前情提要:
这是大模型补课的第四篇文章,主要关注模型背后的训练工具。
并行:大模型训练的必要手段
如果你使用过多张GPU训练模型,那应该对并行不陌生。最基本并行方式有以下两种
- DataParallel数据并行(DP)。这也是最常用并行方法,在pytorch里有DP和DDP两种原生方式,使用起来都很方便。这种并行方式最好理解,模型在每个worker上都有完整的一份,只是给他们喂的数据不同。在每个worker算完后,需要一个同步过程,来综合大家的梯度信息,再更新模型。数据并行主要解决训练速度的问题,可以在单位时间内学习更多的样本。
- ModelParallel模型并行(MP)。模型并行指的是把模型分拆到多个GPU上,主要解决模型太大而无法放到一个GPU上的问题。以目前爆火的大规模语言模型为例,一个175B的GPT模型,整个载入的话需要 $$175*10^9$$ 个参数,每个参数用4个字节,则需要700G的存储空间,目前没有听说过哪个GPU可以放得下,只能把一个模型放到好几张卡上。模型的拆法也有多种,可以把不同层放不同卡,这种称为垂直拆分;也可以在同一层也拆开,这种被称为水平拆分。
以下再介绍几个模型并行的细分方法。
- TensorParallel张量并行(TP)。每个张量被分成多个块,因此不是整个张量驻留在单个 GPU 上,而是每个张量片段驻留在其指定的 GPU 上。在处理期间,每个片段在不同的 GPU 上分别并行处理,结果在步骤结束时进行同步。这就是所谓的水平并行,因为拆分发生在水平层面上。
- PipelineParallel流水线并行(PP)。模型在多个 GPU 上垂直(层级)拆分,因此仅将模型的一个或几个层放置在单个 GPU 上。每个 GPU 并行处理管道的不同阶段,并处理一小批数据。流水线并行的主要问题是因为前后依赖而带来的GPU等待(下图中的Bubble区域),这个问题通常用更小批量的数据来缓解。
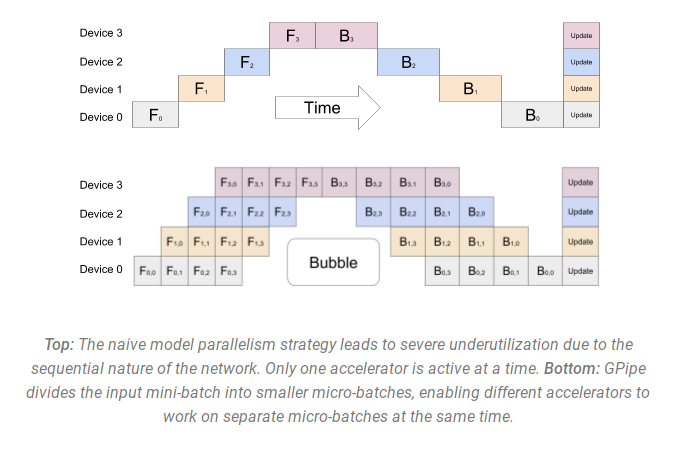
现代化的并行训练方法以上几种并行方法的有机组合,也就是传说中的三维并行(DP+TP+PP)。
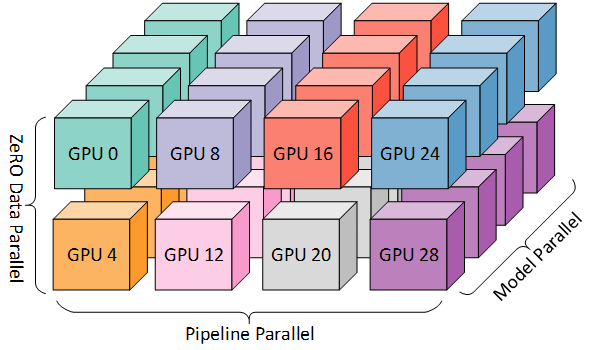
有关并行的介绍,推荐阅读Huggingface的这篇文档。
