作为一名Prompt Engineer,每天都在跟GPT打交道,时常被他惊艳,也看过很多模型失效的案例。在不精调的情况下,prompt基本上是影响效果的唯一因素了,虽然网上有很多Prompt编写指南,但我认为OpenAI出品的这份,你一定要看一下。
这篇文章就给大家划一下重点。
ChatGPT基操
主要包含在How to work with large language models这个文档里,同时适合网页和API用户。首先,介绍了向ChatGPT提问的三种主要范式,一种是直接给指令,例如
Extract the name of the author from the quotation below.
“Some humans theorize that intelligent species go extinct before they can expand into outer space. If they're correct, then the hush of the night sky is the silence of the graveyard.”
― Ted Chiang, Exhalation
模型将会输出
Ted Chiang
另一种是将指令转化为一个补全(completion)问题,例如上面那个指令改为
“Some humans theorize that intelligent species go extinct before they can expand into outer space. If they're correct, then the hush of the night sky is the silence of the graveyard.”
― Ted Chiang, Exhalation
The author of this quote is
模型也将会输出
Ted Chiang
当然上面都是理想情况,尤其是用补全形式的时候,模型可能还会继续引申出一些其他内容,这是就需要一些后处理。
第三种称为demonstration,直白地说就是用一些例子告诉模型要干嘛,学究点说就是in-context few shot learning。还是上面的例子,输入改为
Quote:
“When the reasoning mind is forced to confront the impossible again and again, it has no choice but to adapt.”
― N.K. Jemisin, The Fifth Season
Author: N.K. Jemisin
Quote:
“Some humans theorize that intelligent species go extinct before they can expand into outer space. If they're correct, then the hush of the night sky is the silence of the graveyard.”
― Ted Chiang, Exhalation
Author:
模型也将输出
Ted Chiang
这三种范式都比较直接,尤其是前两种。而第三种就是Prompt Engineer主要的技术手段,也是LangChain、AutoGPT这些包里大量使用的技巧,后面会有单独的文章向大家介绍。
配合这三种范式,有一些通用的提问建议
- 更具体地描述你的需求,例如你想让GPT在不知道的时候不要瞎编,你可以在指令后面加上一句
'Say "I don't know" if you do not know the answer.’ - 提供更好的例子。例如让GPT来做句子的情感识别,你提供的句子和当前句子越接近,GPT给出的答案质量往往越高,这块有挺多进阶玩法。
- 让模型认为它是专家。例如你让他写小说,可以在一开始加一句
你是一名富有文采的文学大师。朋友们,没想到模型学会了人类的臭脾气。大家平时也要多给身边人正向激励哦😊 - 必要的时候使用思维链。如果你让GPT做推理或者数学题,不妨在指令前面加一句Let’s think step by step试试。
GPT API使用指南
对于使用API的朋友,可玩性比网页版其实高一些,而且API的使用方式和网页版也有一些差别。
一个典型的调用如下所示
MODEL = "gpt-3.5-turbo"
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Knock knock."},
{"role": "assistant", "content": "Who's there?"},
{"role": "user", "content": "Orange."},
],
temperature=0,
)
其中使用的是ChatCompletion这个方法(强烈推荐大家使用这个而不是单轮的Completion),model参数指定了模型,最主要的花头都在messages参数里。这个参数输入一个list of dict,每个字典表示一轮输入或输出,字典包含两个必须的元素role和content,还有一个可选的元素name。
system prompt(上面的第一条)很关键,在网页版是没有这个输入的。system prompt可以给对话设定一些基础的上下文信息,例如给模型定一个人设。GPT-4对system prompt会比gpt-3.5更加重视,如果使用3.5,那么OpenAI建议你把人设信息放在开头的user轮里。
前面提到给模型输入的样例也可以通过虚假的对话来呈现,例如
# An example of a faked few-shot conversation to prime the model into translating business jargon to simpler speech
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful, pattern-following assistant."},
{"role": "user", "content": "Help me translate the following corporate jargon into plain English."},
{"role": "assistant", "content": "Sure, I'd be happy to!"},
{"role": "user", "content": "New synergies will help drive top-line growth."},
{"role": "assistant", "content": "Things working well together will increase revenue."},
{"role": "user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."},
],
temperature=0,
)
这种玩法是网页版用户没法做到的,网页版提供的例子做few-shot实际上全是写在了某一个user轮里。
进阶玩法
这部分内容主要包含在Techniques to improve reliability这篇文档里,介绍了一些如果模型失效后的处理方法。
这里首先要树立的理念就是,上下文是会影响模型能力的。
第一招是所谓的化繁为简,就是把复杂的任务拆分成几个简单的任务。
例如下面这个让gpt用原始语言进行摘要的例子,如果你直接粗暴地说
Summarize the text using the original language of the text. The summary should be one sentence long.
