昨天,也就是2024年2月22号,一早上起来就看到国内的AI公众号就热闹非凡,Google发布了他们的开源大语言模型Gemma,上Twitter也看到Jeff Dean卖力地再宣传自家的新产品:几条推文展现了好多令人兴奋的技术指标。
在上班前我先简单翻了翻技术报告,让我比较感兴趣的是256k的词表大小和6T的预训练语料。这俩改动加起来我估计应该性能确实会有一些提升。
最近Andrej Karpathy在YouTube上搞了个很火的讲Tokenizer的课程,应该也从侧面体现tokenizer和词表对现在的LLM性能之重要。我用Tokenizer Playground测试了一下LLama2和Gemma对同样文本的tokenize结果,可以发现Gemma的token数少了大概10%。当然,我测试的文本非常基础,全是ASCII字符,差距应该不那么明显,到了代码或数学场景(Gemma是做了digit分词的,数学应该强),差距应该就会显现出来。


我最近喜欢在面试的时候问别人vocab大小对于LLM性能的影响,从序列长度讲当然是词表越大越好,因为token序列会短,不仅生成时的步数会少,每一步O(N^2)的self attention也会有不少的提速。但output layer和embedding table都会变大,所以最终的速度变化不太好说。
这个Gemma模型说是2B和7B,但其实参数量是偏大许多的,7B版本的参数加起来已经8B多了,谷歌这次为了“挽尊”特意把表格分成了embedding parameter和non-embedding parameter,确实略显诡异。
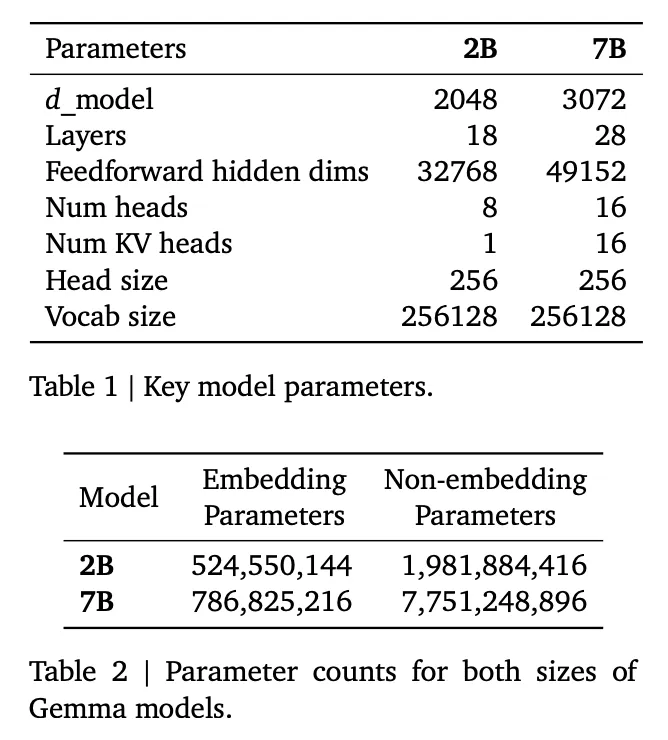
结构的设计也比较奇怪,intermediate hidden size特别的大,和”同参数量“llama比起来层数有所降低。我特意整理了下表,大家可以更清楚地看出两者的变化。我这个表是从huggingface权重repo的config.json来的,feedforward dim竟然和tech report不一样。这次Gemma还在每一层放了两个normalization,激活函数也和llama不一样,用了GELU。
| Gemma-7b | Llama2-7b | |
|---|---|---|
| vocab size | 256000 | 32000 |
| hidden size | 3072 | 4096 |
| embedding params | 786M | 131M |
| layers | 28 | 32 |
| attention heads | 16 | 32 |
| head dim | 256 | 128 |
| intermediate size | 24576 | 11008 |
| activation func | GELU | SwiGLU |
技术报告里列了一大堆让人眼前一亮的指标,基本意思就是7b可以干llama-13b。但现在我感觉这些指标和实际好不好用关系并不是那么大,看看就好。当然此时的我预期Gemma7b应该还是要好过llama2 7b的。

到了办公室赶紧就开始在我们的数据上finetune了一下。选的7b版本,huggingface已经贴心地把它整合进各种库里,transformers升级到4.38以上就行。我先试了下llama2-13b一样的超参,发现eval loss差了不少,而且新版transformers会计算grad norm,这个值在训练初期有很大的波动,一度达到上百的量级,感觉训练不是特别成功。后面我又换用了一组比较小的学习率,比之前有所提升,但eval loss还是和llama13b有差距。
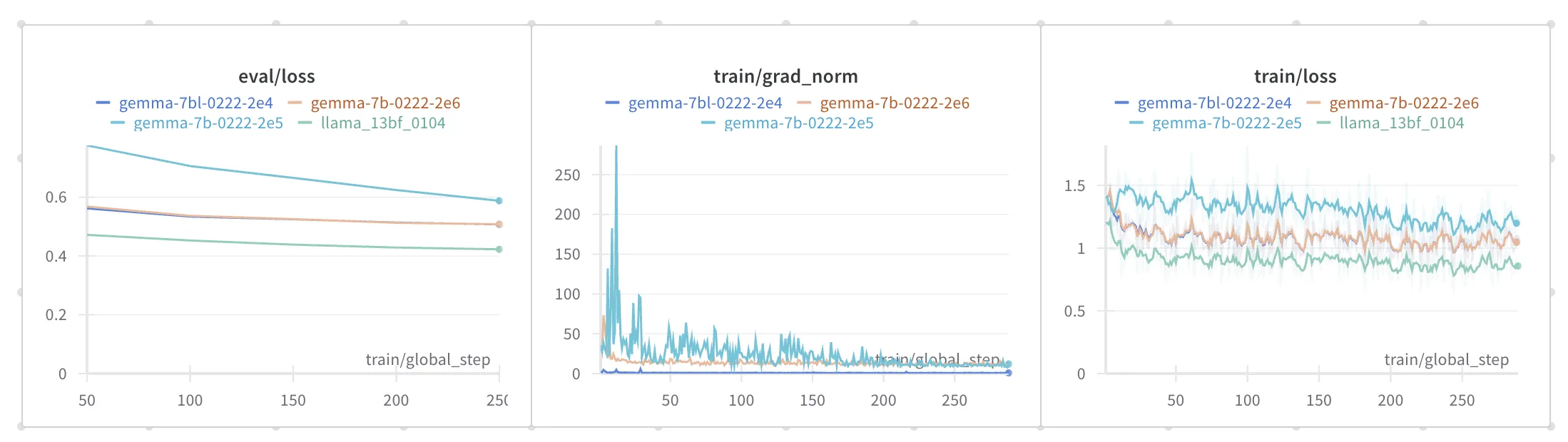
不过不同模型特别是词表量级相差如此巨大的模型间eval loss不太好比较(直观感觉是词表大的loss水平应该要高一些),只好用一些业务指标来比。我用一些测例推理了一下模型,发现学习或者推理过程应该是出了些问题。虽然eval loss在合理范围,但生成的文本基本不可用。
而且,Gemma7b的训练显存消耗比llama2-13b还大,同样的deepspeed配置我只能跑原来一半大小的batch。Gemma虽说参数约为8b,但肯定比13b小不少,出现这种情况我也比较费解,欢迎大佬点拨。

总体感觉目前的Gemma版本有一些问题,看看过几天社区会不会发现并修复它。也希望真的能有个能超过llama2-13b的7b模型可以用。当然,我最希望的还是llama3赶紧出来吧😂