Megatron-LM
提到模型并行,不得不提的软件包是英伟达的Megatron-LM。但实际在这个开源大模型日新月异的今天,需要使用这个库的人也是很少的。这里根据论文介绍一下他的原理,还是挺有趣的。
目前的语言模型领域,Transformers结构已经是绝对的主流,在这种结构里,主要有两种building block,一个是多层感知机MLP,另一个是自注意机制。
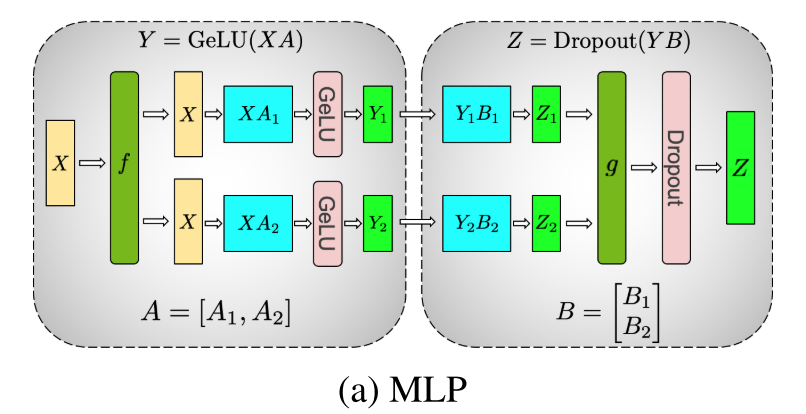
全连接层可以理解为矩阵乘法 $$Y=XA$$ ,其中 $$A$$ 是参数。第一种并行法是把这个参数按行来分割,而把输入按列分割,假设分成两个小矩阵
$$X=[X_1, X_2],A=[\begin{matrix}A_1\A_2\end{matrix}]$$
这样 $$Y=X_1A_1+X_2A_2$$ ,如果全连接后面跟一个非线性激活函数,例如GeLU,那么会遇到下面的问题
$$GeLU(XA)\ne GeLU(X_1A_1+X_2A_2)$$
所以只能把A按照列分为 $$[A_1, A_2]$$ ,这样可以得到
$$Gelu([Y_1,Y_2])=[GeLU(XA_1), GeLU(XA_2)]$$
整个过程可以用下图表示
自注意力机制的并行方法是MLP的扩展,具体的说就是把多个注意力头分到不同的GPU去执行。
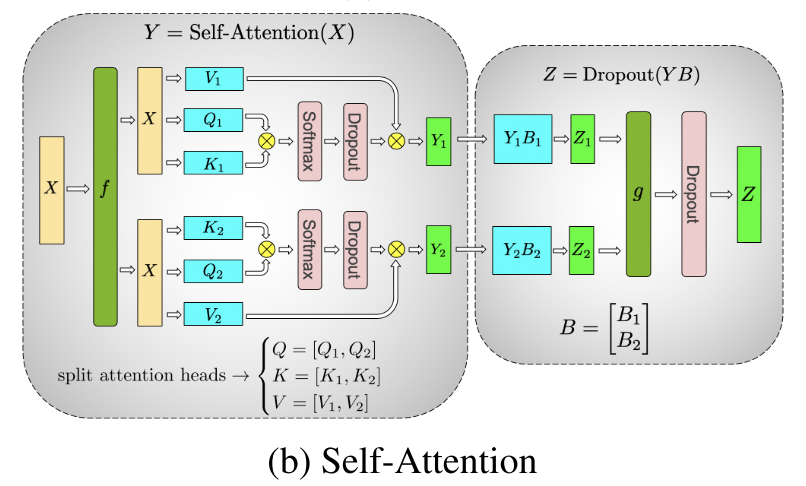
上面只是一些模型并行(准确的说是张量并行)的基本思路。并行的时候除了考虑减少单个显卡显存的使用,还要权衡额外产生的通信负担,是个很有意思的领域。我也了解不多,感兴趣的读者可以自己再读一些资料。
在Megatron论文里,他们合并使用了数据并行和张量并行,从而实现快速训练大模型的目标。
We efficiently trained transformer based models up to 8.3 bil- lion parameter on 512 NVIDIA V100 GPUs with 8-way model parallelism and achieved up to 15.1 PetaFLOPs sus- tained over the entire application.
