今天微软发布了 Phi3 模型,3.8B 的小体量做到了 Mixtral-8x7B 一样的效果,在社区引起了不小的轰动。
我前段时间曾经试过finetune Phi2 模型,效果说实话并不是很理想,默认 context 只有 2k 更是让他难以胜任很多生成式的任务。 今天发布的 Phi3 context 做到了 4k,还有长上下文的 128k 版本,至少在这块已经补上了短板。 其实 Phi 家族一直是 LLM 领域蛮有个性的一套模型,今天也趁机梳理了一下他们的发展脉络。
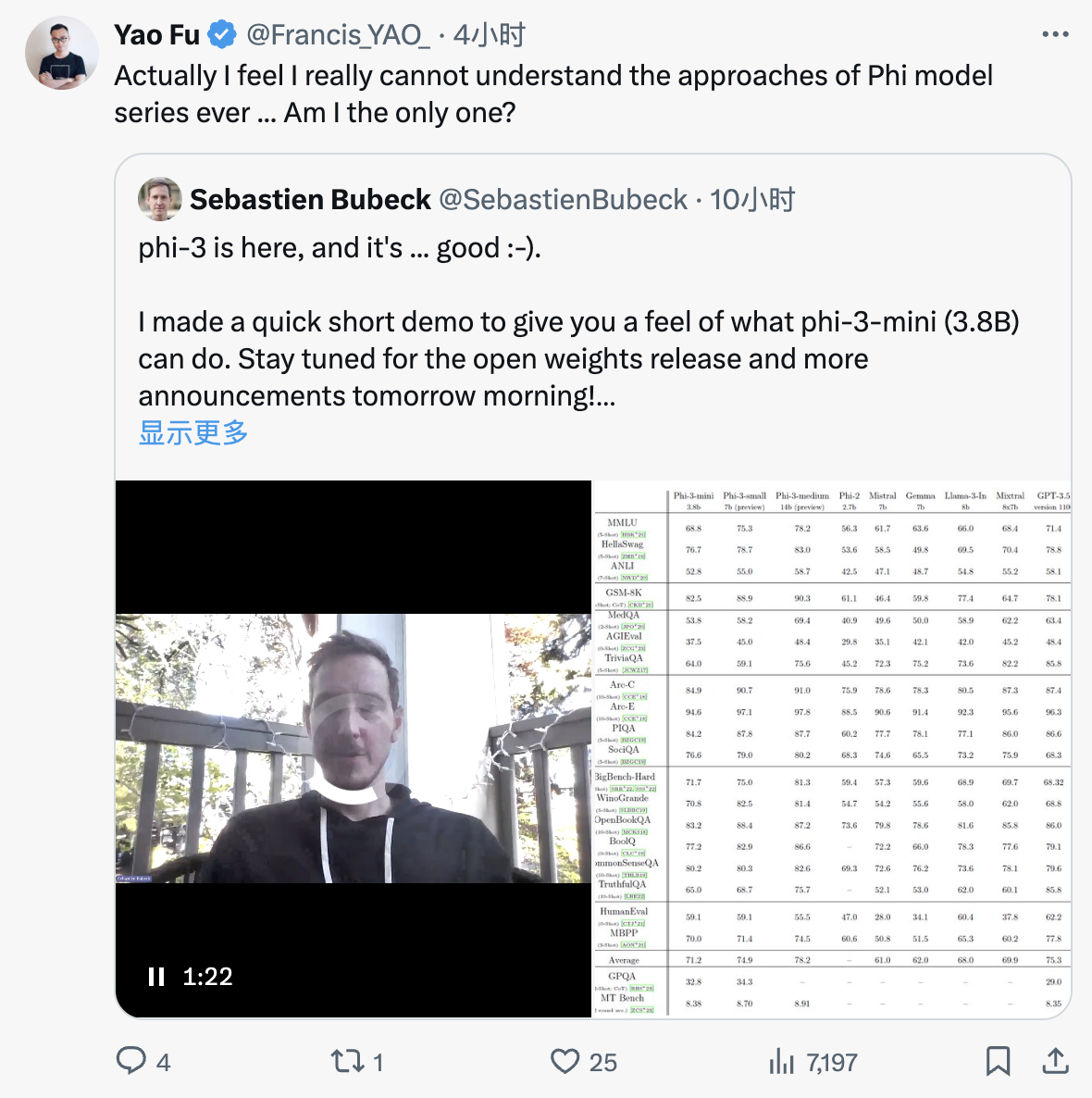
我们倒过去看,先总结一下今天发的最新版 Phi3。Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone的几个重点如下:
- 模型尺寸有3.8B,7B,14B,3.8B 性能已经不错,量化后 1.8G 在 iPhone16 上一秒可以出 20 个 token
- 3.3T token 训练,更大的模型用了4.5T。这个比 llama3 的 15T 少的多
- 训练分两阶段。第一阶段用高质量网络数据,第二阶段用更强力过滤后的一阶段子集加 GPT 合成数据。第一阶段学语言能力和常识,第二阶段主要学逻辑推理能力。
- 除了语言模型还发不了 SFT+DPO 的版本
Phi2 是23 年 12 月发布,只有一个 2.7B 的版本,没有对应的技术报告。从 Model Card 上可以看到主要是按 Phi1.5 的路子进行的训练,增加了一个新的数据来源。 这个新数据源包括过滤后的网络内容和大量的 NLP 合成文本。
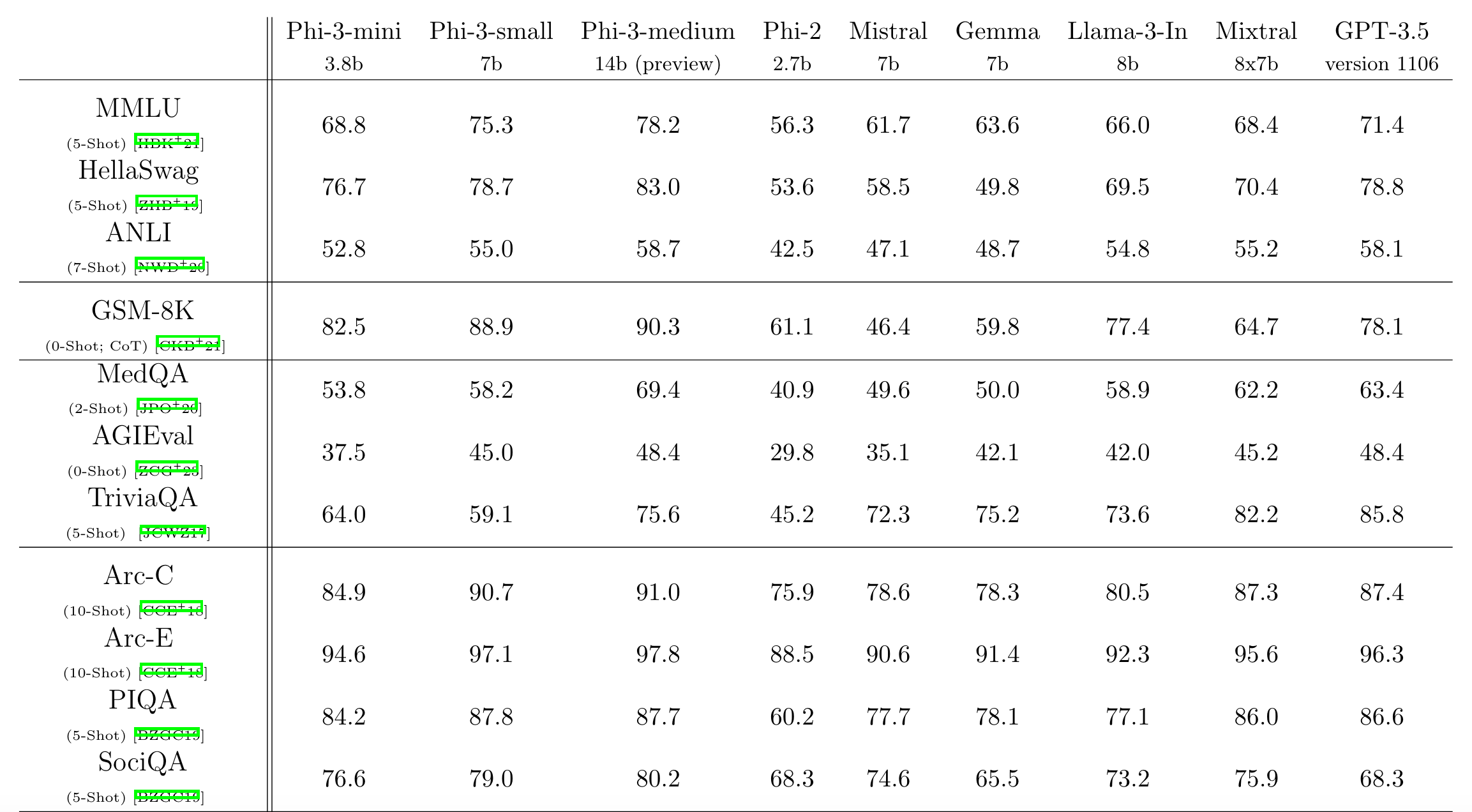
Phi-1.5是 23 年 9 月发布,技术报告的标题叫Textbooks Are All You Need II: phi-1.5 technical report。Phi1.5 其实有两个版本,如下图所示,web 版除了合成数据还增加了 web 数据。总的数据量不大,只有 30B 和100B 和,靠多训练几轮来增加训练 token 数。非 web 版里只有 6Btoken 的代码数据不是合成的。

