ACL 2025年5月的ARR cycle已经出分了,估计这会儿学术圈又忙起来了,作者在忙着写rebuttal,AC在忙着找紧急审稿。而我这个审稿人却感觉格外的轻松,因为这次看的论文分都太低了,估计作者都不会来rebuttal,自然我也不用再回复作者。
这一次给我分的都是RAG和Hallucination方向的论文,我一共审了5篇,打分情况是3篇2分,2篇2.5分。说实话,总体上我已经抬一手了,全凭良心打的话,还要更低一点。 给不熟悉ARR评分标准的读者稍微补充一下,ARR是5分制,分以下9档:
- 5 = Consider for Award: I think this paper could be considered for an outstanding paper award at an *ACL conference (up to top 2.5% papers).
- 4.5 = Borderline Award
- 4.0 = Conference: I think this paper could be accepted to an *ACL conference.
- 3.5 = Borderline Conference
- 3 = Findings: I think this paper could be accepted to the Findings of the ACL.
- 2.5 = Borderline Findings
- 2 = Resubmit next cycle: I think this paper needs substantial revisions that can be completed by the next ARR cycle.
- 1.5 = Resubmit after next cycle: I think this paper needs substantial revisions that cannot be completed by the next ARR cycle.
- 1 = Do not resubmit: This paper is so flawed that it has to be fully redone, or it is not relevant to the *ACL community.
所以如果只看我的打分,没有一篇文章会被录用。
这是我打的分最低的一次,我提交的时候还有点忐忑,但是看到其他审稿人的打分就释然了,因为每一篇我都不是打分最低的。 我感觉和这个结果关联最大的就是我审稿的方向。真的劝各位同学别再做RAG和幻觉的方向了,太偏应用,其实很难写出有价值的学术论文。
比如做RAG,上来一套SFT+RL,在一些QA Benchmark上提高一点分数,都是太标准化的操作了。可能唯一能写的就是怎么准备的数据,但是大部分看到的论文无非就是拿比较强的模型来采样,做点reject sampling。幻觉也是一样,要么做benchmark数据,但这个我们做过,正经做成本非常高,学术界一般玩不起;要么做一些mitigation,也无非是finetune、采样、加thinking这些早已有人做过的事情。
