越来越多人发现Gemma 难以 finetuned的现象了。今天在 Twitter 逛就看到好几个相关帖子。
下面这个老哥是 Dolphin 和 Samantha作者,应该算有经验的开发者,直接搞了一个 200 多的 loss 出来。
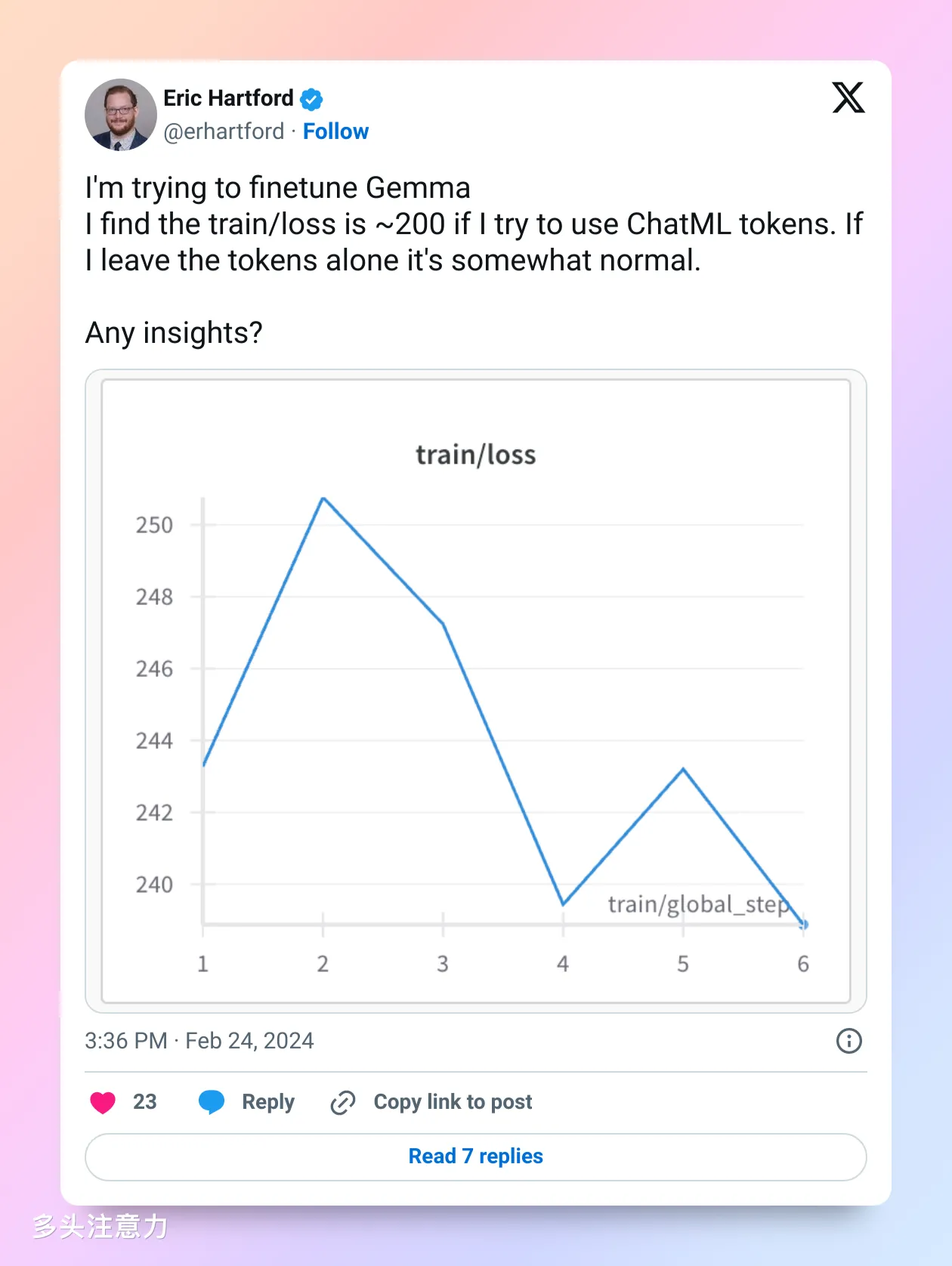
后面他们发现可能是新加 token 导致的问题。finetune 时如果新加 token 必须训练 embedding,对于 lora微调来说默认是不训练这组参数的。老哥把新 token 去掉之后正常了。如果是像我一样的全参微调压根不会碰到这个问题,Lora 看起来还是在社区里占据了更主流的位置。
Teknium 也是 finetune 达人,上来loss 也很高,但后面慢慢降下去了,原因也是他加了新 token。
