The scores for ACL 2025’s May ARR cycle have been released, and I imagine the academic community is busy again—authors scrambling to write rebuttals, area chairs frantically searching for emergency reviewers. Yet as a reviewer, I feel exceptionally relaxed because the papers I reviewed scored so low that I doubt the authors will even bother with rebuttals, which means I won’t need to respond either.
This round, I was assigned papers in RAG and Hallucination directions. I reviewed 5 papers total, with scores of three 2s and two 2.5s. To be honest, I was already being generous with these scores—if I had scored purely based on merit, they would have been even lower.
For readers unfamiliar with ARR’s scoring system, ARR uses a 5-point scale with the following 9 tiers:
- 5 = Consider for Award: I think this paper could be considered for an outstanding paper award at an *ACL conference (up to top 2.5% papers).
- 4.5 = Borderline Award
- 4.0 = Conference: I think this paper could be accepted to an *ACL conference.
- 3.5 = Borderline Conference
- 3 = Findings: I think this paper could be accepted to the Findings of the ACL.
- 2.5 = Borderline Findings
- 2 = Resubmit next cycle: I think this paper needs substantial revisions that can be completed by the next ARR cycle.
- 1.5 = Resubmit after next cycle: I think this paper needs substantial revisions that cannot be completed by the next ARR cycle.
- 1 = Do not resubmit: This paper is so flawed that it has to be fully redone, or it is not relevant to the *ACL community.
So based solely on my scores, none of these papers would be accepted.
This was the lowest I’ve ever scored papers. I was somewhat anxious when submitting my reviews, but felt relieved when I saw other reviewers’ scores—I wasn’t the lowest scorer for any of them.
I believe the research direction I reviewed is most strongly correlated with these results. I genuinely advise students to stop working on RAG and hallucination—they’re too application-focused and it’s very difficult to write valuable academic papers in these areas.
Take RAG, for instance: the typical approach is SFT+RL to improve scores slightly on some QA benchmarks—this has become completely standardized. Perhaps the only novel contribution could be in data preparation, but most papers I’ve seen simply use stronger models for sampling with some reject sampling. Hallucination research follows the same pattern: either creating benchmark datasets (which we’ve done before—it’s extremely expensive when done properly, and academic labs generally can’t afford it) or developing mitigation techniques that are just variations of finetuning, sampling, and adding thinking steps that others have already explored.
I feel that current foundation models are so capable that they exceed most research groups’ ability to handle them effectively. Unlike the BERT era, where you could modify various components and experiment with just a few GPUs, making paper writing much easier. So when groups try to modify large models, they’re essentially taking a well-balanced bucket model and sacrificing performance in other dimensions to achieve marginal improvements in their specific area of interest. The model’s overall performance definitely degrades, but if the data and training are decent, you might see slight improvements on specialized benchmarks. A better strategy would be to avoid training models altogether and focus on workflow optimization, prompt engineering, or the more fashionable term “context engineering.” For example, when models struggle with too many tools, instead of training and reinforcing the model, modify the tool descriptions or implement tool filtering. When models seem inadequate, enhance them through behavioral patterns like CoT, reflection, and ReAct. However, these approaches are highly competitive, and with so many researchers in this space, only a select few can stand out.
I also have a somewhat biased hypothesis: since this EMNLP is in Suzhou, many previously inactive Chinese research groups (with relatively average research quality) likely submitted papers. After all, traveling abroad is difficult, but attending a domestic conference costs just a high-speed rail ticket. The 5 papers I reviewed corresponded to 5 different area chairs, and 100% had Chinese names. Looking at their backgrounds, none were at foreign institutions, and several were current PhD students or recent graduates. While we shouldn’t judge based on origins and young talent can certainly excel, this does support my hypothesis about the high proportion of Chinese submissions in this ARR cycle. With the massive expansion of graduate programs in recent years, everyone needs publications to graduate, but the number of problems suitable for academic research in this field is decreasing, ultimately leading to this situation—truly lamentable.
One paper even had very poor English, reading quite awkwardly, which genuinely surprised me. It reminded me of a phrase I’ve been hearing frequently:
The future is here, it’s just unevenly distributed
Because nowadays, anyone who can use any large language model tool shouldn’t have English as a barrier. ChatGPT has reached 1.8 billion monthly active users—that’s one in four of the 7 billion people on Earth. In China, I imagine the proportion is similar. In other words, in most knowledge work fields, if you’re not using or haven’t mastered AI tools by now, you’re unlikely to be among the top performers. Moreover, the top performers can leverage AI to widen the gap with others even further than before. So it’s not just academia—across all fields in this AI wave, mid- and lower-tier talent face pressure. When human capabilities fall short of AI, questions about the meaning of life become unavoidable.