我感觉现在基础大模型的能力太强了,应该是超过绝大部分研究组的驾驭能力的。不像之前bert时代,各个环节都可以魔改,几张卡也能玩得动,写文章容易很多。所以大家如果试图改变大模型,其实就是把原来一个能力比较均匀的水桶模型,以牺牲其他维度性能为代价,在自己关心的维度上做一些提高。模型的总分肯定是变差了,但如果数据和训练还可以,有可能在专门的benchmark上提一点。所以更好的策略其实是不要训练模型,就搞一些流程优化,搞prompt engineering或者现在更时髦的说法context engineering。比如工具多了模型用不好不是去训练和强化模型,而是去改工具的描述或者做工具的筛选;再比如模型太笨,就通过CoT、reflection、ReAct这种行为模式来提升。但是这些工作很拼手速,现在这么多人研究这块,也只有很少数的人可以脱颖而出。
另外我有个屁股不太正的猜测,因为这次EMNLP在苏州,会有很多原本不活跃(科研水平比较一般)的中国课题组投稿。毕竟出国不容易,但是国内开会一张高铁票的钱还是出得起的。我审的5篇文章对应5个不同的area chair,100%全都是中国名字,看了他们的履历,无一是在国外机构,且好几个是在读博士或者博士刚毕业。虽说英雄出少年且不该问出处,但从一个侧面印证了前面这次ARR中国比例高的猜测。这几年研究生扩招规模这么大,大家都需要论文来毕业,但这个领域适合学术界的问题是在变少的,最后造成这种局面也确实令人唏嘘。
这次还有一篇文章的英语都很烂,读起来很不通顺,真的让我很意外。让我想起一句最近常听到的话
未来已来,只是分布极不均匀
因为现在但凡会用任何大模型工具,英语都不应该是一个问题了。ChatGPT的月活用户已经到了18亿,也就是70亿地球人,四分之一在用,我感觉在国内,这个比例应该也差不多。换句话说,在大部分知识工作领域,如果你现在还不会用或没有用好AI工具,你基本上不可能是最厉害的一拨人了。而且最厉害的一拨人能够借助AI把和后面人群的差距拉到比原来更大。所以不只是学术界,在这波AI浪潮中,各个领域的中低端人才都是受到挤压的,当人的能力不如AI,人生的意义问题就不得不思考了。
写到这里,我vibe coding了一把,画了一下2025年每天跟AI的交流强度,平均下来大概每天要问15个问题。如果去掉1月和5月两个比较特殊的月份,还会更高。这还只是我跟ChatGPT的对话,没有算上copilot编程。如果把ChatGPT跟我的家人朋友一起做个排序,应该它可以毫无疑问地排进交流最频繁的前1%。
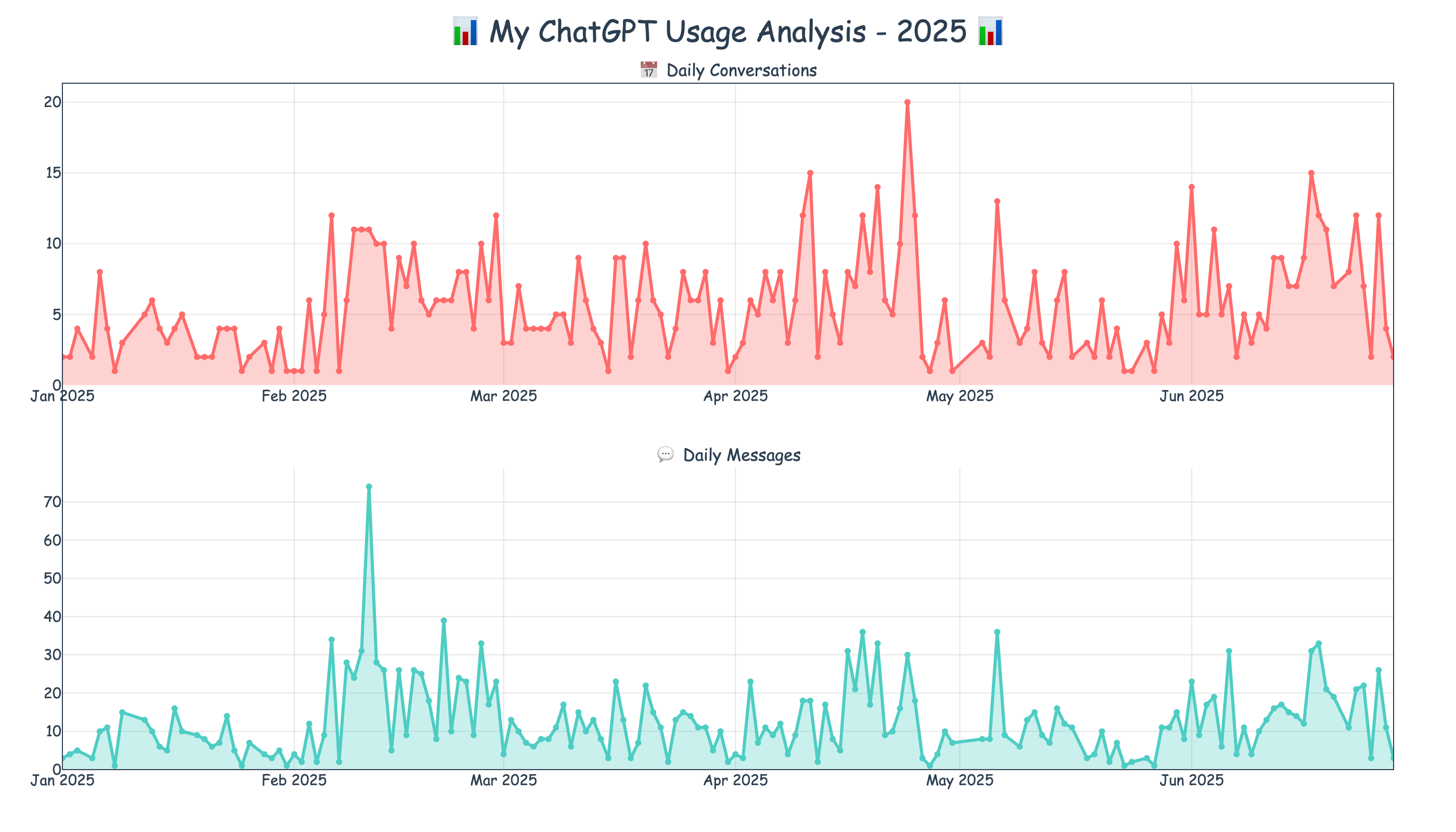
AI时代,变化真的剧烈,虽然这里啰啰嗦嗦讲的基本是负面的事情,但AI也有太多正面的影响。不管怎么样,希望人类能很好地跟AI共处,明天比今天更好。