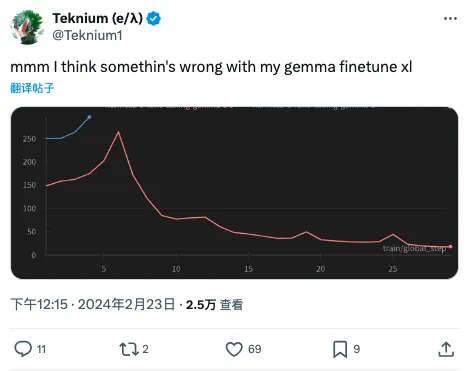
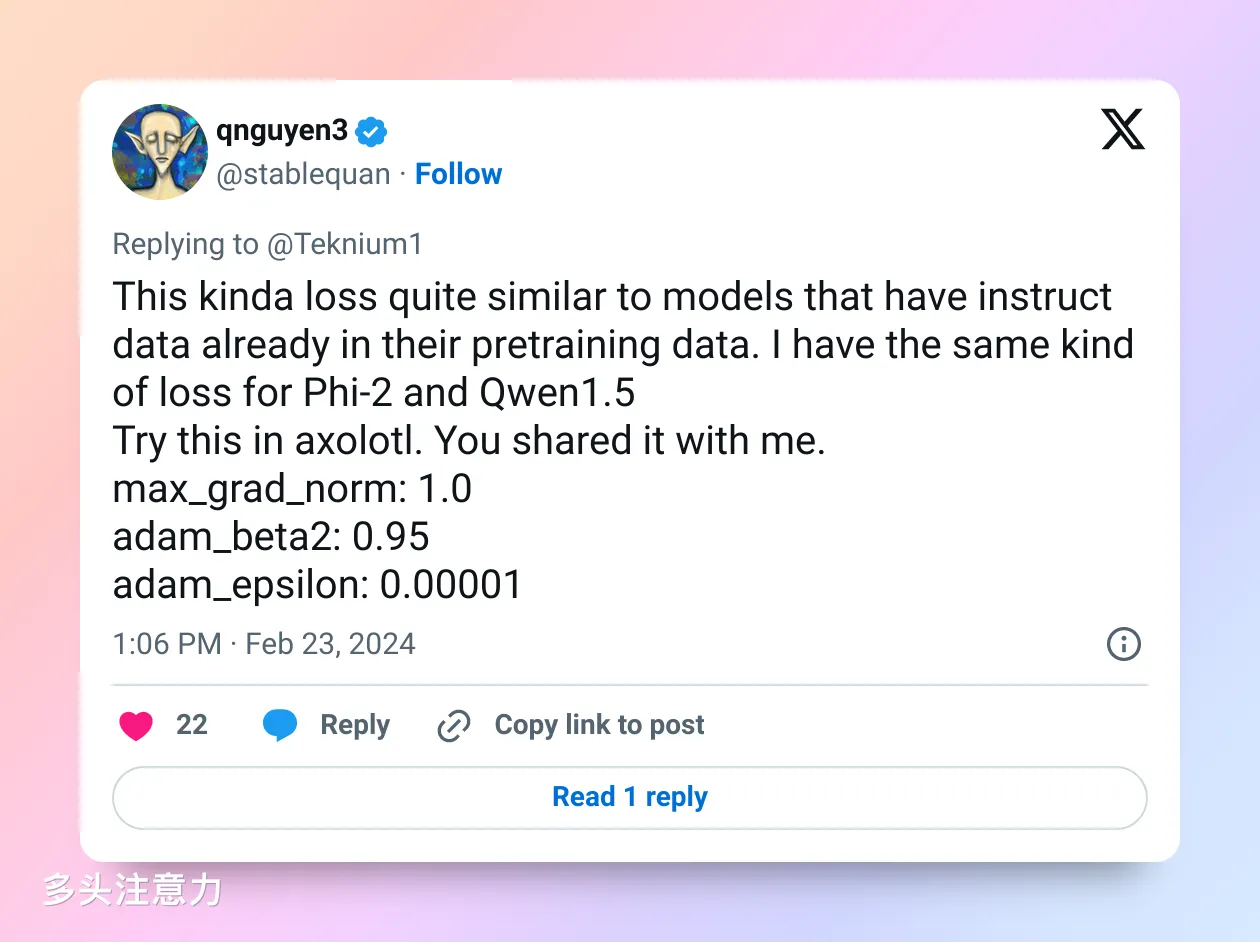
回帖里有个老哥(之前是 OpenAI 员工哦)说可能是 pretrain 数据里有 Instruct 数据,顺带提了一下 Phi-2 和 Qwen 1.5。当然这都只是猜测,语料里有啥已经是大模型界最深的秘密。不过这种做法确实让人讨厌,基座就好好做通用语料训练,别搞指令数据。这么一搞下游训练容易遇到麻烦。我之前试过 Qwen 和 Baichuan,虽然他们的 benchmark 成绩都很好,但finetuned 的表现确实不如 llama2 好。Qwen 1.5最近倒是看到有不错的微调版本在 leaderboard 上排名不错。