报告里有一段话
We remark that the experience gained in the process of creating the training data for both phi-1 and phi-1.5 leads us to the conclusion that the creation of a robust and comprehensive dataset demands more than raw computational power: It requires intricate iterations, strategic topic selection, and a deep understanding of knowledge gaps to ensure quality and diversity of the data. We speculate that the creation of synthetic datasets will become, in the near future, an important technical skill and a central topic of research in AI.
翻译成中文如下。基本是 Phi 系列工作的精髓所在。
我们注意到,在创建phi-1和phi-1.5的训练数据过程中获得的经验使我们得出结论:创建一个健壮且全面的数据集需要的不仅仅是原始的计算能力:它需要复杂的迭代过程、战略性的主题选择,以及对知识空缺的深刻理解,以确保数据的质量和多样性。我们推测,创建合成数据集在不久的将来将成为一个重要的技术技能和人工智能研究中的一个核心话题。
Phi1.5 还做了一个 web-only 的模型,即只用 web 数据训练。这个 web 数据基本上是从 Falcon 的数据集上过滤得到的。结果也很有意思,即使只用了 Falcon 数据集的子集,但效果却比 Falcon 好,合成数据的版本也比只用 web 的好,同时使用高质量 web 数据和合成数据的模型效果最好。
再往前看就是 Phi1 了,23 年六月发布。技术报告的题目叫Textbooks Are All You Need 。Phi1 模型参数 1.3B,8个 A100 训练 4 天就能完成。这个模型完全是个写代码的模型,用了 6Btoken 经过强力清洗的网络数据和1B 由 GPT-3.5 生成的合成数据训练而成。
清洗数据用先用 GPT4 对小部分数据的质量进行了打标,然后用这些数据训练了一个分类器,并大规模对数据质量进行评估。 生成的数据主要是代码教学,还有小部分编程练习。论文里还特别强调,虽然编程练习的 token 数不大,但对模型性能的提升很重要。
从 4 代 phi 模型来看,首先比较明显的感受是 technical report 越来越水了。基本只有 1 和 1.5 对怎么做数据讲得比较清楚。3 其实根本没细讲怎么做的数据,只知道数据量比之前大了。梳理一下可以更清楚看到
- Phi-1.5-web 是 100B token,其中大概 70B 是 web 数据,MMLU 是37.9;
- Phi-2 是对 1.5 的一个扩充,但没讲具体多少 token,MMLU 是56.3;
- Phi-3 的 token 量已经到了 3.3T,相比于去年的 1.5 已经涨了 33 倍。MMLU 来到了68.8.
所以在强调数据质量的同时,数据量也是相当关键的。
现在模型结构早已不是什么秘密,数据是唯一的护城河。各家团队就在互联网这大大的花园里挖呀挖呀挖,看谁能搞到更多的高质量数据。今天看到篇文章说其实能挖的已经不多了,所以估计模型的进步后面也会趋缓。互联网挖完之后,估计改掀起另一波电子化浪潮,把目前还躺在图书管理的纸质内容都搞成训练数据。
以上就是对 Phi 系列模型的简单梳理。