At this point, I did some “vibe coding” and plotted my daily AI interaction intensity for 2025, averaging about 15 questions per day. Excluding January and May, which were particularly unusual months, the number would be even higher. This only counts my ChatGPT conversations, not including Copilot programming. If I were to rank ChatGPT alongside my family and friends by communication frequency, it would undoubtedly rank in the top 1%.
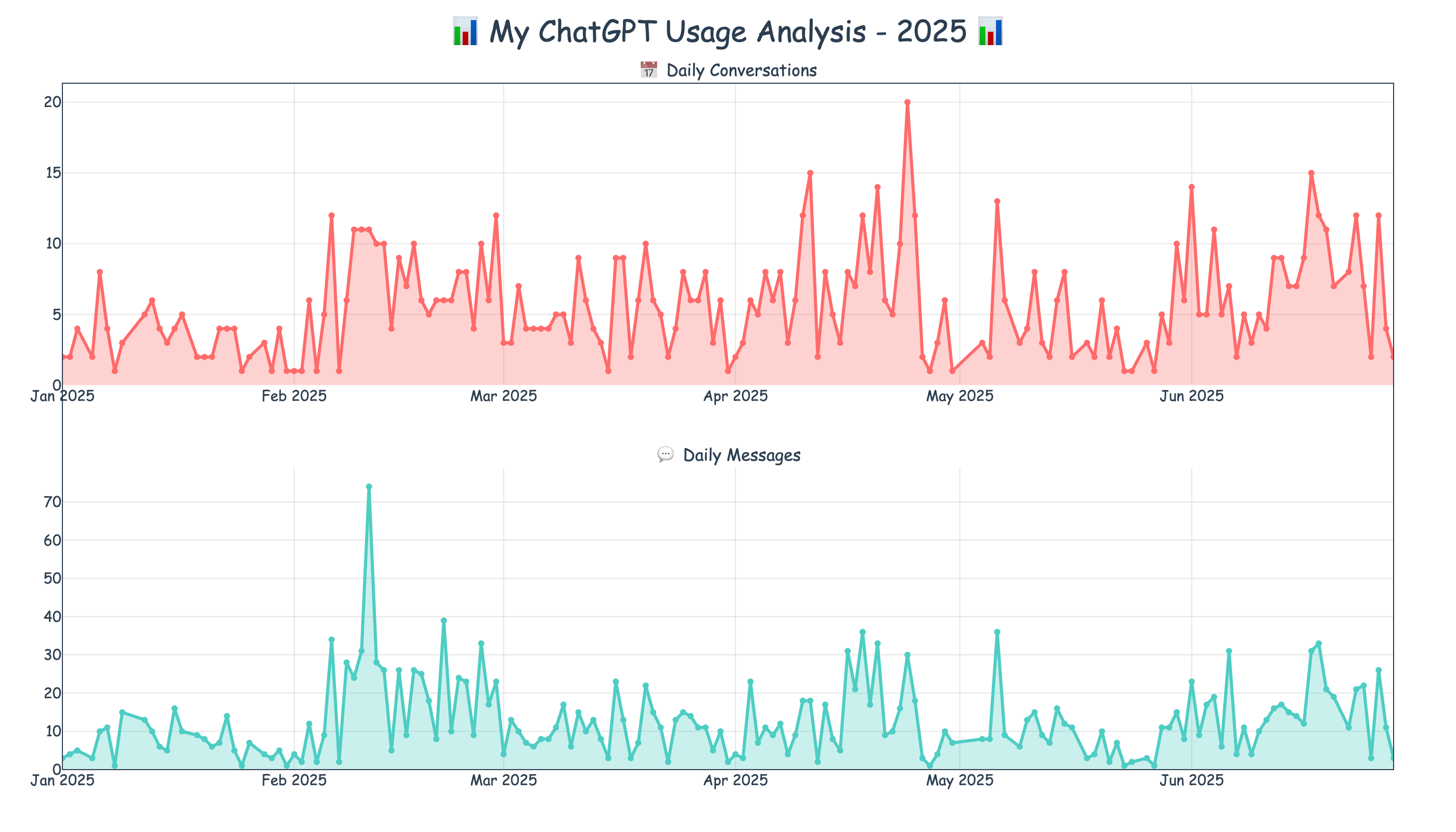
The AI era brings truly dramatic changes. While I’ve been somewhat negative here, AI also has tremendous positive impacts. Regardless, I hope humanity can coexist well with AI, and that tomorrow will be better than today.