最近在学习一个奇特的技术,叫做生成式检索。生成式检索是一种利用生成式语言模型的全新信息检索方法。不同于依赖外部索引的传统方法,生成式检索利用单个强大的模型来处理查询和文档语料库。在这个注重推理能力,讲agent的年代,生成式检索却走到了让模型“死记硬背”的另一个极端。
生成式检索用简单的话来说,就是对于输入查询(query),让模型直接生成出语料库里相关文章的id,是的,你没有看错,是直接生成id!当然,这就会涉及到一个很重要的问题——id长啥样?当前的主流做法有几种:
- 原子id(atomic id),即每篇文章用一个独立的token来表示。这实际上是挂羊头卖狗肉,说是生成式,但因为每个文章都有独立token,所以等价于一个分类问题。
- 朴素id(naive id),即id是一个字符串,这个字符串没什么特别的,就是id常用的形式,可能是
12345这样的数字串,也可能是apdkcr这样的hash串。然后模型在推理阶段是用自己的词表生成出这个id字符串。因为id没有明确含义,这种做法着实是挺难为模型的,相当于问一个人“为人民服务”出现在毛选的第几卷第几本第几页第几行第几个字。 - 语义id(semantic id)。和2一样,这里的id还是一个字符串,不同的是这个id是要包含语义信息的。这个大类有很多细分的做法,我列两种比较有代表性的。
- 直接生成URL。是论文Large Language Models are Built-in Autoregressive Search Engines里的做法。他们讨论的语料是维基百科,页面的url包含非常明确的页面主题信息。这种做法是比较符合大家对生成式模型的直觉的,生成目标也不局限在URL,tag、category都可以使用。
- 层次聚类。该领域经典论文Transformer Memory as a Differentiable Search Index的做法。是将大的语料库用embedding进行层次聚类,直到簇的大小符合要求。这样就把语料库转换成了一棵检索树,文章的id就是从根到叶子的一条路径。虽然还是数字id,但相比于一个自增或者随机的数已经结构化了很多。