ZeRO和DeepSpeed
ZeRO(Zero Redundancy Optimizer)是微软在2020年提出的一套并行优化方法。和Megatron的张量并行不同,这个算法采用的是流水线并行的方式。一言以蔽之,就是参数能不存就不存。
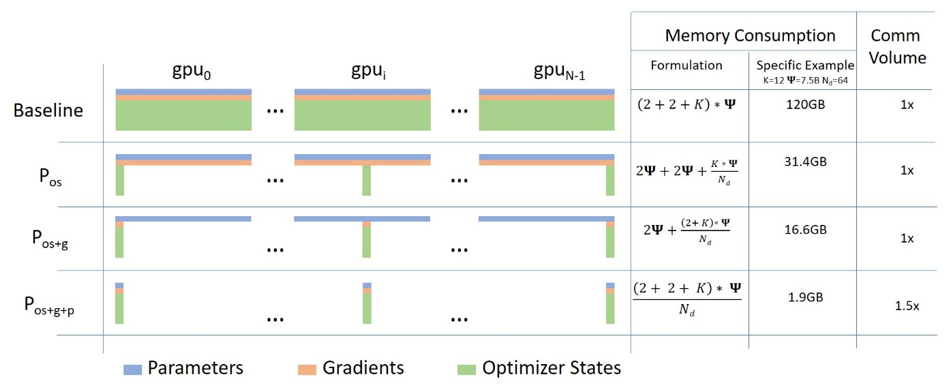
它分为以下三个阶段。
优化器状态分片Pos
这个阶段比较好理解。上图中的第一行为不使用ZeRO时数据并行训练的样子,每个GPU上都有完整的参数(p),梯度(g)和优化器状态(os)副本。右边的表格计算出了所需要的显存消耗,其中Ψ是模型参数量,2+2是指p和g都是fp16,占2个字节,k=12是指Adam优化器需要额外保存的滑动平均、二阶矩滑动平均等额外参数(优化器状态是大头啊)。这么搞下来,一个7.5B模型在单个GPU上的显存消耗需要120GB。
启用优化器状态分片后,优化器的状态不再是每个GPU都存完整的,而是每个GPU只存一部分,当需要使用的时候再通过广播发送到其他的GPU。如果有64个GPU来平分优化器的状态,那么一个GPU上的显存消耗就变成了31.4G,减小到了约baseline的四分之一。
优化器加梯度分片Pos+g
理解了上一阶段,这一阶段就很容易理解了。这一阶段是在上一阶段的基础上把梯度也分到不同的GPU上,只有要用的时候才同步。这么搞下来,又能再干掉一半的显存消耗。
全分片
这一阶段是把模型参数也给分片了。这么做之后,前向传播的过程就受到了影响。因为每个GPU上只保存了部分参数,在前向传播时需要从别的GPU把参数先拷贝过来。于是乎通信成本会比前面两个阶段增加。
到第三阶段的话原本120G的显存消耗变成1.9G,降了60倍。根据刚才的计算,一个fp32的175b模型需要700G,加上梯度和优化器状态的话fp16模式需要再乘4,就是2800G。如果要在目前最牛逼的80G显存A100上跑的话,需要至少有30个GPU。
目前,DeepSpeed已经被集成进了众多主流的训练框架,例如在大家熟悉的Transformers库里,只需要一个配置就可以非常容易地使用DeepSpeed。
PEFT
上面两个包很牛逼,但大家应该很少会直接使用,但PEFT这个包则是目前玩大语言模型必会的一个包。
PEFT是Parameter-Efficient Fine-Tuning的缩写,用大白话说就是低成本精调语言模型,主要解决的是adaption问题。所谓adaption,就是指把一个通用模型,例如LLaMA在你独特的场景语料里精调,让模型在你关心的任务上提升性能。
