在之前那篇颇受欢迎的卖惨小品【今天被OpenAI爆了】里,我讲述了被GPT embedding震撼的故事。但故事的最后,我们并没有采用openai的embedding接口,因为那样确实成本和产品稳定性都不好控制。
我们在一番寻找之后,我们看到了一个叫Massive Text Embedding Benchmark (MTEB)的大型语义表征benchmark(在Huggingface上有最新的的榜单)。并且最终选择了榜单上排名第二的instructor-lg模型。
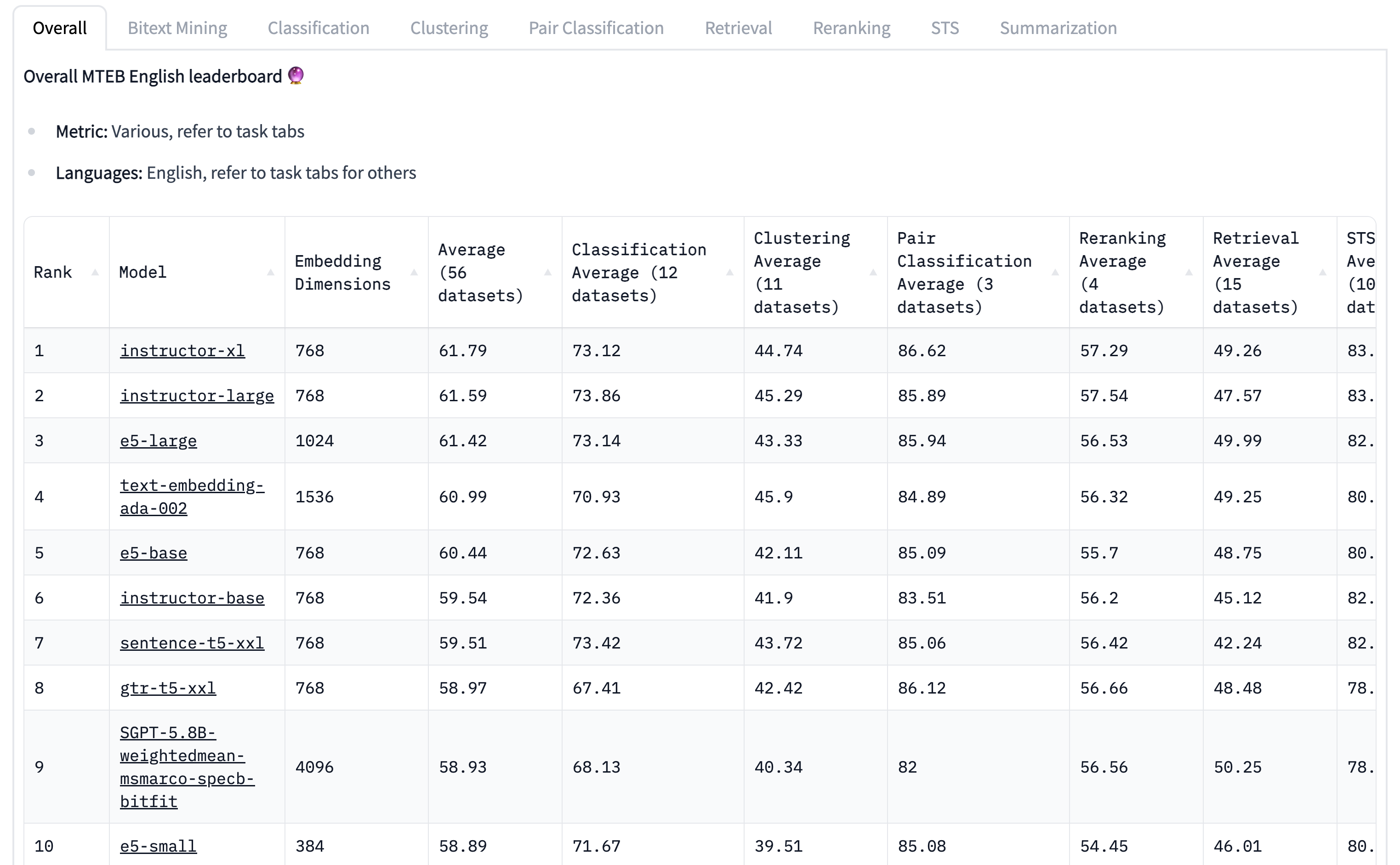
Instructor-large模型的水平在这个榜单上超过了openai的ada-002,可见开源社区还是很能打的。这个模型基于的是谷歌的T5模型,然后用instruction finetuning的方法训练了一个可以适用多个场景的embedding模型。维度768,模型0.3b,推理速度很快,线上使用负担也比1536的ada-002低很多。这个跟之前我使用的21年SOTA Simcse模型(排在排行榜第30位)比,规模是三倍,在这个benchmark上的得分是61.59 vs 48.87,提升确实很明显。不过我猜Simcse large的得分应该也能超过50。总之instructor是个好模型,推荐大家在需要语义embedding的场景使用。
但今天的主角并不是他,而是排在第14名的模型all-mpnet-base-v2。这个模型是sentence-transformers出品的一个模型,用的backbone是mpnet-base。它的规模和simcse相当,但得分是57.78,提升了很多。如果说前面的Instructor模型,甚至是GPT模型的提升很大程度来源于模型规模扩大,那这个同等规模模型的提升来自于哪里呢?mpnet这个稍显小众的网络可能比bert、roberta是强一些,但这不是主要的。因为有一个名字很类似的模型all-MiniLM-L12-v2,以及它的缩小版all-MiniLM-L6-v2,的得分分别是56.x。这两个模型的维度更小,是384维,而L6模型的层数甚至也只有bert-base的一半。主要的提升点来自于前缀all。model card里是这么说的
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences. We sampled each dataset given a weighted probability which configuration is detailed in the data_config.json file.
十亿句子对训练,没错,是十亿。拿一个小小的6层模型,在大量数据上训练,就可以获得一个比两年前的SOTA好很多的模型。这种暴力美学真的令我叹为观止。看到他们数据集的时候突然感觉自己的格局或者想象力真的太小了。什么叫对深度学习有信仰,这种玩法大概就是吧。其实OpenAI也是很类似的,因为相信大模型,大数据,所以能搞成。而且就sentence-transformers用的数据来说,都是公开可获取的,能跑得动这个训练的人应该有很多,但真这么跑的却很少。
不止是NLP领域,CV界不也是这样吗,前段时间Meta的SAM也是用史无前例的大数据集训练的。对比一下,之前的预训练模型用的常用数据集COCO才328K张图片,是SAM数据集的3%。

SAM is trained on a massive dataset of 11 million images and 1.1 billion masks, which is the largest segmentation dataset to date. This dataset covers a wide range of objects and categories, such as animals, plants, vehicles, furniture, food, and more. SAM can segment objects that it has never seen before, thanks to its generalization ability and data diversity.
大力真的有奇迹,今天就写这么多,希望对你有启发。