Text:
"""
La estadística (la forma femenina del término alemán Statistik, derivado a su vez del italiano statista, "hombre de Estado") es una ciencia que estudia la variabilidad, colección, organización, análisis, interpretación, y presentación de los datos, ...文本太长,省略
"""
Summary:
它会返回你一堆英语
The text explains that statistics is a science that studies the variability, collection, organization, analysis, interpretation, and presentation of data, as well as the random process that generates them following the laws of probability.
但如果你在前面让他先判断文本的语言,再摘要,他就能行,像下面这样
First, identify the language of the text. Second, summarize the text using the original language of the text. The summary should be one sentence long.
Text:
"""
La estadística (la forma femenina del término alemán S...
"""
第二招是让模型先解释理由再给出答案。这个基本就是COT了。其中zero-shot的方法就是刚才提到的在prompt里加上Let's think step by step.这个方法的详情可以参考这篇论文。few-shot的方法我们在之前的文章里也介绍过,就是给几个思维链作为例子。
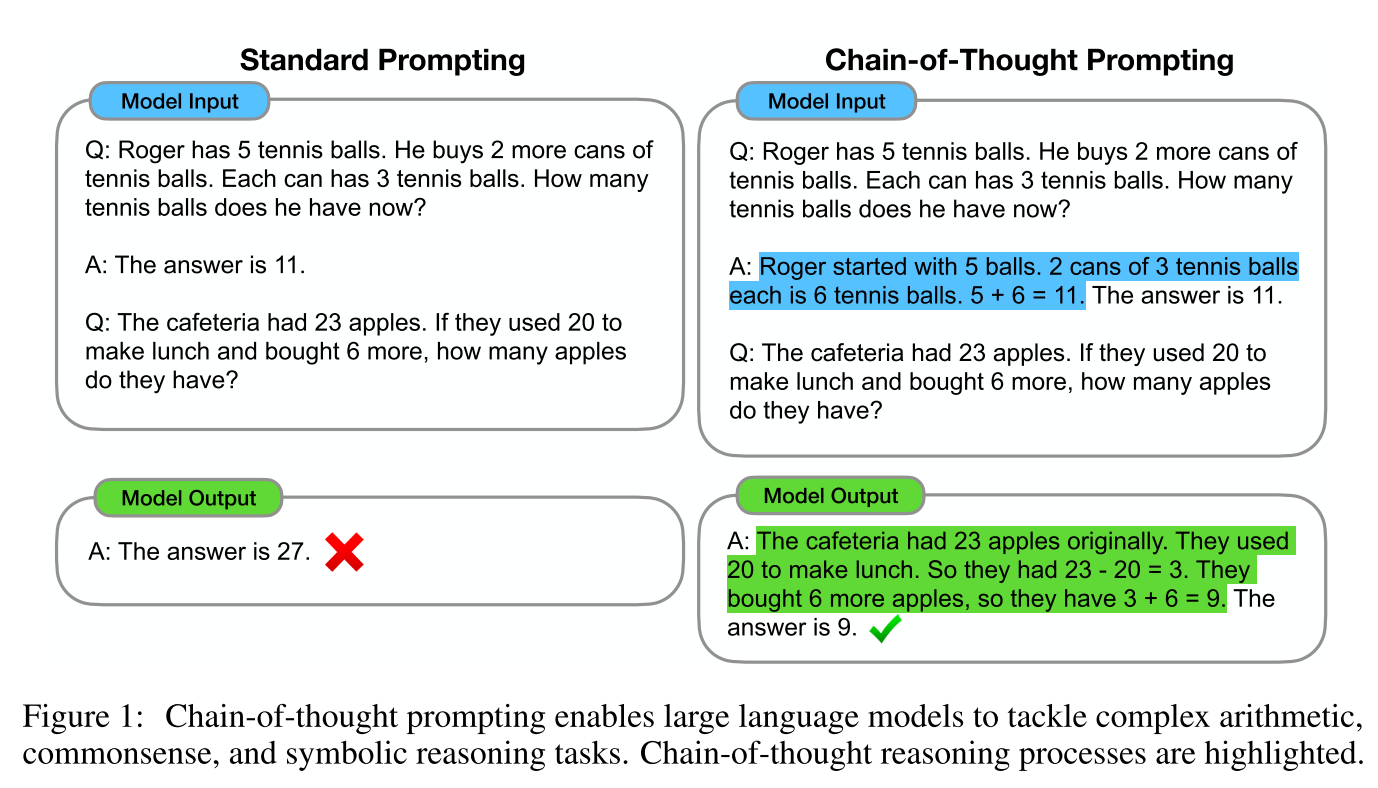
第三招是fine-tune模型,这个方法很机智,是用模型来产生一大堆COT prompt,然后保留能获得正确答案的prompt,用这些数据来训练数据。finetune毕竟比较重,本文就不展开了,详情可以参考这篇论文STaR: Bootstrapping Reasoning With Reasoning。
后面还有一些COT prompt的扩展,也令人大开眼界,但看后我感觉大部分学术味都比较浓,我只列举两个比较简单实用的。
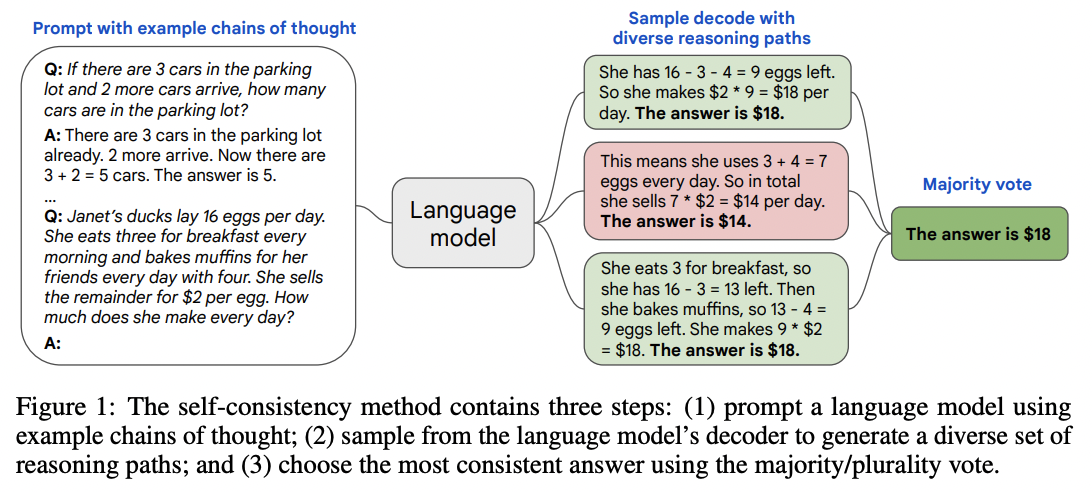
Self-consistency
这个方法很好理解,就是用一个稍高的温度(增加模型的随机性)进行多次采样,然后进行多数投票。
Verifiers
这个方法来自论文Training Verifiers to Solve Math Word Problems,适用于问题比较确定的场景,通过训练一个判别模型验证器,来选择合理的生成结果。
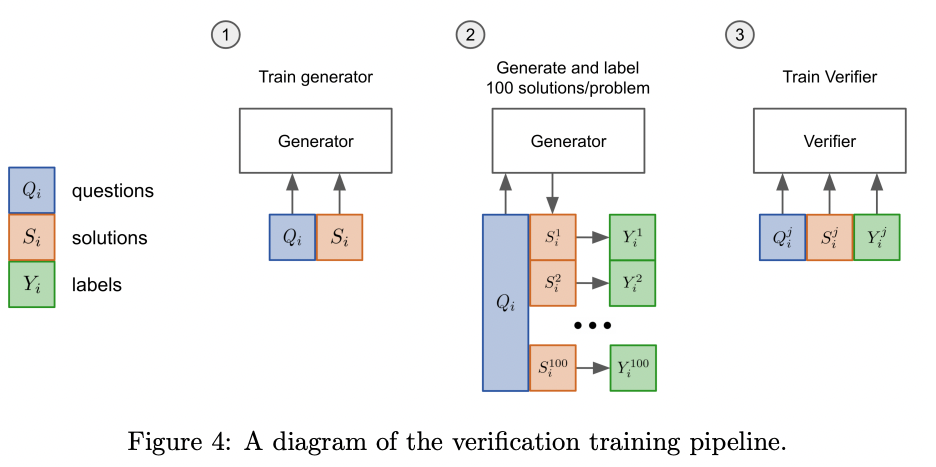
训练判别器的数据来源于多次采样生成模型加人工标注,实验显示,几千条样本就可以显著提高模型的准确性。
不管这些方法的prompt多花哨,其核心点就是两个
- 把难处理的问题分解成更小、模型更容易回答正确的问题
- 用多步推理或者多重关系来提升模型结果的准确性
今天先写这么多,祝大家happy prompting😁
关注公众号发送cookbook,可以获取项目地址哦。下一期聊一聊怎么用自己的数据强化大模型。