这个包支持的精调方法有
- LoRA,这个算法已经在文生图领域火出一片天,我感觉毫无疑问也会在大语言模型领域大放异彩(相比后面几种方法,LoRA真的在大模型领域重要非常多)。
- Prompt Tuning,这个训练方法是可以理解为是用[MASK] token来做NLU任务。例如输入“Amazing movie! This movie is [MASK]",然后看[MASK] token 模型预测的词是啥。
- Prefix Tuning,这可以理解为连续空间的prompt tuning。还是刚才那个例子,现在的输入变成了
cat([embedding(Amazing movie!), [h0, h1, h2], embedding([MASK])]。也就是说不用自然语言来输入提示词了,而是直接让模型在语义空间自行寻找提示词。 - P-tuning。感觉和上面的prefix tuning差不多。
目前很多新的大模型(基本全了)也都可以用PEFT微调了
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
|---|---|---|---|---|
| GPT-2 | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ |
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ |
| LLaMA | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ✅ |
而且用LoRA来微调真的能节约很多的显存。
| Model | Full Finetuning | PEFT-LoRA PyTorch | PEFT-LoRA DeepSpeed with CPU Offloading |
|---|---|---|---|
| bigscience/T0_3B (3B params) | 47.14GB GPU / 2.96GB CPU | 14.4GB GPU / 2.96GB CPU | 9.8GB GPU / 17.8GB CPU |
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