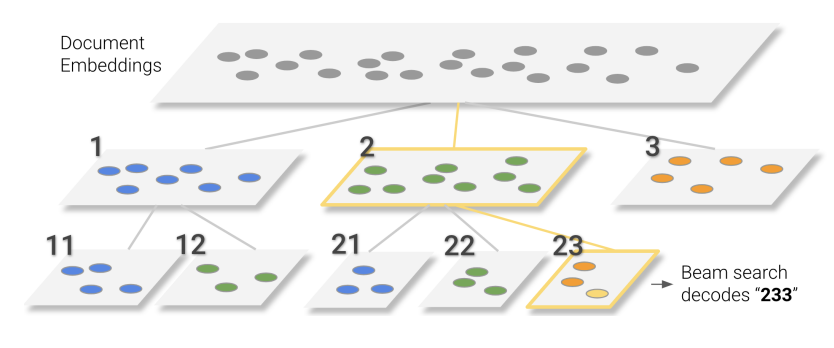
说完了id的问题,另一个重要问题是怎么让模型记住这么多id?方法也很土很暴力,就是搞一堆(query, docid) pair 让模型学就完了。如果这种数据不够,那有一些方法合成,比较典型的有:
- DAQ(Document as query):通常是在文章里取一截内容做query。
- D2Q(Document to query):再搞一个模型根据内容生成一些可以回答的问题。
显然D2Q搞出来的数据更有可能接近使用场景的真实数据,所以效果好很多。D2Q其实不是什么新方法,四五年前就有人在IR任务里拿来增强模型。这两种方法都可以产生大量的训练数据,让模型充分死记硬背。
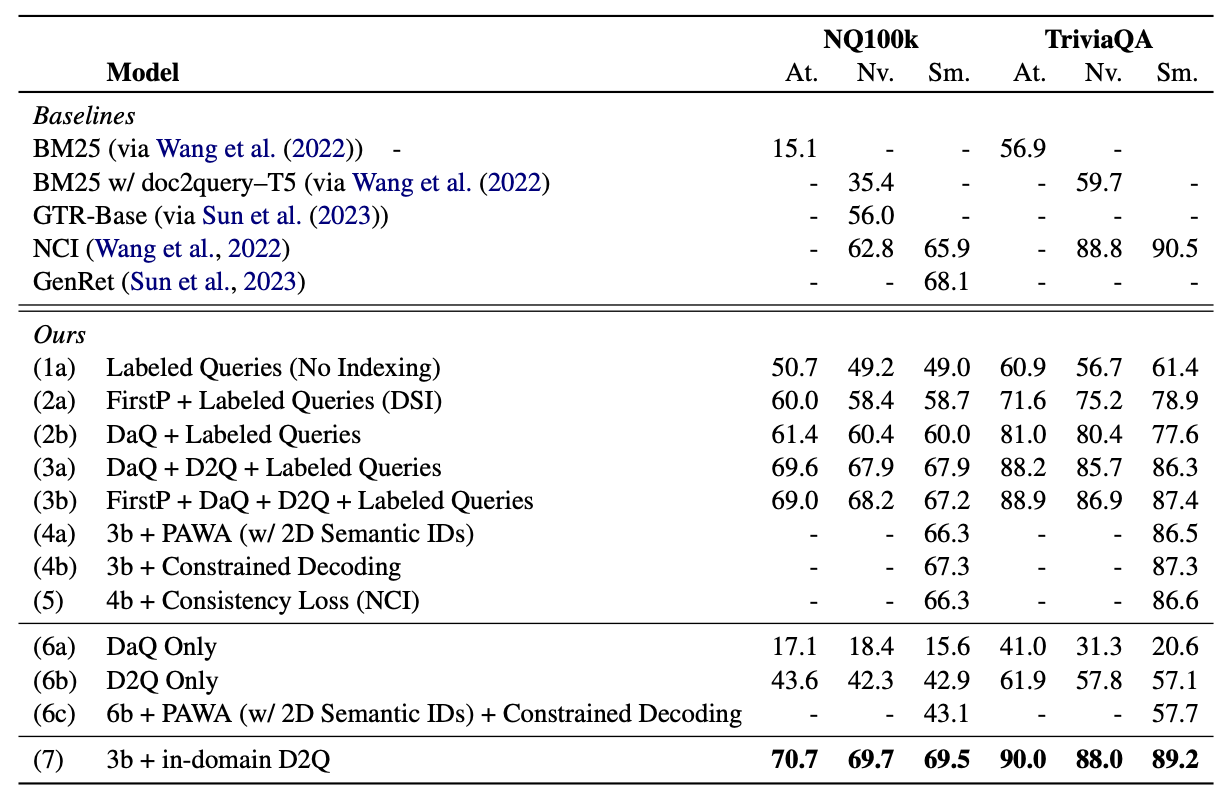
最后看下这种方法的效果和问题。
根据这篇论文的数据,在语料库不大(100k左右)的情况下这个方法还是表现不错的,可以超过bm25和经典的dual encoder+ann。但不得不说,这个成本可不低,100k文档的训练数据可能是4-5M条,要跑一会。
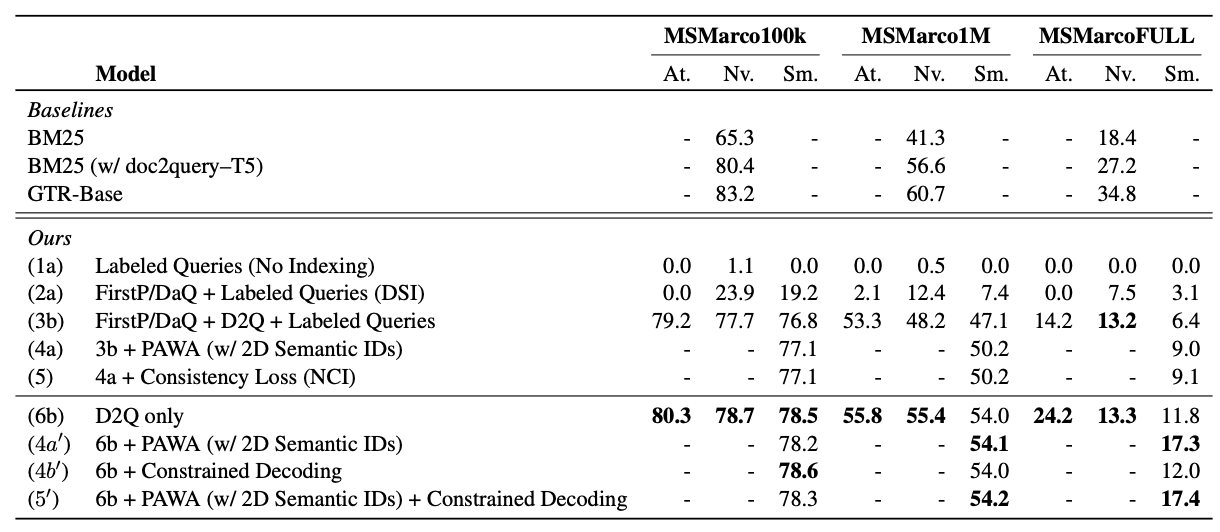
但当检索范围变大,这种方法的效果下降非常明显。这个结论也不意外,背几首古诗和背新华字典的难度肯定不同。很快就差于经典的召回方法了。
另一个明显的问题是死记硬背导致的新文档更新问题。当语料库里增加新的文档之后,模型要重新训练,速度慢不说,效果还可能有各种问题。也有不少文章专门也就这个问题。
以上就是对近期学习的一个简单总结。总的来说这个东西学术味道浓了一些,实用价值在现阶段应该还不大。但确实难说后面会不会有跟LLM结合的点。更多相关内容可以看这个Github Repo。