On March 1st, 2025, the sixth day of DeepSeek’s open-source week, they released something quite special - an introduction to the V3/R1 model’s inference system. Unlike the code repositories from previous days, this time it was a blog post. I haven’t read the article in detail, and I might not fully understand it anyway, but the Twitter post alone has already caused quite a stir.
DeepSeek resembles the OpenAI of two years ago, catching everyone’s attention. Whether you like it or not, OpenAI has been the pioneer, standard-bearer, and pathfinder in the AI wave these past few years, with groundbreaking early works like ChatGPT, GPT4, Sora, and O1. Just a few months ago, DeepSeek wasn’t even considered among China’s “Six Little Dragons,” but after R1’s release, it quickly gained widespread recognition. Last month, I studied their previous work, and the consistency is remarkable. Besides sticking to the MOE approach, they’ve prioritized efficiency from the very beginning. While people used to say OpenAI was all about brute force, which was difficult to replicate in China due to limited computing resources, DeepSeek has been focusing on achieving more with less - there’s an elegant engineering aesthetic to their approach.
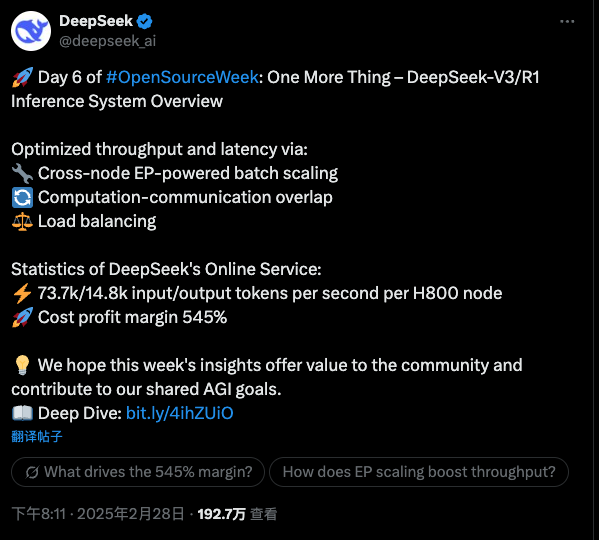
The open-source releases this week might not matter much to average developers, but today’s tweet, I believe, will profoundly influence the industry’s direction and, consequently, affect the general public.
First, it’s driving down AI prices - they’re selling at such low prices while maintaining a 500% profit margin, essentially printing money, which shows how much room there is for price reduction. Currently, DS API prices are ¥8 per 1M input tokens and ¥16 per 1M output tokens. For basic Q&A without RAG, I think 1M input/output tokens could last a high-end user half a year (Dream of the Red Chamber is about 1.2M Chinese characters, which roughly converts 1:1 to tokens - think about how long it takes to read that novel). In the coming year, these costs will continue to decline, possibly by a factor of ten, meaning the annual inference cost per user might be just a few RMB - practically negligible. This estimate might not be perfect, especially as inference models become more prevalent and output lengths increase substantially. However, the order of magnitude should remain similar.

Next comes the explosion of AI applications. If the above cost calculations are correct, every application will unhesitatingly add AI features, as long as AI can improve the product experience even slightly and won’t harm existing business models (unlike the slow-moving Google). When I previously heard about the AI application explosion, I imagined many “new” things emerging like a species explosion, but the rapid cost reduction might actually better benefit existing products improving their user experience. Another perspective is that selling models directly to consumers might not be good business, for several reasons: 1) Individual applications generate tiny transaction amounts - based on the above calculations, an average person might spend just a few RMB per year; 2) Switching costs between models are low - users will switch without hesitation when better or cheaper models appear, necessitating a product layer to create user stickiness; 3) For common applications, current models might already be good enough, making differentiation difficult. In loose terms, I believe it’s certain that AI will “surpass 90% of people in 90% of fields” this year. Considering both factors, focusing on applications seems more reasonable.
Then there’s the impact on many professions. When AI truly surpasses 90% of people in 90% of fields, the probability of widespread unemployment seems to be increasing. The tech-adjacent programming industry has already begun feeling this - new graduates in North America are finding it quite difficult to secure computer-related jobs. As AI capabilities improve, the impact will gradually spread from junior positions to senior roles, and from technical fields to other industries, especially high-hourly-wage knowledge-intensive positions like doctors and lawyers. Either reach the top 10% in your field, or it could be dangerous. Of course, this process won’t be overtly quick, as humans will create obstacles for machines.
The saying “there is nothing new under the sun” is terrifying - if there’s nothing new, it means everything could potentially be compressed into several hundred billion parameters.