这老哥还提供了一组超参数说值得一试。max_grad_norm 在 HF trainer 里默认就是 1,adam beta2 默认是 0.999,降低到 0.95 会让梯度的变化更敏锐一些。至于 epsilon,我一直感觉没什么可调的,1e-8 和这里的 1e-5 应该差别不大。
另一个老哥则遇到了和我一样的高显存占用问题。他猜是 MLP 和 embedding 太大导致的。他这个情况和我不一样,他在用消费级显卡推理,我之前是用 A100 deepspeed 多卡训练。我怀疑是 deepspeed 的参数没设置好,导致 PP 效率变低,最终让每个卡(或者某个卡)的占用变大了。不知道有没有 deepspeed 大佬来点拨一下。
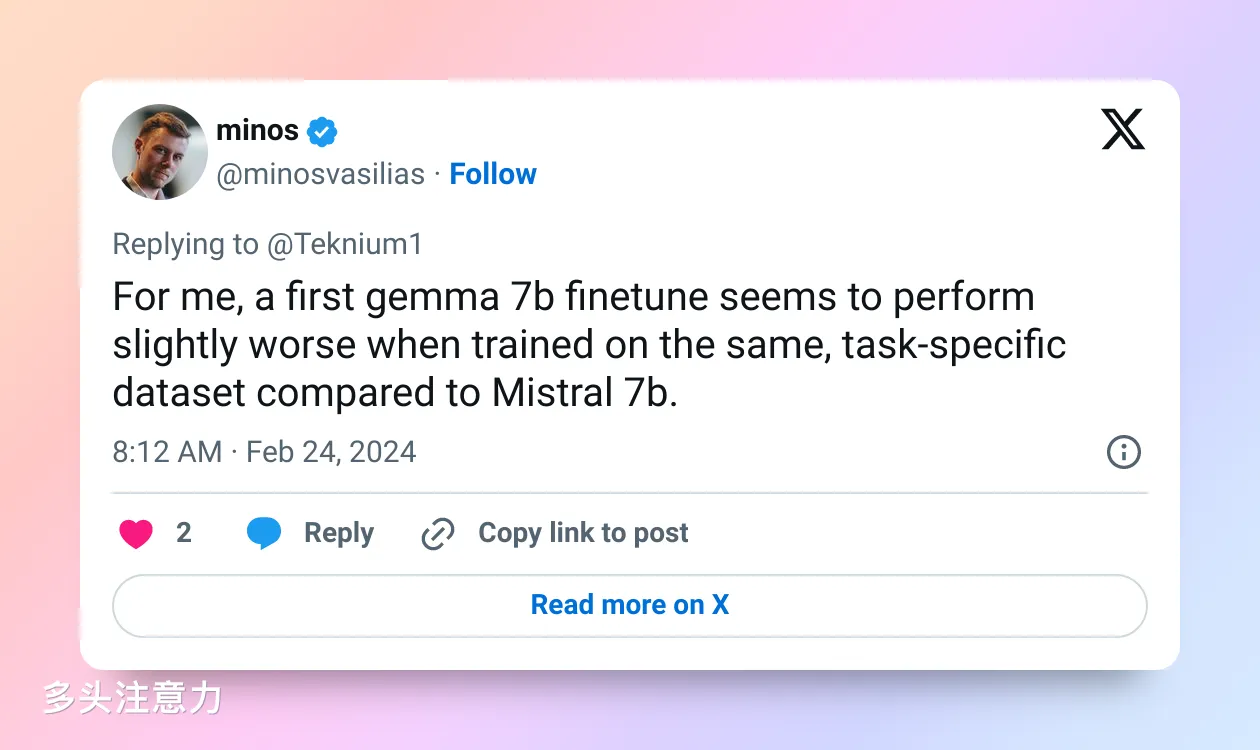
也有一些人 finetuned 成功了,但发现 Gemma 的效果并不比 Mistral 好。
还是上次那句话,LLama3 赶紧出来吧。