如果大家有看过alpaca的代码的话就会发现,其实核心代码都是调用Huggingface的Transformers,train.py那个文件直接调用了transformers的trainer进行训练。
而alpaca-lora这个repo实际调用端就是peft的转换函数来训练。
trl
之前的文章介绍过大模型训练的几个重要算法,其中一个是强化学习算法RLHF,或者更确切的说背后的PPO算法。这个方法可以让模型输出更加符合人类预期的结果,一个典型的应用是让模型更安全,少说有毒的话。但似乎目前玩家圈子里搞这一步的人还比较少,基本做到instruction finetune就结束了(毕竟不是公司,没有太多公众形象负担)。
目前有几个库可以支持算法,今天介绍一个库也是来自Huggingface的trl。PPO的主要流程如下图所示,分为三个阶段
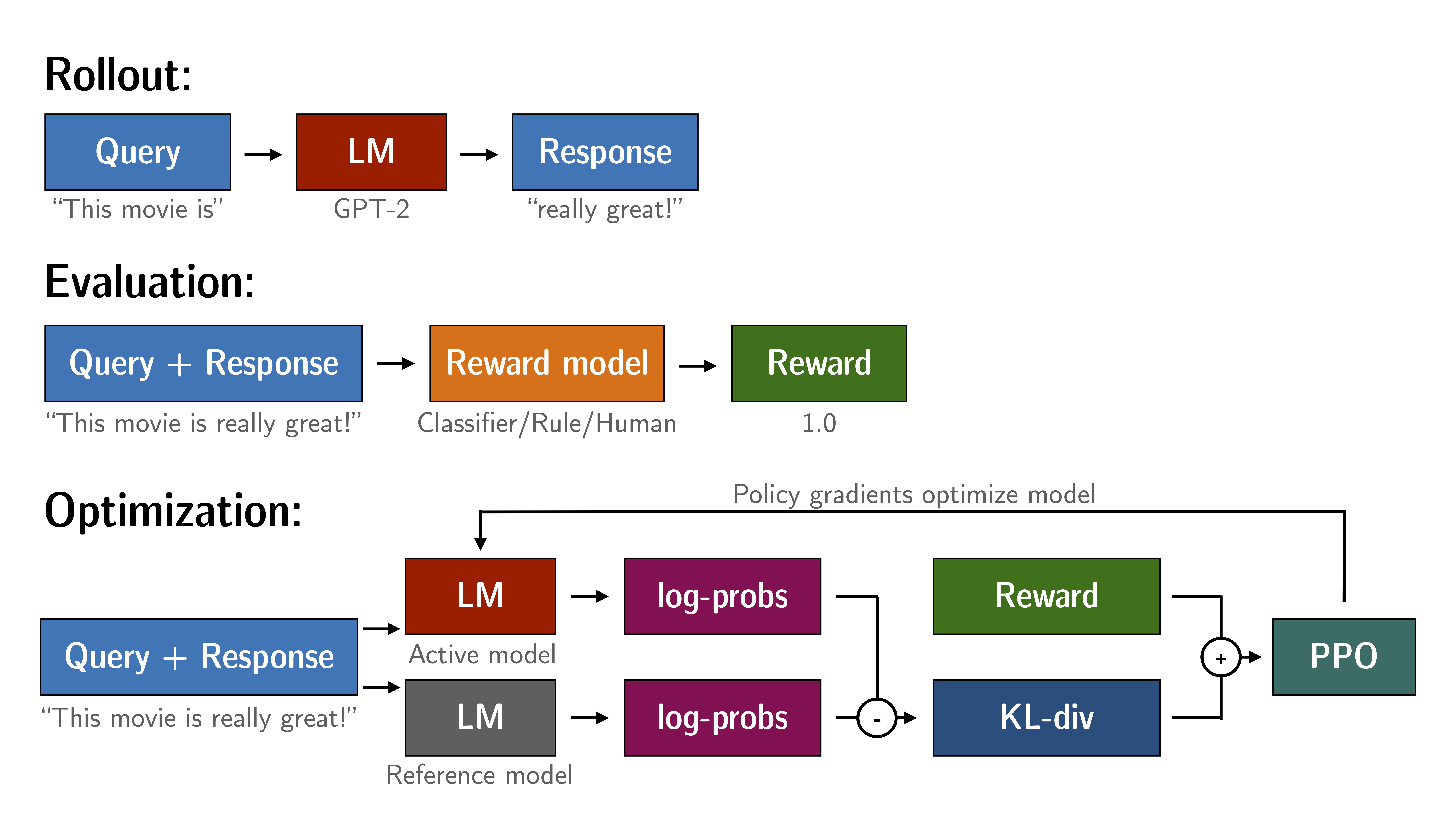
- Rollout。就是用模型根据query完成生成,获得response。
- Evaluation。用奖励模型(也可以是人工标注)算出这个response的得分。
- Optimization。实际上这个过程比较复杂,单看图也不是太清晰,我特地花了点时间看了下代码。稍微具体地说,PPO的时候需要有保留两个模型副本,一个是不会被更新的ref model,另一个是持续更新的active model。在一个大的PPO Step里,response和reward是由evaluation步骤确定的,不会变化。语言模型同时产生action和当前状态的value estimation,并且也是一并优化的。即让模型能预估reward,且能产生最大化reward的输出。期间还发现了他们注释(注释,注释,重要的问题说三遍)的一些小问题,提了一个PR,现在已经merge到主分支,成为了contributor😂
如果你对算法的原理不感兴趣也没关系,这个库也很易用,参考readme几行代码就可以开始PPO训练。
小结
以上就是关于大语言模型训练工具的内容。本来计划把训练和推理一起写的,但发现工作量实在太大,还是先写到这里。前几天一个老朋友跟我说大模型这块进展太快了,要学的东西好多。我也深有同感,如果时间紧张的话我建议大家就只看Huggingface的文档和博客,以他们目前的布局,未来一段时间都会是绝对的主流。
补课系列已经来到第四篇,最多还有一篇关于推理工具。后面在保持学习的同时,我会更多投入到实践中,开始炼丹了。欢迎大家持续关注,多交流。