模型生成的文本更加有用和相关,适用于他们的特定应用或用例。根据技术报告,像GPT-4这样的模型在开发过程中有很大的精力都投入在Alignment上,因为发布一个价值观不正确的模型对一个公司来说是非常危险的。
而RLHF (Reinforcement Learning from Human Feedback)正是解决对齐问题的有力工具。由于我对强化学习比较陌生,这里推荐大家阅读Huggingface的博客ChatGPT 背后的“功臣”——RLHF 技术详解,Huggingface也开源了用于语言模型强化学习的软件包。
小结
以上就是关于大语言模型及其训练方法的内容。大家可以发现,几年前语言模型的研究是真的在模型结构方面有很多工作,各种花式attention、loss、训练任务层出不穷。芝麻街里的角色名字也被快速消耗殆尽。
 {: .align-center style=“width:80%”}
大家熟悉的BERT,ELMO,ERNIE,GROVER,Big Bird都是以芝麻街的角色命名的
{: .align-caption style=“text-align:center;font-size:smaller”}
{: .align-center style=“width:80%”}
大家熟悉的BERT,ELMO,ERNIE,GROVER,Big Bird都是以芝麻街的角色命名的
{: .align-caption style=“text-align:center;font-size:smaller”}
但是技术发展到今天,很多的进展看上去都没那么"硬核",但这些东西又切实地把更好更强大的模型带到了我们眼前。
作为个体,我感觉应该积极地成为大模型的early adapter,平时多用用,也可以用更开放的态度多思考它还有哪些问题,可以通过哪些prompt解决。说不定能发现下一个CoT哦。